Cloud-Agnostic AI Observability Platform - Architecture
Overview
This document describes the architecture of a cloud-agnostic AI observability platform built on AWS managed services. The platform provides unified monitoring, cost optimization, and operational insights for Large Language Model (LLM) workloads across multiple cloud providers.
Architecture Diagram
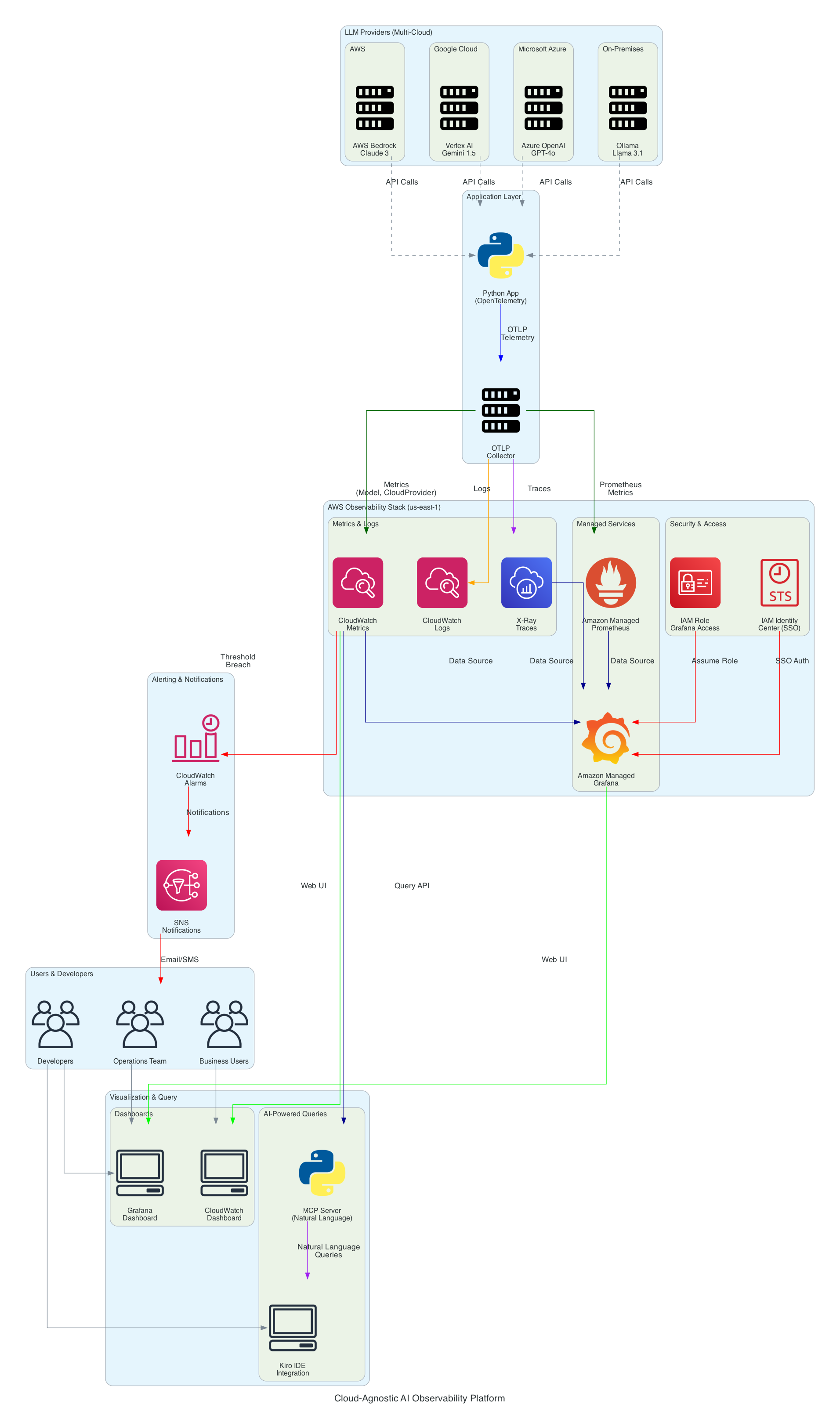
Architecture Components
1. LLM Providers Layer (Multi-Cloud)
The platform supports monitoring LLM invocations across multiple providers:
The models listed below are the ones used in this demo. Since the platform uses LiteLLM as the AI gateway, you can substitute any LLM supported by LiteLLM — simply update gateway/litellm-config.yaml with your preferred models. The observability pipeline works the same regardless of which models you choose.
AWS Bedrock
- Models: Claude 3 Haiku, Claude 3 Sonnet
- Integration: AWS SDK (boto3)
- Metrics: Token usage, latency, request counts
- Dimension:
CloudProvider=aws
Google Vertex AI
- Models: Gemini 1.5 Pro, Gemini 1.5 Flash
- Integration: Simulated (production would use Google Cloud SDK)
- Metrics: Token usage, latency, request counts
- Dimension:
CloudProvider=gcp
Azure OpenAI
- Models: GPT-4o, GPT-4o Mini
- Integration: Simulated (production would use Azure SDK)
- Metrics: Token usage, latency, request counts
- Dimension:
CloudProvider=azure
On-Premises (Ollama)
- Models: Llama 3.1 70B, Mistral 7B
- Integration: Simulated (production would use Ollama API)
- Metrics: Token usage, latency, request counts
- Dimension:
CloudProvider=on-prem
2. Application Layer
Python Application
- Framework: OpenTelemetry SDK for instrumentation
- Language: Python 3.8+
- Responsibilities:
- Invoke LLM APIs across providers
- Collect telemetry (metrics, traces, logs)
- Send data to OpenTelemetry Collector
OpenTelemetry Collector
- Protocol: OTLP (OpenTelemetry Protocol)
- Format: Cloud-agnostic, vendor-neutral
- Responsibilities:
- Receive telemetry from application
- Transform and enrich data
- Export to AWS services
3. AWS Observability Stack
Amazon CloudWatch
- Service Type: Managed metrics and monitoring
- Region: us-east-1
- Namespace:
AIObservability - Metrics:
InputTokens- Token count for promptsOutputTokens- Token count for completionsLatency- Response time in milliseconds
- Dimensions:
Model- LLM model identifierCloudProvider- Provider (aws, gcp, azure, on-prem)
- Retention: 15 months (default)
- Cost: $0.30 per metric per month (first 10,000 metrics free)
AWS X-Ray
- Service Type: Distributed tracing
- Region: us-east-1
- Responsibilities:
- Track request flow across services
- Identify performance bottlenecks
- Visualize service dependencies
- Trace Format: X-Ray segment documents
- Retention: 30 days
- Cost: $5.00 per 1 million traces recorded
CloudWatch Logs
- Service Type: Log aggregation and analysis
- Region: us-east-1
- Log Group:
/ai-observability-demo - Format: JSON structured logs
- Features:
- CloudWatch Logs Insights for querying
- Log retention policies
- Metric filters for alerting
- Retention: 7 days (configurable)
- Cost: $0.50 per GB ingested
Amazon Managed Prometheus (AMP)
- Service Type: Managed Prometheus-compatible monitoring
- Region: us-east-1
- Workspace ID:
<your-amp-workspace-id> - Use Case: Time-series metrics storage
- Query Language: PromQL
- Retention: 150 days
- Cost: $0.10 per million samples ingested
Amazon Managed Grafana (AMG)
- Service Type: Managed Grafana for visualization
- Region: us-east-1
- Workspace ID:
<your-amg-workspace-id> - Authentication: IAM Identity Center (SSO)
- Data Sources:
- Amazon CloudWatch
- AWS X-Ray
- Amazon Managed Prometheus
- Features:
- Dynamic dashboards with template variables
- Multi-cloud filtering
- Auto-refresh (30 seconds)
- Cost: $9.00 per active user per month
4. Security & Access Control
IAM Role (Grafana Access)
- Role Name:
ai-observability-grafana-role - Purpose: Allow Grafana to query AWS services
- Managed Policies:
CloudWatchReadOnlyAccessAWSXRayReadOnlyAccessAmazonPrometheusQueryAccess
- Trust Policy: Allows Grafana workspace to assume role
- Principle of Least Privilege: Read-only access only
IAM Identity Center (SSO)
- Region: us-east-2 (Ohio)
- Purpose: Single sign-on for Grafana users
- Users:
<your-email>(ADMIN role) - Integration: SAML 2.0 authentication
- Benefits:
- Centralized user management
- MFA support
- Audit logging
5. Visualization & Query Layer
Grafana Dashboard
- Type: Dynamic dashboard with template variables
- File:
grafana/dashboards/ai-observability-dynamic.json - Features:
- Cloud Provider dropdown (auto-discovers: aws, gcp, azure, on-prem)
- Model dropdown (auto-discovers all models)
- Multi-select filters
- Real-time metrics (30s refresh)
- Panels:
- Input Tokens by Model (time series)
- Output Tokens by Model (time series)
- Latency by Model (time series)
- Total Requests (stat)
- Average Latency (stat)
CloudWatch Dashboard
- Name:
AI-Observability-Demo - Type: Native CloudWatch dashboard
- Widgets:
- Input/Output token metrics
- Latency statistics
- Request counts
- Dimensions: Model and CloudProvider
- Access: AWS Console
MCP Server (Natural Language Queries)
- Technology: Model Context Protocol
- Language: Python 3.8+
- Integration: Kiro IDE
- Tools:
get_token_usage- Query token consumptionget_model_latency- Query latency statisticsget_request_count- Query request volumesget_cost_estimate- Estimate costscompare_models- Side-by-side comparison
- Query Examples:
- "Which model is consuming the most tokens?"
- "What's the average latency for Claude Haiku?"
- "Estimate my LLM costs for the last hour"
Kiro IDE Integration
- Purpose: Developer-centric observability
- Features:
- Natural language queries in IDE
- No context switching to dashboards
- Real-time metrics during development
- Configuration:
kiro-mcp-config.json
6. Alerting & Notifications
CloudWatch Alarms
- Purpose: Proactive monitoring and alerting
- Alarm Types:
- Cost threshold breaches
- Latency SLA violations
- Error rate increases
- Token usage anomalies
- Actions: Trigger SNS notifications
Amazon SNS
- Purpose: Multi-channel notifications
- Channels:
- SMS
- Slack (via webhook)
- PagerDuty integration
- Subscribers: Operations team
Data Flow
1. LLM Invocation Flow
User Request → Application → LLM Provider API
↓
OpenTelemetry SDK
↓
(Collect Telemetry)
↓
OTLP Collector
2. Telemetry Export Flow
OTLP Collector → CloudWatch (Metrics)
→ X-Ray (Traces)
→ CloudWatch Logs (Logs)
→ Prometheus (Time Series)
3. Visualization Flow
CloudWatch/X-Ray/Prometheus → Grafana → Users
→ CloudWatch Dashboard → Users
4. Query Flow (MCP)
Developer → Kiro IDE → MCP Server → CloudWatch API → Response
5. Alerting Flow
CloudWatch Metrics → Alarm Threshold → SNS → Operations Team
Key Design Decisions
1. Cloud-Agnostic Approach
Decision: Use OpenTelemetry as the instrumentation standard
Rationale:
- Vendor-neutral, open-source standard
- Works with any LLM provider
- Future-proof against provider changes
- Portable across cloud platforms
Trade-offs:
- Additional abstraction layer
- Requires OTLP collector setup
- Learning curve for OpenTelemetry
2. AWS Managed Services
Decision: Use Amazon Managed Grafana and Prometheus instead of self-hosted
Rationale:
- No infrastructure management overhead
- Built-in high availability and scalability
- Automatic patching and updates
- AWS-native security integration
- Pay-per-use pricing model
Trade-offs:
- Higher cost than self-hosted (for large scale)
- Less customization flexibility
- AWS region dependency
3. Dimensional Metrics
Decision: Use CloudWatch dimensions (Model, CloudProvider) instead of metric name prefixes
Rationale:
- Flexible querying and aggregation
- Efficient storage (no metric explosion)
- Supports dynamic filtering in Grafana
- Easy to add new dimensions
Trade-offs:
- CloudWatch dimension limits (30 per metric)
- Requires careful dimension design
- Query complexity increases
4. IAM Identity Center for SSO
Decision: Use IAM Identity Center instead of Grafana native authentication
Rationale:
- Centralized user management
- MFA support out of the box
- Audit logging for compliance
- Integration with corporate identity providers
Trade-offs:
- Additional AWS service dependency
- Setup complexity
- Regional constraints (us-east-2)
5. MCP for Natural Language Queries
Decision: Build custom MCP server instead of using existing query tools
Rationale:
- Developer-centric experience
- Reduces context switching
- Natural language interface
- IDE integration
Trade-offs:
- Custom code to maintain
- Limited to supported IDEs
- Requires MCP protocol knowledge
Scalability Considerations
Metrics Volume
Current Scale:
- 3 metrics per invocation (InputTokens, OutputTokens, Latency)
- 2 dimensions per metric (Model, CloudProvider)
- ~10 invocations per minute in demo
Production Scale Estimate:
- 1,000 invocations per second
- 180,000 metric data points per minute
- 259 million data points per day
CloudWatch Limits:
- 1,000 transactions per second (TPS) per account per region
- 150 TPS per API (PutMetricData)
- Solution: Use batching (up to 1,000 metrics per request)
Cost Optimization
Strategies:
- Metric Aggregation: Pre-aggregate metrics before sending to CloudWatch
- Sampling: Sample traces (e.g., 10% of requests) for high-volume workloads
- Retention Policies: Reduce log retention for non-critical logs
- Reserved Capacity: Use Savings Plans for predictable workloads
Estimated Monthly Cost (1M invocations/day):
- CloudWatch Metrics: ~$90
- CloudWatch Logs: ~$15
- X-Ray: ~$150
- Amazon Managed Grafana: $9 per user
- Amazon Managed Prometheus: ~$30
- Total: ~$300/month + $9 per user
High Availability
Built-in HA:
- CloudWatch: Multi-AZ by default
- X-Ray: Multi-AZ by default
- Amazon Managed Grafana: Multi-AZ deployment
- Amazon Managed Prometheus: Multi-AZ deployment
Application HA:
- Deploy application across multiple AZs
- Use Application Load Balancer for distribution
- Implement retry logic with exponential backoff
Security Best Practices
1. Least Privilege Access
- Grafana role has read-only access to AWS services
- No write permissions to CloudWatch, X-Ray, or Prometheus
- Separate roles for different user groups
2. Encryption
- At Rest: CloudWatch Logs encrypted with AWS KMS
- In Transit: TLS 1.2+ for all API calls
- Grafana: HTTPS only with valid SSL certificate
3. Network Security
- Grafana workspace in AWS-managed VPC
- No public internet access to backend services
- VPC endpoints for AWS service access (optional)
4. Audit Logging
- CloudTrail logs all API calls
- Grafana access logs in CloudWatch
- IAM Identity Center audit logs
5. Secrets Management
- AWS credentials via IAM roles (no hardcoded keys)
- LLM API keys in AWS Secrets Manager
- Automatic key rotation policies
Monitoring the Monitoring System
Meta-Monitoring
CloudWatch Metrics for Platform Health:
- Grafana workspace status
- Prometheus workspace status
- API call success rates
- Query latency
Alarms:
- Grafana workspace unavailable
- CloudWatch API throttling
- X-Ray trace ingestion failures
Disaster Recovery
Backup Strategy
CloudWatch:
- Metrics: Retained for 15 months (no backup needed)
- Logs: Export to S3 for long-term retention
- Dashboards: Version controlled in Git
Grafana:
- Dashboards: Exported as JSON, stored in Git
- Data sources: Configuration as code (Terraform)
- Users: Managed via IAM Identity Center
Recovery Time Objective (RTO): 1 hour Recovery Point Objective (RPO): 5 minutes
Disaster Recovery Plan
- Infrastructure: Redeploy via Terraform
- Dashboards: Import from Git repository
- Data: CloudWatch data persists (no action needed)
- Users: Reassign via IAM Identity Center
Future Enhancements
Short-Term (1-3 months)
- Anomaly Detection: ML-powered alerts for unusual patterns
- Cost Forecasting: Predict monthly costs based on trends
- SLO Tracking: Service Level Objective monitoring
- Multi-Region: Aggregate metrics across AWS regions
Medium-Term (3-6 months)
- Advanced Analytics: BigQuery/Athena integration
- Custom Dashboards: Team-specific views
- Integration Testing: Automated observability tests
- API Gateway: RESTful API for external integrations
Long-Term (6-12 months)
- AI-Powered Insights: Automated root cause analysis
- Predictive Scaling: Auto-adjust quotas based on forecasts
- Cost Optimization Engine: Automated model selection
- Compliance Automation: Automated audit reports
References
AWS Services Documentation
Standards & Protocols
Related Patterns
Document Version: 1.0
Last Updated: February 2026
Maintained By: AWS Solutions Architecture Team