Amazon Managed Grafana での Athena ��の使用
このレシピでは、Amazon Athena を Amazon Managed Grafana で使用する方法を説明します。 Amazon Athena は、標準 SQL を使用して Amazon S3 のデータを分析できるサーバーレスなインタラクティブクエリサービスです。 この統合は、Athena data source for Grafana によって実現されています。 これはオープンソースのプラグインで、任意の DIY Grafana インスタンスで使用できるほか、Amazon Managed Grafana にもプリインストールされています。
このガイドは約 20 分で完了します。
前提条件
インフラストラクチャ
まず、必要なインフラストラクチャをセットアップしましょう。
Amazon Athena のセットアップ
Athena を 2 つの異なるシナリオで使用する方法を見ていきます。1 つは Geomap プラグインを使用した地理データに関するシナリオ、もう 1 つは VPC フローログに関するセキュリティ関連のシナリオです。
まず、Athena がセットアップされ、データセットが読み込まれていることを確認しましょう。
これらのクエリを実行するには、Amazon Athena コンソールを使用する必要があります。Grafana は一般的にデータソースへの読み取り専用アクセスのみを持つため、データの作成や更新には使用できません。
地理データの読み込み
この最初のユースケースでは、Registry of Open Data on AWS のデータセットを使用します。 具体的には、地理データを使用したユースケースで Athena プラグインの使用方法を示すために、OpenStreetMap (OSM) を使用します。 これを実現するには、まず OSM データを Athena に取り込む必要があります。
まず、Athena で新しいデータベースを作成します。Athena コンソールに移動し、以下の 3 つの SQL クエリを使用して OSM データをデータベースにインポートします。
クエリ 1:
CREATE EXTERNAL TABLE planet (
id BIGINT,
type STRING,
tags MAP<STRING,STRING>,
lat DECIMAL(9,7),
lon DECIMAL(10,7),
nds ARRAY<STRUCT<ref: BIGINT>>,
members ARRAY<STRUCT<type: STRING, ref: BIGINT, role: STRING>>,
changeset BIGINT,
timestamp TIMESTAMP,
uid BIGINT,
user STRING,
version BIGINT
)
STORED AS ORCFILE
LOCATION 's3://osm-pds/planet/';
クエリ 2:
CREATE EXTERNAL TABLE planet_history (
id BIGINT,
type STRING,
tags MAP<STRING,STRING>,
lat DECIMAL(9,7),
lon DECIMAL(10,7),
nds ARRAY<STRUCT<ref: BIGINT>>,
members ARRAY<STRUCT<type: STRING, ref: BIGINT, role: STRING>>,
changeset BIGINT,
timestamp TIMESTAMP,
uid BIGINT,
user STRING,
version BIGINT,
visible BOOLEAN
)
STORED AS ORCFILE
LOCATION 's3://osm-pds/planet-history/';
クエリ 3:
CREATE EXTERNAL TABLE changesets (
id BIGINT,
tags MAP<STRING,STRING>,
created_at TIMESTAMP,
open BOOLEAN,
closed_at TIMESTAMP,
comments_count BIGINT,
min_lat DECIMAL(9,7),
max_lat DECIMAL(9,7),
min_lon DECIMAL(10,7),
max_lon DECIMAL(10,7),
num_changes BIGINT,
uid BIGINT,
user STRING
)
STORED AS ORCFILE
LOCATION 's3://osm-pds/changesets/';
VPC フローログデータの読み込み
2 番目のユースケースは、セキュリティに関連するものです。VPC Flow Logs を使用してネットワークトラフィックを分析します。
まず、EC2 に VPC フローログを生成するように指示する必要があります。 まだ設定していない場合は、VPC フローログを作成 してください。 ネットワークインターフェースレベル、サブネットレベル、または VPC レベルのいずれかで作成できます。
クエリのパフォーマンスを向上させ、ストレージの使用量を最小限に抑えるため、VPC フロー�ログはネストされたデータをサポートする列指向ストレージ形式である Parquet で保存します。
以下のように Parquet 形式で S3 バケットに公開する限り、どのオプション(ネットワークインターフェース、サブネット、または VPC)を選択しても構いません。

次に、Athena コンソール から、OSM データをインポートしたのと同じデータベースに VPC フローログデータのテーブルを作成します。 必要に応じて、新しいデータベースを作成することもできます。
以下の SQL クエリを使用し、VPC_FLOW_LOGS_LOCATION_IN_S3 を自分のバケット/フォルダに置き換えてください。
CREATE EXTERNAL TABLE vpclogs (
`version` int,
`account_id` string,
`interface_id` string,
`srcaddr` string,
`dstaddr` string,
`srcport` int,
`dstport` int,
`protocol` bigint,
`packets` bigint,
`bytes` bigint,
`start` bigint,
`end` bigint,
`action` string,
`log_status` string,
`vpc_id` string,
`subnet_id` string,
`instance_id` string,
`tcp_flags` int,
`type` string,
`pkt_srcaddr` string,
`pkt_dstaddr` string,
`region` string,
`az_id` string,
`sublocation_type` string,
`sublocation_id` string,
`pkt_src_aws_service` string,
`pkt_dst_aws_service` string,
`flow_direction` string,
`traffic_path` int
)
STORED AS PARQUET
LOCATION 'VPC_FLOW_LOGS_LOCATION_IN_S3'
例えば、S3 バケット allmyflowlogs を使用している場合、VPC_FLOW_LOGS_LOCATION_IN_S3 は以下のようになります。
s3://allmyflowlogs/AWSLogs/12345678901/vpcflowlogs/eu-west-1/2021/
これでデータセットが Athena で利用可能になりました。 次は Grafana に進みましょう。
Grafana のセットアップ
Grafana インスタンスが必要なので、Getting Started ガイドを使用するなどして、新しい Amazon Managed Grafana ワークスペース をセットアップするか、既存のものを使用してください。
AWS データソース設定を使用するには、まず Amazon Managed Grafana コンソールに移動し、ワークスペースに Athena リソースを読み取るために必要な IAM ポリシーを付与するサービスマネージド IAM ロールを有効にする必要があります。 さらに、以下の点に注意してください:
- 使用予定の Athena ワークグループには、サービスマネージドの権限でワークグループを使用できるようにするため、キー
GrafanaDataSourceと値trueのタグを付ける必要があります。 - サービスマネージド IAM ポリシーは、
grafana-athena-query-results-で始まるクエリ結果バケットへのアクセスのみを許可します。その他のバケットについては、手動で権限を追加する必要があります。 - クエリ対象の基となるデータソースに対して、
s3:Get*およびs3:List*権限を手動で追加する必要があります。
Athena データソースをセットアップするには、左側のツールバーを使用して、下部の AWS アイコンを選択し、「Athena」を選択します。 プラグインが使用する Athena データソースを検出するためのデフォルトリージョンを選択し、使用するアカウントを選択して、最後に「Add data source」を選択します。
または、以下の手順に従って Athena データソースを手動で追加および設定することもできます:
- 左側のツールバーの「Configurations」アイコンをクリックし、「Add data source」をクリックします。
- 「Athena」を検索します。
- [オプション] 認証プロバイダーを設定します(推奨:ワークスペース IAM ロール)。
- 対象の Athena データソース、データベース、ワークグループを選択します。
- ワークグループに出力場所がまだ設定されていない場合は、クエリ結果に使用する S3 バケットとフォルダを指定します。サービスマネージドポリシーを利用するには、バケット名が
grafana-athena-query-results-で始まる必要があることに注意してください。 - 「Save & test」をクリックします。
以下のような画面が表示されるはずです:
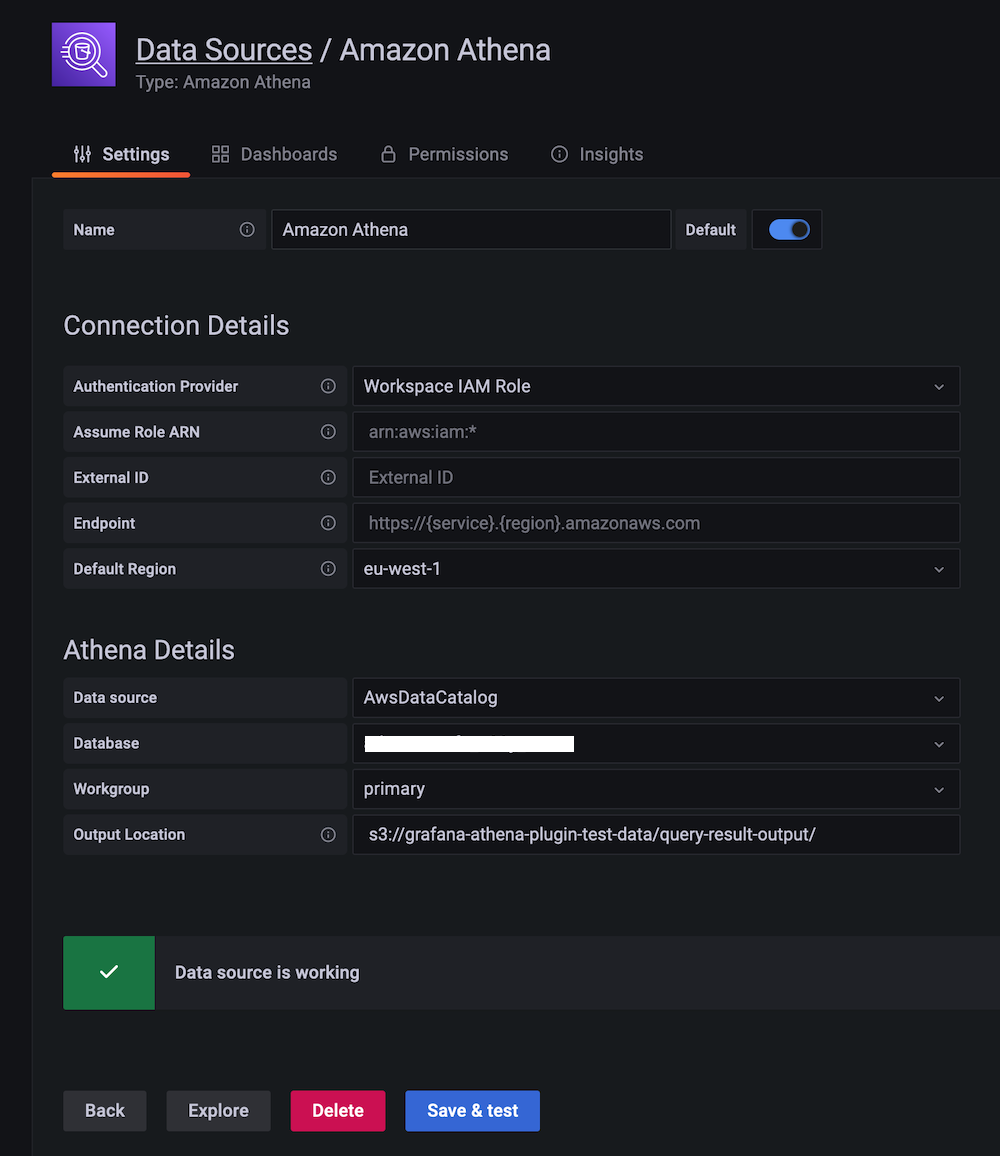
使用方法
それでは、Grafana から Athena のデータセットを使用する方法を見ていきましょう。
地理データの使用
OpenStreetMap (OSM) のデータを Athena で使用することで、「特定の施設がどこにあるか」といった様々な質問に答えることができます。 実際に見てみましょう。
例えば、Las Vegas 地域で食事を提供する場所を一覧表示するために、OSM データセットに対して以下の SQL クエリを実行します:
SELECT
tags['amenity'] AS amenity,
tags['name'] AS name,
tags['website'] AS website,
lat, lon
FROM planet
WHERE type = 'node'
AND tags['amenity'] IN ('bar', 'pub', 'fast_food', 'restaurant')
AND lon BETWEEN -115.5 AND -114.5
AND lat BETWEEN 36.1 AND 36.3
LIMIT 500;
上記のクエリで定義されている Las Vegas 地域は、緯度が 36.1 から 36.3 の間、経度が -115.5 から -114.5 の間にある全ての場所です。
これらの値を変数化(各角に対して1つずつ)することで、Geomap プラグインを他の地域にも適用できるようになります。
上記のクエリを使用して OSM データを可視化するために、osm-sample-dashboard.json で提供されているサンプルダッシュボードをインポートできます。 以下のように表示されます:
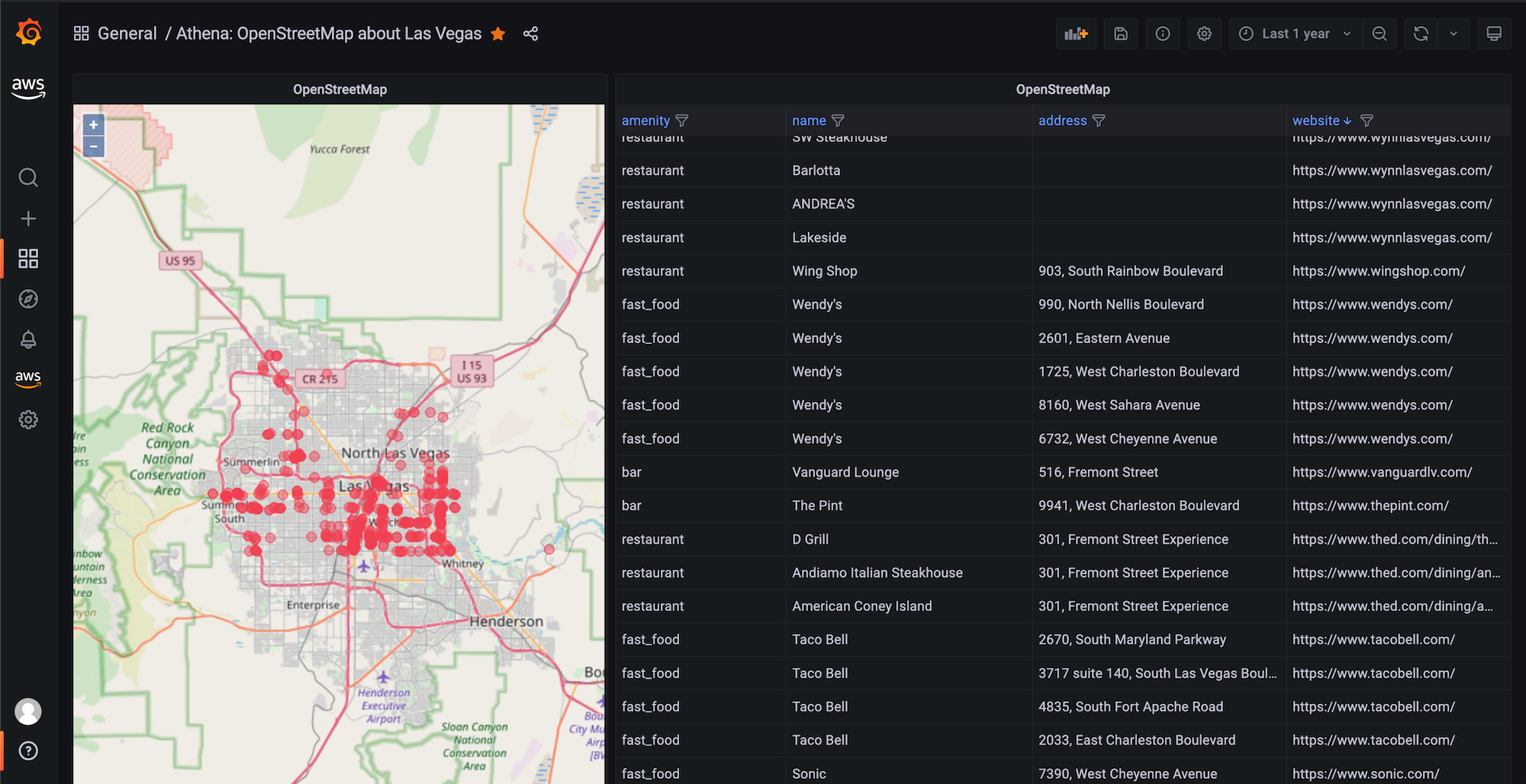
上記のスクリーンショットでは、データポイントをプロットするために Geomap 可視化(左パネル)を使用しています。
VPC フローログデータの使用
VPC フローログデータを分析し、SSH および RDP トラフィックを検出するには、以下の SQL クエリを使用します。
SSH/RDP トラフィックの表形式の概要を取得する場合:
SELECT
srcaddr, dstaddr, account_id, action, protocol, bytes, log_status
FROM vpclogs
WHERE
srcport in (22, 3389)
OR
dstport IN (22, 3389)
ORDER BY start ASC;
許可および拒否されたバイト数の時系列ビューを取得する場合:
SELECT
from_unixtime(start), sum(bytes), action
FROM vpclogs
WHERE
srcport in (22,3389)
OR
dstport IN (22, 3389)
GROUP BY start, action
ORDER BY start ASC;
Athena でクエリするデータ量を制限したい場合は、$__timeFilter マクロの使用を検討してください。
VPC フローログデータを可視化するために、vpcfl-sample-dashboard.json で提供されているサンプルダッシュボードをインポートできます。 以下のようなダッシュボードが表示されます:
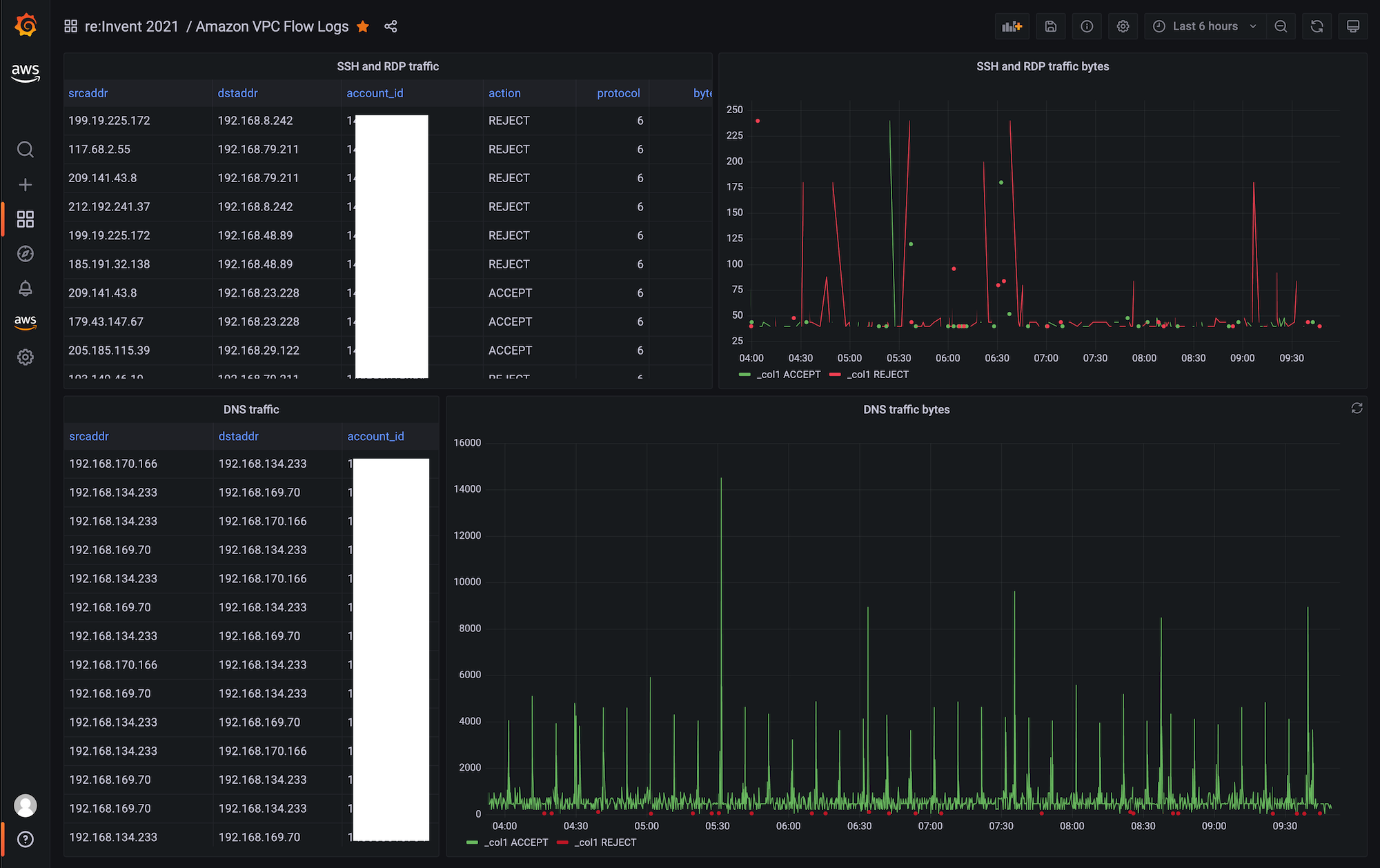
ここから、以下のガイドを参照して Amazon Managed Grafana で独自のダッシュボードを作成できます:
以上です。おめでとうございます!Grafana から Athena を使用する方法を学習しました!
クリーンアップ
使用していた Athena データベースから OSM データを削除し、コンソールから Amazon Managed Grafana ワークスペースを削除します。