로깅
로깅 도구의 선택은 데이터 전송, 필터링, 보존, 캡처 및 데이터를 생성하는 애플리케이션과의 통합에 대한 요구 사항과 관련이 있습니다. Observability를 위해 Amazon Web Services를 사용할 때(온프레미스 또는 다른 클라우드 환경에서 호스팅하는 경우에도), CloudWatch agent 또는 Fluentd와 같은 다른 도구를 활용하여 분석을 위한 로깅 데이터를 전송할 수 있습니다.
여기서는 로깅을 위한 CloudWatch agent 구현과 AWS 콘솔 또는 API 내에서의 CloudWatch Logs 사용에 대한 모범 사례를 확장하여 설명합니다.
CloudWatch agent를 사용한 로그 수집
전달
Observability에 클라우드 우선 접근 방식을 취할 때, 원칙적으로 로그를 얻기 위해 머신에 로그인해야 한다면 안티패턴이 있는 것입니다. 워크로드는 거의 실시간으로 로그 분석 시스템 외부로 로깅 데이터를 전송해야 하며, 전송과 원래 이벤트 사이의 지연은 워크로드에 재해가 발생할 경우 시점 정보의 잠재적 손실을 나타냅니다.
아키텍트로서 로깅 데이터의 허용 가능한 손실을 결정하고 이를 수용하기 위해 CloudWatch agent의 force_flush_interval을 조정해야 합니다.
force_flush_interval은 버퍼 크기에 도달하지 않는 한 agent가 정기적인 주기로 데이터 플레인에 로깅 데이터를 전송하도록 지시하며, 버퍼 크기에 도달하면 버퍼링된 모든 로그를 즉시 전송합니다.
엣지 디바이스는 저지연 AWS 내 워크로드와 매우 다른 요구 사항을 가질 수 있으며, 훨씬 더 긴 force_flush_interval 설정이 필요할 수 있습니다. 예를 들어, 저대역폭 인터넷 연결의 IoT 디바이스는 15분마다만 로그를 플러시하면 될 수 있습니다.
컨테이너화된 또는 상태 비저장 워크로드는 로그 플러시 요구 사항에 특히 민감할 수 있습니다. 언제든지 스케일인될 수 있는 상태 비저장 Kubernetes 애플리케이션이나 EC2 Fleet을 생각해 보세요. 이러한 리소스가 갑자기 종료되면 로그 손실이 발생할 수 있으며, 이후에는 해당 리소스에서 로그를 추출할 방법이 없습니다. 이러한 시나리오에서는 표준 force_flush_interval이 일반적으로 적절하지만, 필요한 경우 줄일 수 있습니다.
로그 그룹
CloudWatch Logs 내에서, 논리적으로 애플리케이션에 적용되는 각 로그 컬렉션은 단일 로그 그룹으로 전달되어야 합니다. 해당 로그 그룹 내에서 로그 스트림을 생성하는 소스 시스템 간에 공통성을 갖고 있어야 합니다.
LAMP 스택을 고려해 보세요: Apache, MySQL, PHP 애플리케이션 및 호스팅 Linux 운영 체제의 로그는 각각 별도의 로그 그룹에 속해야 합니다.
이 그룹화는 그룹을 동일한 보존 기간, 암호화 키, 메트릭 필터, 구독 필터 및 Contributor Insights 규칙으로 처리할 수 있게 해주므로 매우 중요합니다.
로그 그룹의 로그 스트림 수에는 제한이 없으며, 단일 CloudWatch Logs Insights 쿼리에서 애플리케이션의 전체 로그를 검색할 수 있습니다. Kubernetes 서비스의 각 파드 또는 Fleet의 각 EC2 인스턴스에 대한 별도의 로그 스트림을 갖는 것은 표준 패턴입니다.
로그 그룹의 기본 보존 기간은 무기한입니다. 모범 사례는 로그 그룹 생성 시 보존 기간을 설정하는 것입니다.
CloudWatch 콘솔에서 언제든지 이를 설정할 수 있지만, 모범 사례는 Infrastructure as Code(CloudFormation, Cloud Development Kit 등)를 사용하여 로그 그룹 생성과 동시에 설정하거나, CloudWatch agent 구성 내의 retention_in_days 설정을 사용하는 것입니다.
두 접근 방식 모두 로그 보존 기간을 사전에 프로젝트의 데이터 보존 요구 사항에 맞게 설정할 수 있습니다.
로그 그룹 데이터는 CloudWatch Logs에서 항상 암호화됩니다. 기본적으로 CloudWatch Logs는 저장 중인 로그 데이터에 server-side 암호화를 사용합니다. 대안으로 이 암호화에 AWS Key Management Service를 사용할 수 있습니다. AWS KMS를 사용한 암호화는 로그 그룹 수준에서 KMS 키를 로그 그룹에 연결하여 활성화되며, 로그 그룹 생성 시 또는 이후에 설정할 수 있습니다. Infrastructure as Code(CloudFormation, Cloud Development Kit 등)를 사용하여 구성할 수 있습니다.
CloudWatch Logs의 키 관리에 AWS Key Management Service를 사용하려면 추가 구성과 사용자에 대한 키 권한 부여가 필요합니다.1
로그 형식
CloudWatch Logs는 수집 시 로그 필드를 자동으로 발견하고 JSON 데이터를 인덱싱하는 기능을 가지고 있습니다. 이 기능은 임시 쿼리와 필터링을 용이하게 하여 로그 데이터의 사용성을 향상시킵니다. 그러나 자동 인덱싱은 구조화된 데이터에만 적용된다는 점에 유의해야 합니다. 비구조화된 로깅 데이터는 자동으로 인덱싱되지 않지만 여전히 CloudWatch Logs로 전달할 수 있습니다.
비구조화된 로그는 parse 명령어와 함께 정규 표현식을 사용하여 검색하거나 쿼리할 수 있습니다.
CloudWatch Logs 사용 시 로그 형식에 대한 두 가지 모범 사례:
- Log4j,
python-json-logger또는 프레임워크의 네이티브 JSON 이미터와 같은 구조화된 로그 포맷터를 사용하세요. - 이벤트당 한 줄의 로깅을 로그 대상으로 전송하세요.
여러 줄의 JSON 로깅을 전송할 때 각 줄은 단일 이벤트로 해석됩니다.
stdout 처리
로그 시그널 페이지에서 논의한 대로, 모범 사례는 로깅 시스템을 생성 애플리케이션에서 분리하는 것입니다. 그러나 stdout에서 파일로 데이터를 전송하는 것은 많은(대부분은 아닐지라도) 플랫폼에서 일반적인 패턴입니다. Kubernetes 또는 Amazon Elastic Container Service와 같은 컨테이너 오케스트레이션 시스템은 stdout에서 로그 파일로의 전달을 자동으로 관리하여 컬렉터에서 각 로그를 수집할 수 있게 합니다. 그런 다음 CloudWatch agent가 이 파일을 실시간으로 읽어 데이터를 로그 그룹으로 전달합니다.
가능한 한 stdout으로의 간소화된 애플리케이션 로깅과 agent에 의한 수집 패턴을 사용하세요.
로그 필터링
개인정보의 영구 저장을 막거나 특정 로그 레벨만 수집하는 등, 로그를 필터링해야 하는 이유는 다양합니다. 이때 가장 좋은 방법은 원본 시스템에서 가능한 한 빨리 필터링하는 것입니다. CloudWatch 환경에서는 CloudWatch Logs로 전달되기 전에 CloudWatch agent에서 필터링을 처리하세요.
filters 기능을 사용하여 원하는 로그 레벨을 include하고, 바람직하지 않은 것으로 알려진 패턴(예: 신용카드 번호, 전화번호 등)을 exclude하세요.
로그에 잠재적으로 유출될 수 있는 특정 형태의 알려진 데이터를 필터링하는 것은 시간이 많이 걸리고 오류가 발생하기 쉬울 수 있습니다. 그러나 특정 유형의 바람직하지 않은 데이터(예: 신용카드 번호, 사회보장번호)를 처리하는 워크로드의 경우, 이러한 레코드에 대한 필터를 갖추면 향후 잠재적으로 피해가 큰 규정 준수 문제를 방지할 수 있습니다. 예를 들어, 사회보장번호를 포함하는 모든 레코드를 삭제하는 것은 다음 구성처럼 간단할 수 있습니다:
"filters": [
{
"type": "exclude",
"expression": "\\b(?!000|666|9\\d{2})([0-8]\\d{2}|7([0-6]\\d))([-]?|\\s{1})(?!00)\\d\\d\\2(?!0000)\\d{4}\\b"
}
]
멀티라인 로깅
모든 로깅에 대한 모범 사례는 각 개별 로그 이벤트에 대해 한 줄을 전송하는 구조화된 로깅을 사용하는 것입니다. 그러나 이 옵션이 없는 많은 레거시 및 ISV 지원 애플리케이션이 있습니다. 이러한 워크로드의 경우, CloudWatch Logs는 멀티라인 인식 프로토콜을 사용하여 전송하지 않는 한 각 줄을 고유한 이벤트로 해석합니다. CloudWatch agent는 multi_line_start_pattern 지시문으로 이를 수행할 수 있습니다.
multi_line_start_pattern 지시문을 사용하여 CloudWatch Logs에 멀티라인 로깅을 수집하는 부담을 줄이세요.
로깅 클래스 구성
CloudWatch Logs는 두 가지 로그 그룹 클래스를 제공합니다:
-
CloudWatch Logs Standard 로그 클래스는 실시간 모니터링이 필요하거나 자주 액세스하는 로그를 위한 전체 기능 옵션입니다.
-
CloudWatch Logs Infrequent Access 로그 클래스는 로그를 비용 효율적으로 통합할 수 있는 새로운 로그 클래스입니다. 이 로그 클래스는 관리형 수집, 저장, 교차 계정 로그 분석 및 암호화를 포함한 CloudWatch Logs 기능의 하위 집합을 GB당 더 낮은 수집 가격으로 제공합니다. Infrequent Access 로그 클래스는 자주 액세스하지 않는 로그에 대한 임시 쿼리 및 사후 포렌식 분석에 이상적입니다.
log_group_class 지시문을 사용��하여 새 로그 그룹에 사용할 로그 그룹 클래스를 지정하세요. 유효한 값은 STANDARD와 INFREQUENT_ACCESS입니다. 이 필드를 생략하면 agent에서 기본값인 STANDARD가 사용됩니다.
적절한 클래스 지정을 위한 기존 로그 감사
CloudWatch logs Infrequent Access 계층 로그 클래스는 CloudWatch 로깅 기능의 하위 집합을 활용합니다. 기존 로그 그룹을 감사하여 Standard 로그 그룹 중 Infrequent Access 로그 그룹으로 재생성할 수 있는 것이 있는지 확인하는 것이 좋습니다. 이를 수행하는 좋은 방법은 log-ia-checker CLI 도구를 실행하는 것입니다. 이 도구는 지정된 리전의 모든 로그 그룹을 분석하고 Infrequent Access로 전환할 수 있는 로그의 출력을 제공합니다.
CloudWatch Logs를 사용한 검색
쿼리 범위 조정을 통한 비용 관리
CloudWatch Logs에 데이터가 전달되면 필요에 따라 검색할 수 있습니다. CloudWatch Logs는 스캔된 데이터 기가바이트당 요금을 부과합니다. 쿼리 범위를 제어하는 전략이 있으며, 이는 스캔되는 데이터를 줄이는 결과를 가져옵니다.
로그를 검색할 때 시간 및 날짜 범위가 적절한지 확인하세요. CloudWatch Logs에서는 스캔에 대해 상대적 또는 절대적 시간 범위를 설정할 수 있습니다. 전날의 항목만 찾고 있다면, 오늘의 로그를 스캔에 포함할 필요가 없습니다!
단일 쿼리에서 여러 로그 그룹을 검색할 수 있지만, 이렇게 하면 더 많은 데이터가 스캔됩니다. 타깃으로 해야 할 로그 그룹을 식별한 후, 쿼리 범위를 이에 맞게 줄이세요.
CloudWatch 콘솔에서 직접 각 쿼리가 실제로 스캔하는 데이터 양을 확인할 수 있습니다. 이 접근 방식은 효율적인 쿼리를 만드는 데 도움이 됩니다.
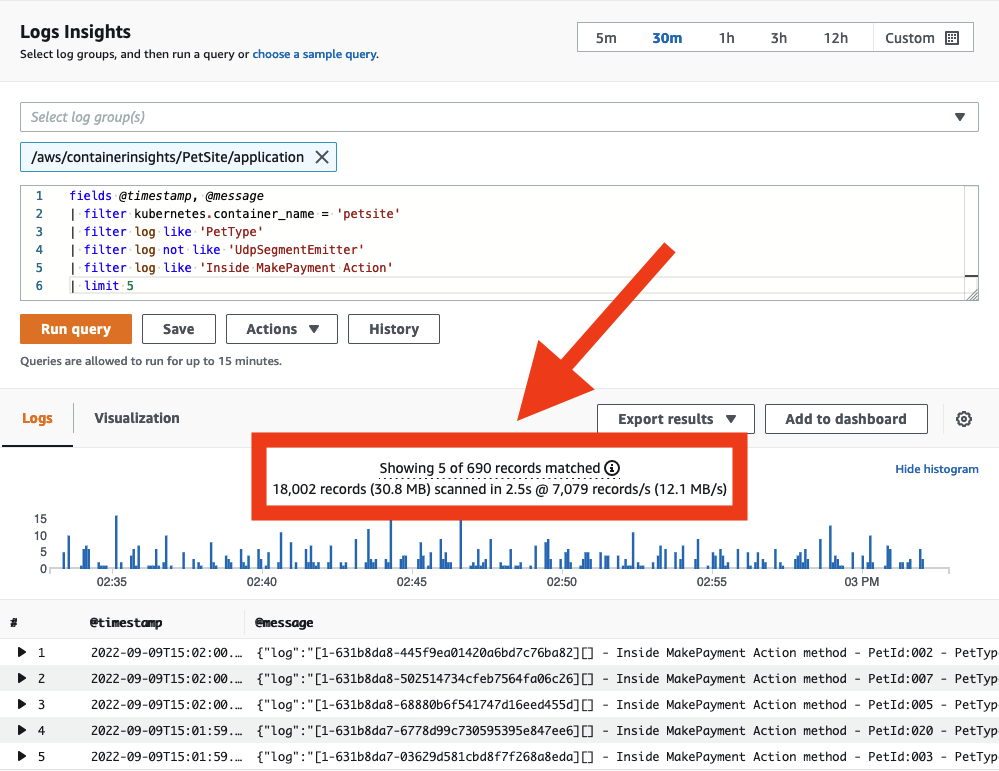
성공적인 쿼리를 다른 사람과 공유
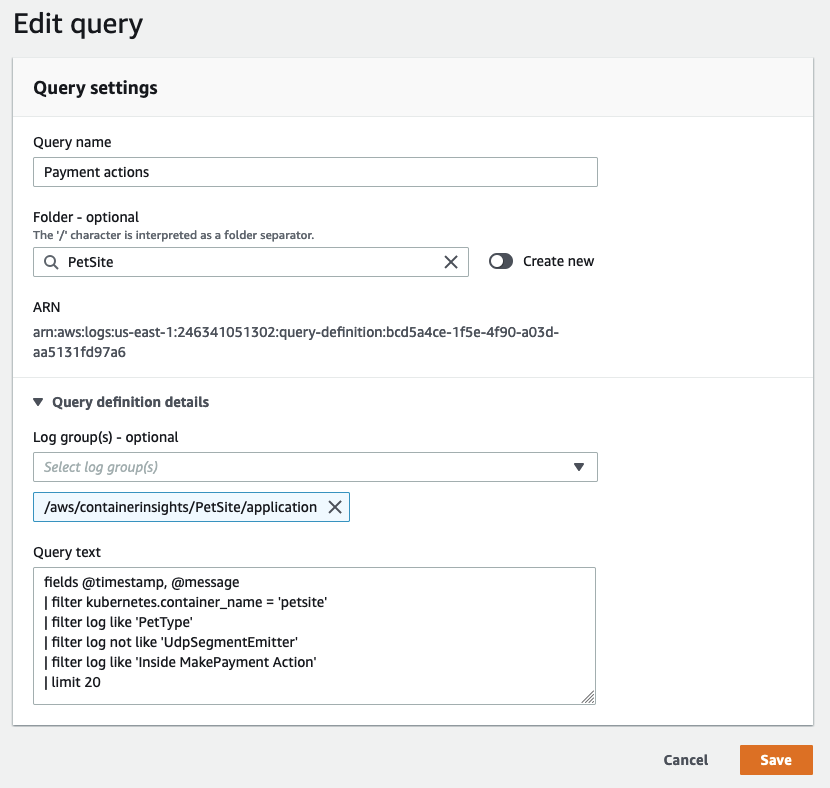
CloudWatch Logs 쿼리 구문은 복잡하지 않지만, 특정 쿼리를 처음부터 작성하는 것은 여전히 시간이 많이 걸릴 수 있습니다. 동일한 AWS 계정 내의 다른 사용자와 잘 작성된 쿼리를 공유하면 애플리케이션 로그 조사를 간소화할 수 있습니다. 이것은 AWS Management Console에서 직접 또는 CloudFormation이나 AWS CDK를 사용하여 프로그래밍 방식으로 수행할 수 있습니다. 이렇게 하면 로그 데이터를 분석해야 하는 다른 사람들의 재작업이 줄어듭니다.
자주 반복되는 쿼리를 CloudWatch Logs에 저장하여 사용자들이 미리 채워진 상태로 사용할 수 있게 하세요.
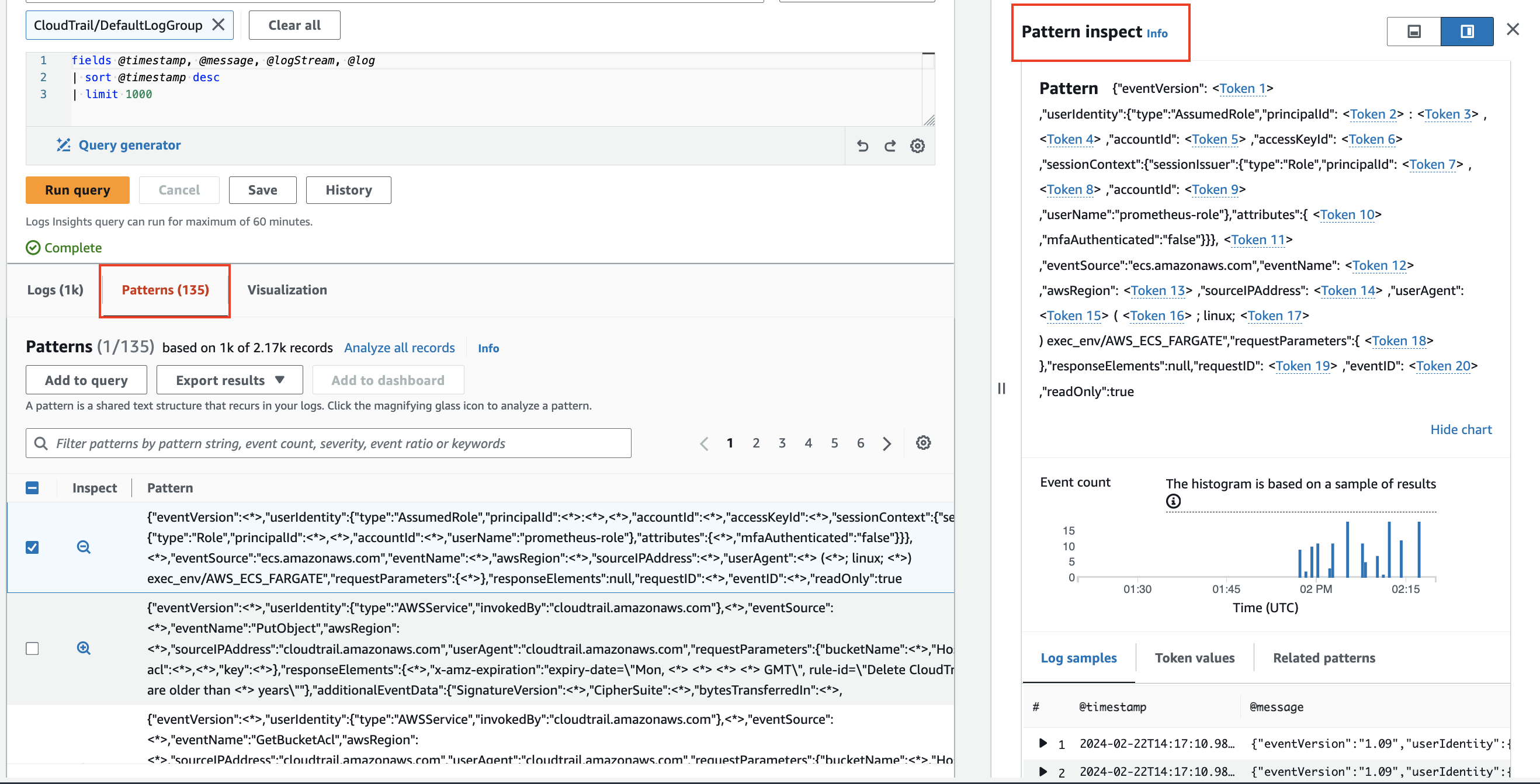
패턴 분석
CloudWatch Logs Insights는 로그를 쿼리할 때 머신 러닝 알고리즘을 사용하여 패턴을 찾습니다. 패턴은 로그 필드 간에 반복되는 공유 텍스트 구조입니다. 패턴은 대규모 로그 세트를 분석하는 데 유용하며, 많은 수의 로그 이벤트를 몇 가지 패턴으로 압축할 수 있습니다.2
pattern을 사용하여 로그 데이터를 자동으로 패턴으로 클러스터링하세요.
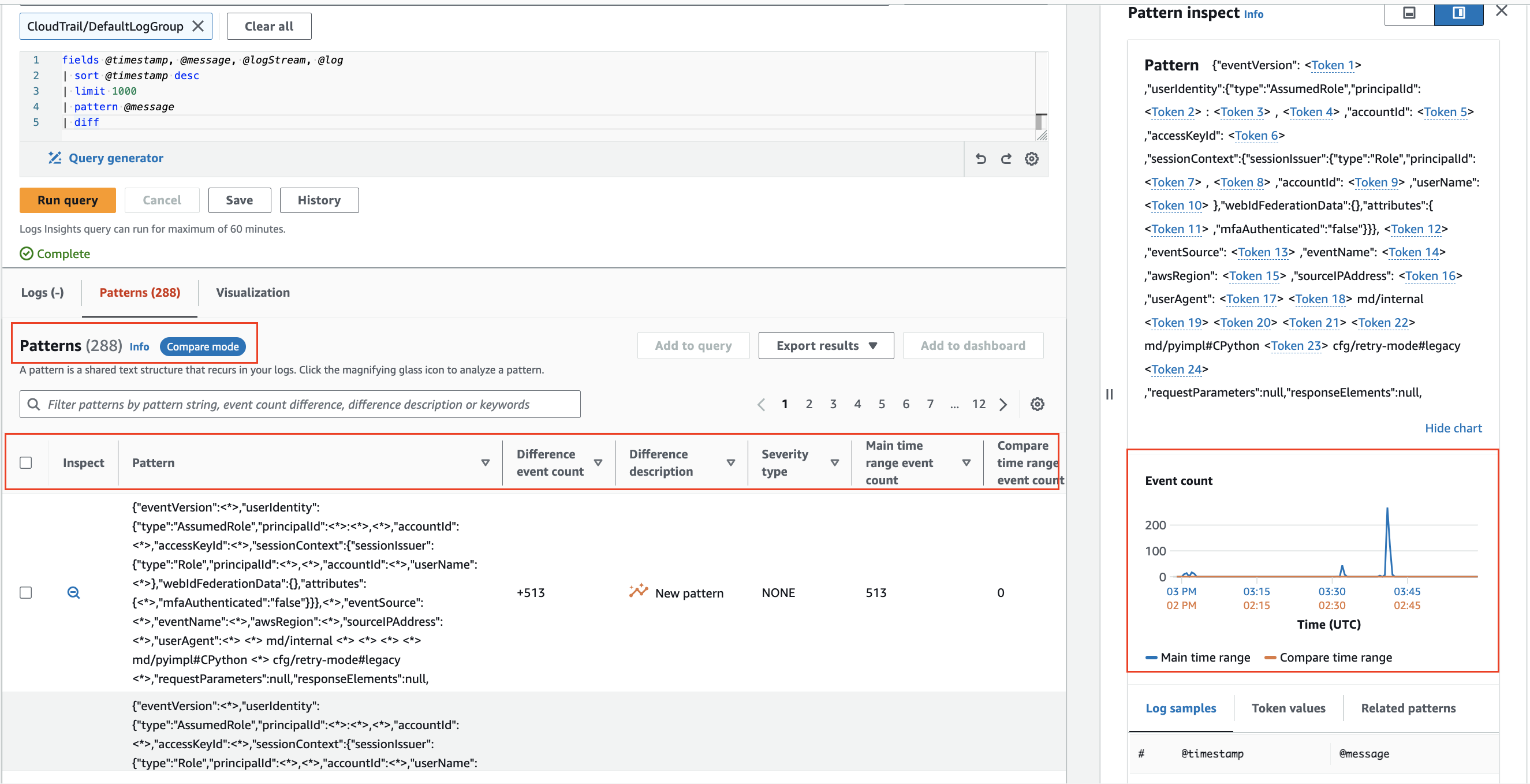
이전 시간 범위와 비교(diff)
CloudWatch Logs Insights는 시간에 따른 로그 이벤트 변경 사항을 비교하여 오류 감지 및 추세 식별에 도움을 줍니다. 비교 쿼리는 패턴을 드러내어 빠른 추세 분석을 가능하게 하며, 더 깊은 조사를 위해 샘플 원시 로그 이벤트를 검토할 수 있습니다. 쿼리는 두 기간에 대해 분석됩니다: 선택한 기간과 동일 길이의 비교 기간.3
diff 명령어를 사용하여 시간에 따른 로그 이벤트의 변경 사항을 비교하세요.
Footnotes
-
CloudWatch Logs 로그 그룹 암호화와 액세스 권한에 대한 실용적인 예시는 How to search through your AWS Systems Manager Session Manager console logs – Part 1을 참조하세요. ↩
-
더 자세한 인사이트는 CloudWatch Logs Insights Pattern Analysis를 참조하세요. ↩
-
자세한 정보는 CloudWatch Logs Insights Compare(diff) with previous ranges를 참조하세요. ↩