Logs
Logs는 애플리케이션이나 장비에서 전송하는 일련의 메시지로, 이벤트 또는 해당 애플리케이션의 상태에 대한 하나 이상의 세부 정보를 나타냅니다. 일반적으로 logs는 파일에 기록되지만, 때로는 분석 및 집계를 수행하는 collector로 전송되기도 합니다. MB/day부터 TB/hour까지 다양한 볼륨의 log 데이터를 생성, 수집 및 관리하는 작업을 수행하기 위한 많은 완전한 기능을 갖춘 log aggregator, framework, 제품이 있습니다.
Logs는 한 번에 단일 애플리케이션에 의해 생성되며 일반적으로 해당 단일 애플리케이션의 범위에 관련됩니다. 물론 개발자는 원하는 만큼 복잡하고 세밀한 logs를 작성할 수 있습니다. 이 문서에서는 logs를 traces와 근본적으로 다른 signal로 간주합니다. Traces는 둘 이상의 애플리케이션 또는 서비스에서 발생하는 이벤트로 구성되며, 응답 지연 시간, 서비스 장애, 요청 매개변수 등 서비스 간 연결에 대한 context를 포함합니다.
Logs의 데이터는 일정 기간 동안 집계될 수도 있습니다. 예를 들어, 통계적 데이터(예: 이전 1분 동안 처리된 요청 수)일 수 있습니다. 구조화되거나, 자유 형식이거나, 상세하거나, 모든 언어로 작성될 수 있습니다.
로깅의 주요 사용 사례는 다음을 설명하는 것입니다:
- 이벤트의 상태, 지속 시간 및 기타 핵심 통계를 포함한 이벤트 설명
- 해당 이벤트와 관련된 오류 또는 경고(예: stack traces, timeouts)
- 애플리케이션 시작, 기동 및 종료 메시지
Logs는 변경 불가하도록 설계되어 있으며, 많은 log 관리 시스템에는 log 데이터의 수정 시도를 방지하고 탐지하는 메커니즘이 포함되어 있습니다.
로깅에 대한 요구 사항에 관계없이, 다음은 우리가 확인한 모범 사례입니다.
구조화된 로깅이 성공의 열쇠
많은 시스템이 반구조화된 형식으로 logs를 출력합니다. 예를 들어, Apache 웹 서버는 각 줄이 단일 웹 요청에 해당하는 다음과 같은 logs를 작성할 수 있습니다:
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395 127.0.0.1 - - [28/Jul/2006:10:22:04 -0300] "GET / HTTP/1.0" 200 2216
반면 Java stack trace는 여러 줄에 걸쳐 있고 덜 구조화된 단일 이벤트일 수 있습니다:
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
그리고 Python 오류 log 이벤트는 다음과 같이 보일 수 있습니다:
Traceback (most recent call last):
File "e.py", line 7, in <module>
raise TypeError("Again !?!")
TypeError: Again !?!
이 세 가지 예시 중 첫 번째만 사람 그리고 log 집계 시스템에서 쉽게 파싱할 수 있습니다. 구조화된 logs를 사용하면 log 데이터를 빠르고 효과적으로 처리할 수 있어, 사람과 기계 모두가 찾고 있는 것을 즉시 찾는 데 필요한 데이터를 제공합니다.
가장 일반적으로 이해되는 log 형식은 JSON이며, 이벤트의 각 구성 요소가 key/value 쌍으로 표현됩니다. JSON에서 위의 Python 예시는 다음과 같이 다시 작성할 수 있습니다:
{
"level", "ERROR"
"file": "e.py",
"line": 7,
"error": "TypeError(\"Again !?!\")"
}
구조화된 logs를 사용하면 데이터를 한 log 시스템에서 다른 시스템으로 쉽게 이동할 수 있고, 개발을 단순화하며, 운영 진단을 더 빠르게(오류를 줄이면서) 수행할 수 있습니다. 또한 JSON을 사용하면 log 메시지의 schema가 실제 데이터와 함께 포함되므로, 정교한 log 분석 시스템이 메시지를 자동으로 인덱싱할 수 있습니다.
Log level을 적절하게 사용하기
로그는 크게 두 가지로 나뉩니다. 심각도(Level)를 가진 로그와, 이벤트의 흐름을 기록하는 로그입니다.
| Level | 설명 |
|---|---|
DEBUG | 애플리케이션을 디버깅하는 데 가장 유용한 세분화된 정보 이벤트입니다. 일반적으로 개발자에게 유용하며 매우 상세합니다. |
INFO | 애플리케이션의 진행 상황을 대략적인 수준에서 보여주는 정보 메시지입니다. |
WARN | 애플리케이션에 위험을 나타내는 잠재적으로 유해한 상황입니다. 애플리케이션에서 alarm을 트리거할 수 있습니다. |
ERROR | 애플리케이션이 계속 실행될 수 있지만 오류가 발생한 이벤트입니다. 주의가 필요한 alarm을 트리거할 가능성이 높습니다. |
FATAL | 애플리케이션을 중단시킬 것으로 예상되는 매우 심각한 오류 이벤트입니다. |
명시적인 level이 없는 logs는 암묵적으로 INFO로 간주될 수 있지만, 이 동작은 애플리케이션마다 다를 수 있습니다.
프로그래밍 언어와 framework에 따라 CRITICAL과 NONE도 일반적인 log level입니다. ALL과 NONE도 일반적이지만 모든 애플리케이션 스택에서 사용되지는 않습니다.
Log level은 환경의 상태를 모니터링 및 Observability 솔루션에 알리는 데 매우 중요하며, log 데이터는 논리적인 값을 사용하여 이 정보를 쉽게 표현해야 합니다.
WARN에서 너무 많은 데이터를 로깅하면 모니터링 시스템이 가치가 제한된 데이터로 가득 차게 되고, 방대한 메시지 볼륨 속에서 중요한 데이터를 놓칠 수 있습니다.
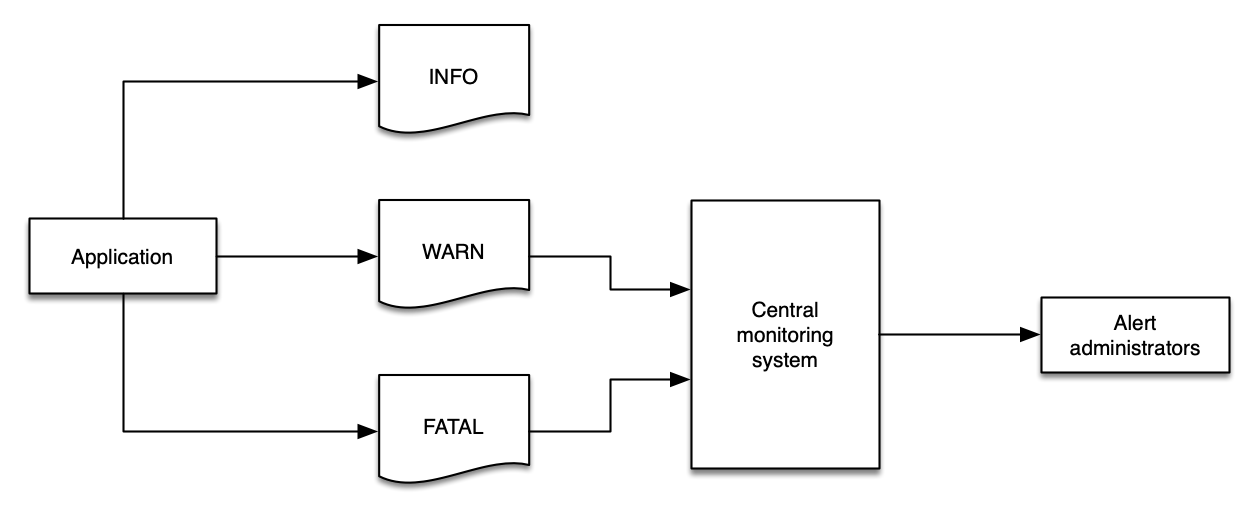
표준화된 log level 전략을 사용하면 자동화가 쉬워지고, 개발자가 문제의 근본 원인에 빠르게 도달하는 데 도움이 됩니다.
Log level에 대한 표준 접근 방식이 없으면 log filtering이 큰 과제가 됩니다.
로그는 생성되는 곳에서 먼저 필터링
로그는 가능한 한 생성 시점에 가까운 곳에서 볼륨을 줄이세요. 중앙 저장소까지 모든 로그를 보낸 뒤에 정리하는 것이 아니라, 만들어지는 단계에서 불필요한 로그를 먼저 걸러내야 합니다. 이 모범 사례를 따라야 하는 이유는 다음과 같습니다:
- 로그를 수집하는 데는 항상 시간, 비용, 리소스가 소요됩니다.
- 민감한 데이터(예: 개인 식별 정보)가 다운스트림 시스템으로 흘러가기 전에 필터링하면, 데이터 유출로 인한 위험 노출을 줄일 수 있습니다.
- 다운스트림 시스템은 데이터 소스와 동일한 관심사를 갖지 않을 수 있습니다. 예를 들어, 애플리케이션의
INFO로그는CRITICAL또는FATAL메시지만 감시하는 모니터링 및 알림 시스템에는 불필요한 노이즈일 뿐입니다. - 로그 시스템과 네트워크에 불필요한 부하와 트래픽을 유발하지 않아야 합니다.
로그를 생성 시점에서 바로 필터링하면 비용을 절감하고, 데이터 노출 위험을 줄이며, 각 구성 요소가 정말 중요한 것에 집중할 수 있습니다.
아키텍처에 따라 IaC(Infrastructure as Code)를 사용하여 애플리케이션과 인프라 환경의 변경 사항을 하나의 작업으로 배포할 수 있습니다. 이 접근 방식을 사용하면 로그 필터 패턴도 애플리케이션 코드와 함께 배포되므로, 애플리케이션과 동일한 수준의 버전 관리와 검증 절차를 적용할 수 있습니다.
이중 수집 안티패턴 방지
관리자가 추구하는 일반적인 패턴은 모든 로깅 데이터를 단일 시스템에 복사하여 단일 위치에서 모든 logs를 쿼리하는 것입니다. 이렇게 하면 수동 워크플로우에 몇 가지 이점이 있지만, 이 패��턴은 추가 비용, 복잡성, 장애 지점 및 운영 오버헤드를 도입합니다.
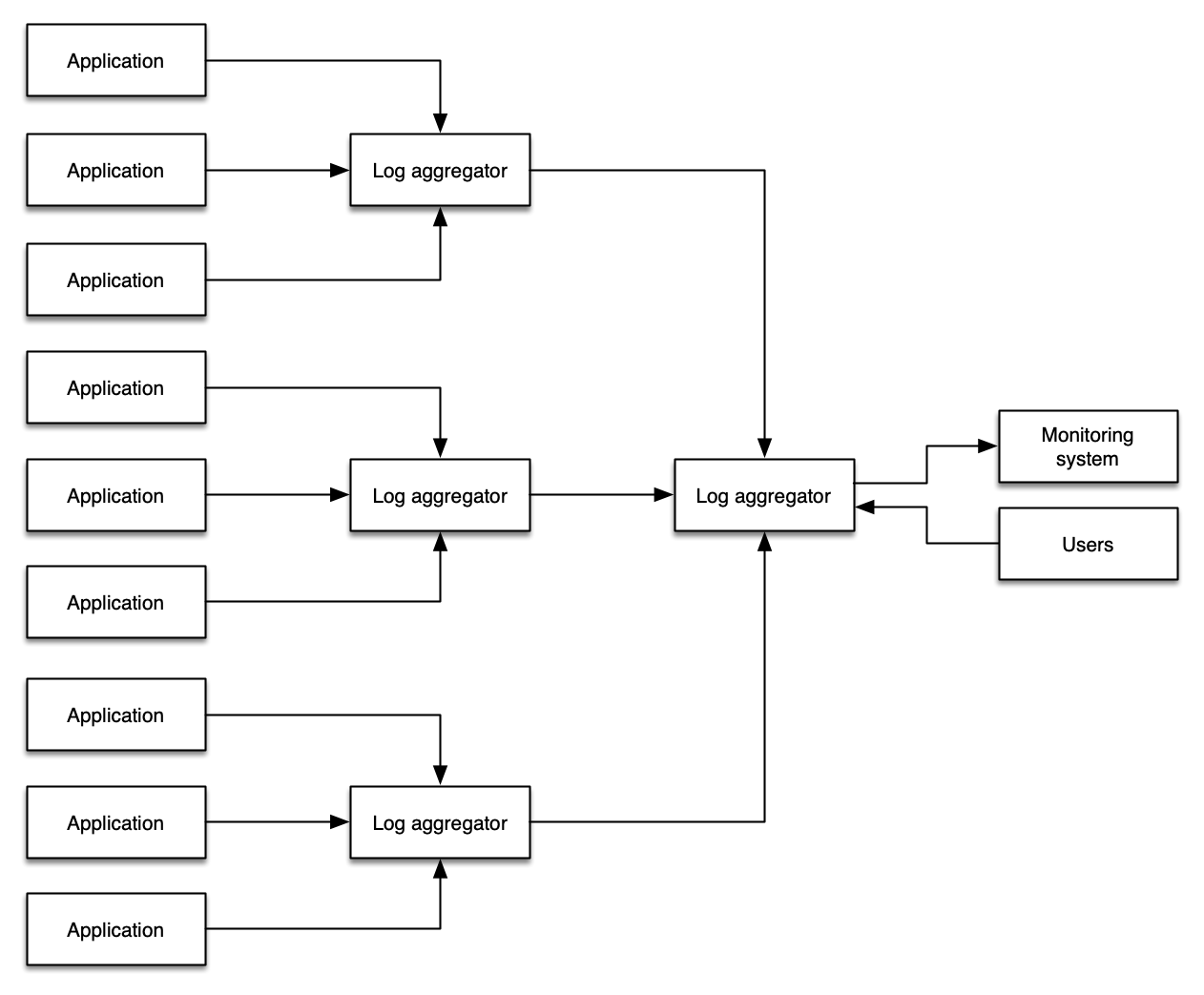
가능한 경우 log level과 log filtering의 조합을 사용하여 환경에서 log 데이터의 전면적인 전파를 방지하세요.
일부 조직이나 워크로드는 규정 요구 사항을 충족하거나, 안전한 위치에 logs를 저장하거나, 부인 방지를 제공하거나, 기타 목표를 달성하기 위해 log shipping이 필요합니다. 이는 log 데이터를 재수집하는 일반적인 사용 사례입니��다. 적절한 log level과 log filtering의 적용은 이러한 log 아카이브에 들어가는 불필요한 데이터의 볼륨을 줄이는 데 여전히 적절합니다.
Logs에서 metric 데이터 수집
Logs에는 수집을 기다리는 metrics가 포함되어 있습니다! 직접 작성하지 않은 ISV 솔루션이나 애플리케이션도 전체 워크로드 상태에 대한 의미 있는 인사이트를 추출할 수 있는 유용한 데이터를 logs에 출력합니다. 일반적인 예시는 다음과 같습니다:
- 데이터베이스의 느린 쿼리 시간
- 웹 서버의 가동 시간
- 트랜잭션 처리 시간
- 시간 경과에 따른
ERROR또는WARNING이벤트 수 - 업그레이드 가능한 패키지의 총 개수
이 데이터는 정적 log 파일에 잠겨 있을 때는 유용성이 떨어집니다. 모범 사례는 핵심 metric 데이터를 식별한 다음 다른 signal과 상관 관계를 분석할 수 있는 metric 시스템에 게시하는 것입니다.
stdout로 로깅
가능한 경우 애플리케이션은 파일이나 소켓과 같은 고정된 위치가 아닌 stdout로 로깅해야 합니다. 이를 통해 log agent가 자체 Observability 솔루션에 적합한 규칙에 따라 log 이벤트를 수집하고 라우팅할 수 있습니다. 모든 애플리케이션에 가능한 것은 아니지만, 이것은 컨테이너화된 워크로드에 대한 모범 사례입니다.
애플리케이션은 로깅 솔루션과 느슨하게 결합된 상태를 유지하면서 로깅 관행에서 일반적이고 단순해야 하지만, log 데이터의 전송에는 stdout에서 파일로 데이터를 보내기 위한 log collector가 여전히 필요합니다. 중요한 개념은 애플리케이션과 비즈니스 로직이 로깅 인프라에 의존하지 않도록 하는 것입니다. 즉, 관심사의 분리를 위해 노력해야 합니다.
애플리케이션을 log 관리에서 분리하면 코드 변경 없이 솔루션을 적응하고 발전시킬 수 있으며, 이를 통해 환경에 대한 변경의 잠재적 영향 범위를 최소화할 수 있습니다.