Alarms
Alarm은 probe, monitor의 상태 또는 주어진 임계값 이상 또는 이하로의 값 변화를 의미합니다. 간단한 예로는 디스크가 가득 차거나 웹 사이트가 다운되었을 때 이메일을 보내는 alarm이 있습니다. 더 정교한 alarm은 완전히 프로그래밍 방식으로 작동하며, auto-scaling이나 전체 서버 클러스터 생성과 같은 복잡한 상호 작용을 구동하는 데 사용됩니다.
사용 사례에 관계없이, alarm은 metric의 현재 상태를 나타냅니다. 이 상태는 시스템에 따라 OK, WARNING, ALERT 또는 NO DATA일 수 있습니다.
Alarm은 일정 기간 동안 이 상태를 반영하며 timeseries 위에 구축됩니다. 따라서 timeseries에서 파생됩니다. 아래 그래프는 두 개의 alarm을 보여줍니다: 하나는 warning 임계값이 있고, 다른 하나는 이 timeseries의 평균값을 나타냅니다. 이 그래프에서 보��여지는 트래픽 볼륨에 따라, warning 임계값에 대한 alarm은 정의된 값 아래로 떨어질 때 위반 상태에 있어야 합니다.
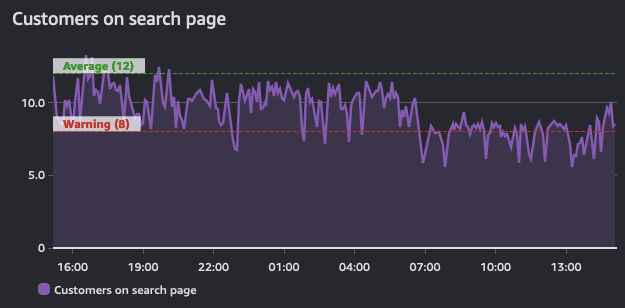
Alarm의 목적은 작업(사람 또는 프로그래밍 방식)을 트리거하거나, 임계값이 위반되었다는 정보를 제공하는 것입니다. Alarm은 metric의 성능에 대한 인사이트를 제공합니다.
실행 가능한 것에 대해 알림 보내기
Alarm fatigue란 사람들이 너무 많은 알림을 받아서 무시하는 법을 배우게 되는 현상입니다. 이것은 잘 모니터링된 시스템의 징후가 아닙니다! 오히려 안티패턴입니다.
실행 가능한 것에 대해 alarm을 생성하고, 항상 목표로부터 역방향으로 작업해야 합니다.
예를 들어, 빠른 응답 시간이 필요한 웹 사이트를 운영하는 경우, 응답 시간이 주어진 임계값을 초과할 때 전달될 알림을 생성하세요. 그리고 성능 저하가 높은 CPU 사용률과 관련이 있다고 확인된 경우, 문제가 되기 전에 이 데이터 포인트에 대해 사전에 알림을 보내세요. 그러나 환경의 모든 곳에서 모든 CPU 사용률에 대해 알림을 보낼 필요는 없을 수 있습니다. 이것이 결과를 위협하지 않는다면 말입니다.
Alarm이 알림을 보내거나 자동화된 프로세스를 트리거할 필요가 없다면, 알림을 보낼 필요가 없습니다. 불필요한 alarm에서 알림을 제거해야 합니다.
"모든 것이 정상" alarm에 주의하기
마찬가지로, 일반적인 패턴은 "모든 것이 정상" alarm입니다. 이는 운영자가 지속적인 알림을 받는 데 너무 익숙해져서 갑자기 조용해질 때만 알아차리는 경우입니다! 이는 매우 위험한 운영 모드이며, 운영 우수성에 반하는 패턴입니다.
"모든 것이 정상" alarm은 일반적으로 사람이 해석해야 합니다! 이는 self-healing 애플리케이션과 같은 패턴을 불가능하게 만듭니다.1
집계를 통한 alarm fatigue 대응
Observability는 기술 문제가 아닌 인간의 문제입니다. 따라서 alarm 전략은 더 많은 alarm을 생성하는 것이 아니라 줄이는 데 초점을 맞춰야 합니다. 텔레메트리 수집을 구현하면 환경에서 더 많은 알림이 발생하는 것은 자연스러운 일입니다. 그러나 실행 가능한 것에 대해서만 알림��을 보내도록 주의하세요. 알림을 발생시킨 조건이 실행 가능하지 않다면 보고할 필요가 없습니다.
이것은 예시로 가장 잘 설명됩니다: 백엔드에 단일 데이터베이스를 사용하는 다섯 대의 웹 서버가 있다면, 데이터베이스가 다운되면 웹 서버에 무슨 일이 발생할까요? 많은 사람들에게 답은 최소 6개의 알림을 받는다는 것입니다 - 웹 서버에서 5개, 데이터베이스에서 1개!
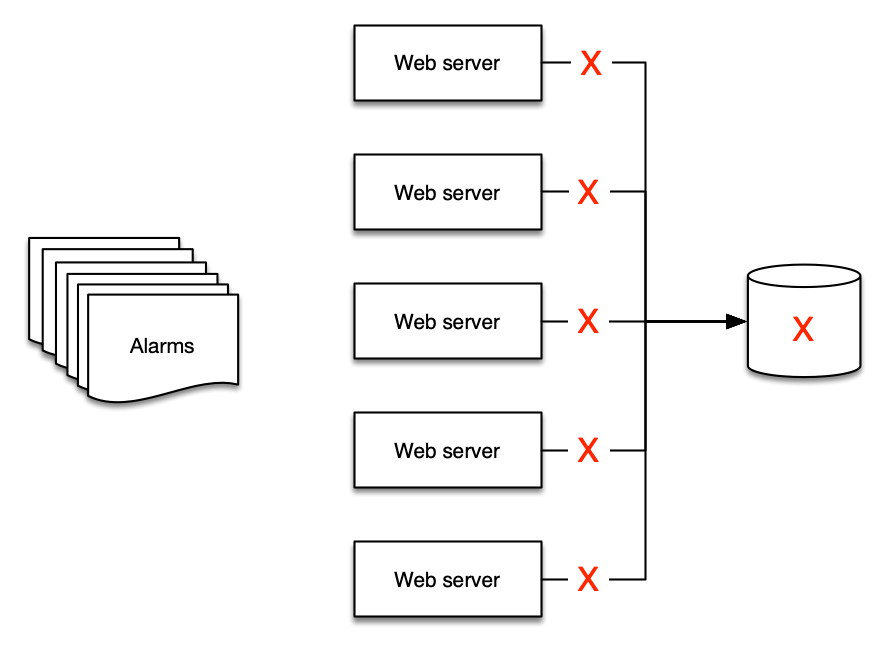
하지만 전달하는 것이 의미 있는 알림은 두 개뿐입니다:
- 웹 사이트가 다운되었다
- 데이터베이스가 원인이다
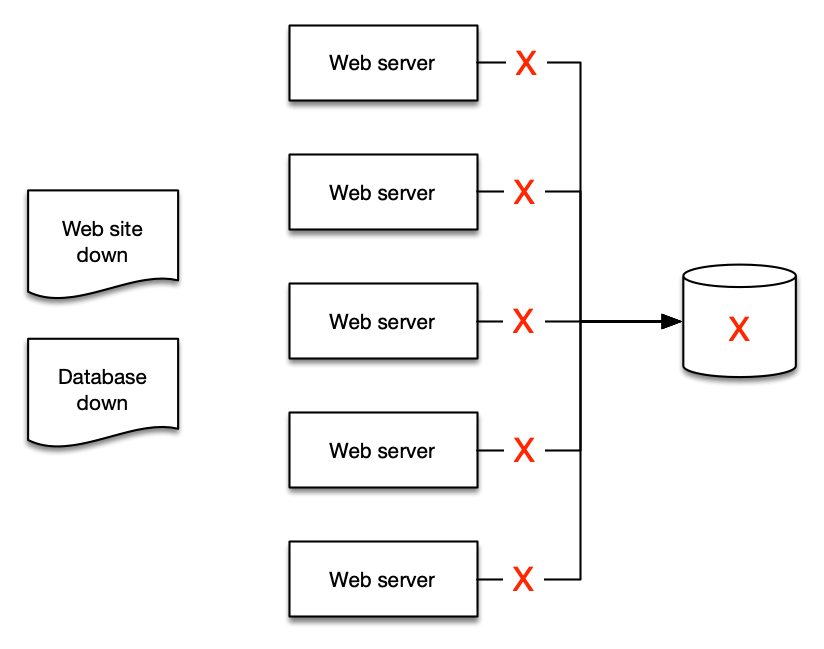
알림을 집계로 정제하면 사람들이 이해하기 쉬워지고, runbook과 자동화를 만들기가 더 쉬워집니다.
기존 ITSM 및 지원 프로세스 활용
모니터링 및 Observability 플랫폼에 관계없이, 현재 도구 체인에 통합되어야 합니다.
알림에서 이러한 도구로의 프로그래밍 방식의 통합을 사용하여 trouble ticket과 issue를 생성하고, 수동 작업을 제거하며 프로세스를 간소화하세요.
이를 통해 DORA metrics와 같은 중요한 운영 데이터를 도출할 수 있습니다.
Cron Schedule에 따른 Alarm Actions 활성화
Alarm은 AWS 리소스에 대한 필수적인 모니터링 기능을 제공하여, 팀이 metrics를 추적하고 임계값이 위반되었을 때 알림을 받을 수 있게 합니다. 이 모니터링은 운영 인식을 유지하는 데 매우 중요하지만, 조직이 예약된 리소스 종료를 포함하는 비용 최적화 전략을 구현할 때 일반적인 문제가 발생합니다. 이 특정 시나리오에서는 프로덕션 리소스가 업무 시간 외(월요일부터 금요일까지 오후 6시부터 오전 6시, 주말)에 자동으로 종료되도록 구성�됩니다. 그러나 CloudWatch Alarms는 이러한 계획된 다운타임 기간 동안에도 계속 모니터링하고 알림을 트리거하여, 의도적으로 오프라인인 리소스에 대해 불필요한 알림이 발생합니다. EventBridge Schedules와 Lambda functions를 활용하는 솔루션을 구현하여 tag 기반으로 리소스 스케줄링에 맞춰 alarm을 프로그래밍 방식으로 활성화 및 비활성화할 수 있으며, 업무 시간 동안 효과적인 모니터링을 보장하면서 계획된 다운타임 동안의 잘못된 알림을 제거할 수 있습니다.
아키텍처
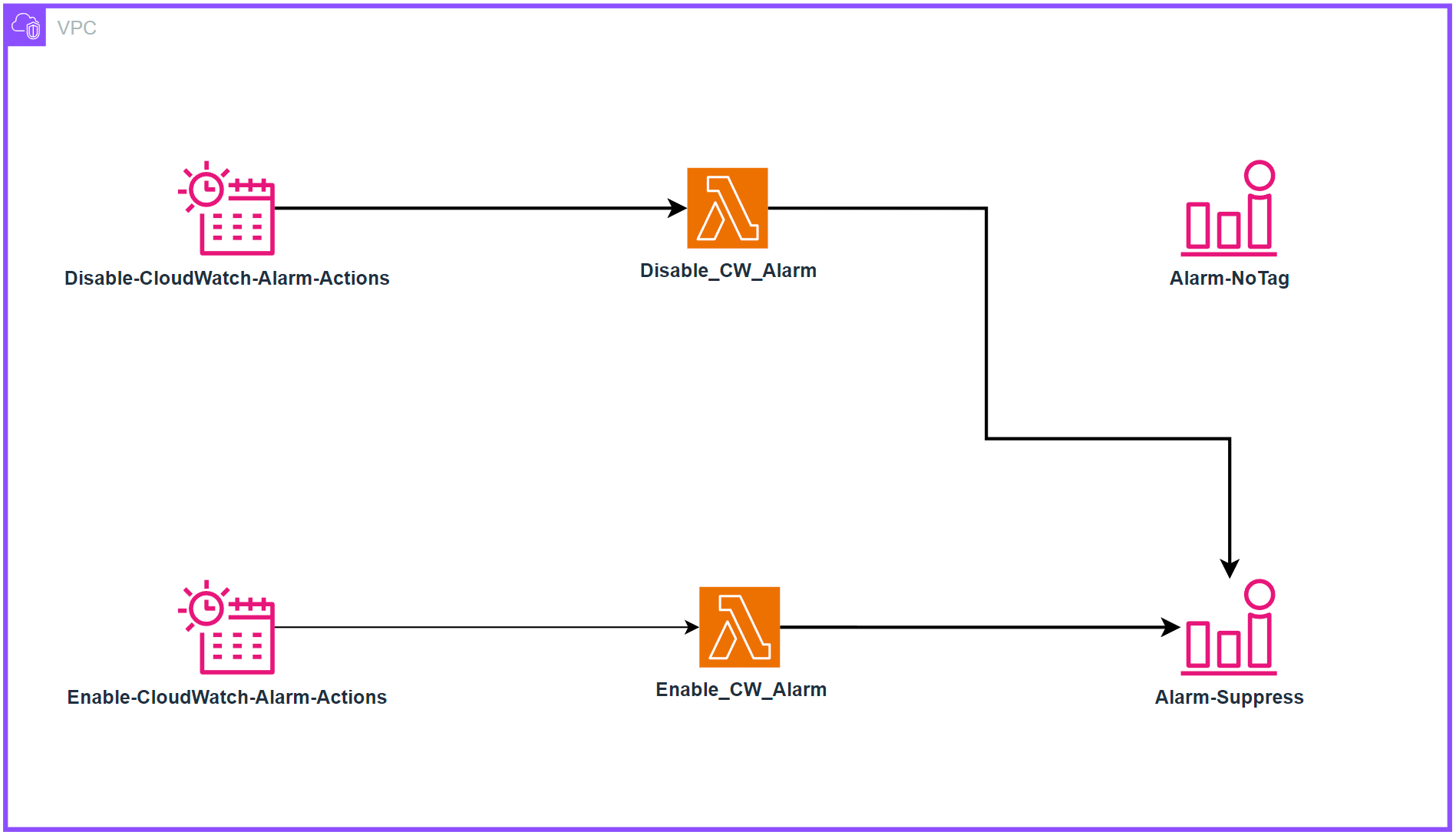
배포
리포지토리를 클론합니다:
git clone https://github.com/aws-observability/observability-best-practices.git
CloudFormation template을 찾습니다:
cd observability-best-practices/sandbox/cw-alarm-scheduler
해당 디렉토리에 'cf.yaml' CloudFormation template이 있습니다.
CloudFormation 콘솔로 이동하여 해당 template에서 stack을 생성합니다:
- Stack 세부 정보 지정:
- Stack 이름 입력:
- Stack name: $STACK-NAME
- Parameters:
- DisableAlarmsCronSchedule: (alarm을 비활성화할 시기를 정의하는 cron 표현식 입력)
- Default cron(00 18 ? * 1-5 *)
- EnableAlarmsCronSchedule: (alarm을 활성화할 시기�를 정의하는 cron 표현식 입력)
- Default cron(00 06 ? * 1-5 *)
- LambdaArchitecture: Lambda function 아키텍처 선택 (x86_64 또는 arm64)
- Default arm64
- ScheduleTimezone: 드롭다운 목록에서 시간대 선택
- Default America/New_York
- SuppressTagKey: CloudWatch Alarms를 필터링할 tag의 Key (예: 'suppress' 또는 'snooze')
- Default "suppress"
- SuppressTagValue: CloudWatch Alarms를 필터링할 tag의 Value (예: 'true')
- Default "true"
- DisableAlarmsCronSchedule: (alarm을 비활성화할 시기를 정의하는 cron 표현식 입력)
- Next
- Stack 이름 입력:
이렇게 하면 CloudFormation parameters에서 선택한 key value로 태그된 alarm이 선택한 Cron Schedule을 따르게 됩니다.
예시:
SuppressTagKey에 'suppress', SuppressTagValue에 'true'를 선택하면, 'suppress':'true' tag가 있는 모든 alarm이 DisableAlarmsCronSchedule과 EnableAlarmsCronSchedule에 설정한 스케줄을 따르게 됩니다.
동작: Alarm이 비활성화된 경우:
- 알림이나 notification이 생성되지 않습니다
- Metric 수집은 중단 없이 계속됩니다
Alarm이 다시 활성화된 경우:
- 정상적인 알림 기능이 곧 재개됩니다