Events
이벤트란 무엇을 의미하는가?
요즘 많은 아키텍처가 이벤트 기반입니다. 이벤트 기반 아키텍처에서 이벤트는 서로 다른 시스템에서 발생하는 signal로, 이를 캡처하여 다른 시스템으로 전달합니다. 이벤트는 일반적으로 상태의 변화 또는 업데이트입니다.
예를 들어, 전자상거래 시스템에서 장바구니에 상품을 추가할 때 이벤트가 발생할 수 있습니다. 이 이벤트는 캡처되어 시스템의 장바구니 부분으로 전달되어, 항목 수와 장바구니 비용을 상품 세부 정보와 함께 업데이트할 수 있습니다.
일부 고객에게 이벤트는 구매 완료와 같은 마일스톤일 수 있습니다. 워크플로우 완료의 집합적 순간을 이벤트로 취급할 수 있는 경우가 있지만, 이 문서에서는 마일스톤 자체를 이벤트로 간주하지 않습니다.
이벤트는 왜 유용한가?
Observability 솔루션에서 이벤트가 유용할 수 있는 두 가지 주요 방법이 있습니다. 하나는 다른 데이터의 context에서 이벤트를 시각화하는 것이고, 다른 하나는 이벤트를 기반으로 조치를 취할 수 있게 하는 것입니다.
이벤트는 워크로드의 변경 및 작업에 대해 사람이나 기계에 유용한 정보를 제공하기 위한 것입니다.
이벤트 시각화
애플리케이션에서 직접 발생하지는 않지만 애플리케이션 성능에 영향을 미치거나 근본 원인에 대한 추가 인사이트를 제공할 수 있는 많은 이벤트 signal이 있습니다. Dashboard는 이벤트를 시각화하는 가장 일반적인 메커니즘이지만, 일부 analytics 또는 business intelligence 도구도 이 context에서 사용할 수 있습니다. 이메일이나 인스턴트 메시징 애플리케이션도 시각화를 쉽게 수신할 수 있습니다.
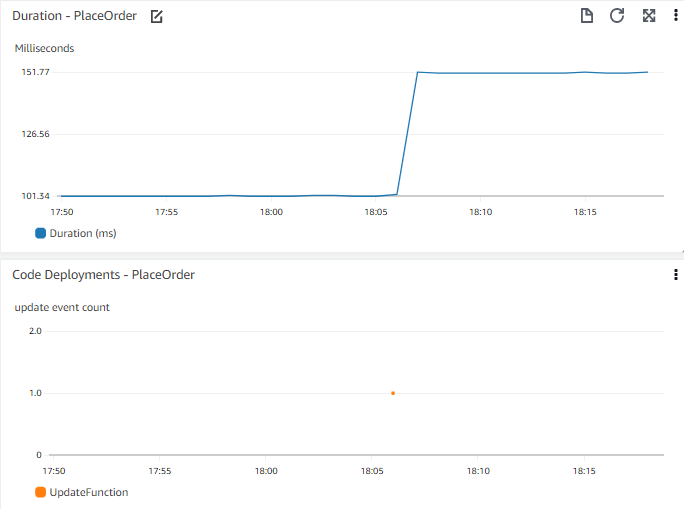
웹 프론트엔드에서 주문하는 데 걸리는 시간과 같은 애플리케이션 성능의 timechart를 고려해 보세요. Timechart를 통해 며칠 전에 응답 시간에 급격한 변화가 있었음을 확인할 수 있습니다. 최근 배포가 있었는지 아는 것이 유용할 수 있습니다. 최근 배포의 timechart를 동일한 차트 옆에 또는 겹쳐서 볼 수 있다면 어떨까요?
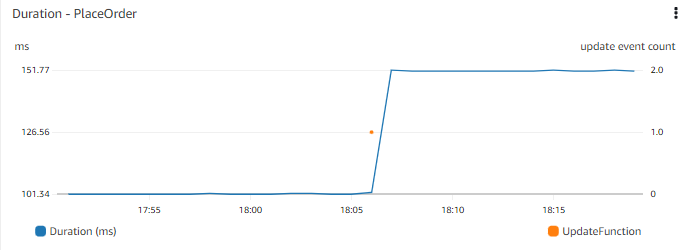
더 넓은 context를 이해하는 데 유용할 수 있는 이벤트를 고려하세요. 중요한 이벤트는 코드 배포, 인프라 변경 이벤트, 새 데이터 추가(예: 판매할 새 상품 게시 또는 새 사용자 일괄 추가), 또는 기능 수정 또는 추가(예: 사람들이 장바구니에 상품을 추가하는 방식 변경)일 수 있습니다.
다른 중요한 metric 데이터와 함께 이벤트를 시각화하여 이벤트를 상관 분석할 수 있습니다.
이벤트에 대한 조치 취하기
Observability 세계에서 트리거된 alarm은 일반적인 이벤트입니다. 이 이벤트에는 alarm의 식별자, alarm 상태(예: IN ALARM 또는 OK), 그리고 이를 트리거한 세부 정보가 포함될 수 있습니다. 대부분의 경우 이 alarm 이벤트가 감지되면 이메일 알림이 전송됩니다. 이것이 alarm에 대한 조치의 예입니다.
Alarm 알림은 Observability에서 매우 중요합니다. 이를 통해 적절한 사람에게 문제가 있음을 알릴 수 있습니다. 그러나 이벤트에 대한 조치가 Observability 솔루션에서 성숙해지면, 사람의 개입 없이 자동으로 문제를 해결할 수 있습니다.
어떤 조치를 취해야 하는가?
먼저 감지된 문제를 완화할 조치가 무엇인지 이해하지 않고는 조치를 자동화할 수 없습니다. Observability 여정의 시작 단계에서는 이것이 명확하지 않을 수 있습니다. 그러나 문제를 해결한 경험이 많을수록, 알려진 조치가 있는 영역을 포착하도록 alarm을 더 세밀하게 조정할 수 있습니다. 사용 중인 alarm 서비스에 내장된 조치가 있을 수도 있고, alarm 이벤트를 직접 캡처하여 해결 방법을 스크립트로 작성해야 할 수도 있습니다.
Horizontal pod autoscaling과 같은 auto-scaling 시스템은 이 원칙의 구현일 뿐입니다. Kubernetes는 단순히 이 자동화를 추상화해 줍니다.
Alarm 빈도와 해결에 대한 데이터에 접근하면 자동화 가능성이 있는지 판단하는 데 도움이 됩니다. 증상 기반의 더 넓은 범위의 alarm이 문제를 포착하는 데 훌륭하지만, 자동 해결에 연결하��려면 더 구체적인 기준이 필요할 수 있습니다.
이를 수행할 때, 인시던트 관리/티켓팅/ITSM 도구와 통합하는 것을 고려하세요. 많은 조직이 인시던트와 관련 해결 방법, Mean Time to Resolve(MTTR)와 같은 metrics를 추적합니다. 이렇게 하는 경우, 자동화된 해결도 유사한 방식으로 캡처하는 것을 고려하세요. 이를 통해 자동으로 해결되는 문제의 유형과 비율을 이해할 수 있을 뿐만 아니라, 근본적인 패턴과 문제를 찾을 수 있습니다.
누군가가 수동으로 문제를 수정할 필요가 없었다고 해서, 근본 원인을 조사하지 않아도 된다는 의미는 아닙니다.
예를 들어, 서버가 응답하지 않을 때마다 재시작하는 것을 고려하세요. 재시작으로 시스템이 계속 작동할 수 있지만, 무엇이 무응답을 유발하는지가 문제입니다. 이것이 얼마나 자주 발생하는지, 패턴이 있는지(예: 보고서 생성, 높은 사용자 수, 시스템 백업과 일치하는지)에 따라 근본 원인을 이해하고 수정하는 데 투입할 우선순위와 리소스가 결정됩니다.
핵심 성과 지표와 관련된 모든 이벤트를 소비를 위해 message bus로 전달하는 것을 고려하세요. 일부 Observability 솔루션은 명시적인 구성 요구 사항 없이 이를 투명하게 수행합니다.
Observability 플랫폼에 이벤트 가져오기
중요한 이벤트를 식별한 후에는, Observability 플랫폼에 이벤트를 가져오는 최선의 방법을 고려해야 합니다. 플랫폼에 이벤트를 캡처하는 특정 방법이 있을 수도 있고, logs나 metric 데이터로 가져와야 할 수도 있습니다.
정보를 가져오는 간단한 방법 중 하나는 이벤트를 log 파일에 기록하고 다른 log 이벤트와 동일한 방식으로 수집하는 것입니다.
시스템에서 이러한 이벤트를 어떻게 시각화할 수 있는지 탐색하세요. 애플리케이션과 관련된 이벤트를 식별할 수 있나요? 단일 차트에 데이터를 결합할 수 있나요? 특별한 기능이 없더라도, 다른 데이터와 시각적으로 상관 분석할 수 있도록 최소한 timechart를 나란히 만들 수 있어야 합니다. 시간 축을 동일하게 유지하고, 쉬운 비교를 위해 수직으로 쌓는 것을 고려하세요.