イベント
イベントとは何を意味するのか?
現代の多くのアーキテクチャはイベント駆動型です。イベント駆動型アーキテクチャでは、イベントはさまざまなシステムからのシグナルであり、それをキャプチャして他のシステムに渡します。イベントは通常、状態の変化または更新を表します。
例えば、eコマースシステムでは、商品がカートに追加されたときにイベントが発生する場合があります。このイベントをキャプチャし、システムの�ショッピングカート部分に渡すことで、カート内の商品数や合計金額を、商品の詳細情報とともに更新することができます。
一部のお客様にとって、イベントとは購入完了などのマイルストーンである場合があります。ワークフロー完了の集約的な瞬間をイベントとして扱うことには一定の根拠がありますが、本ドキュメントの目的においては、マイルストーン自体をイベントとは見なしません。
イベントはなぜ役立つのですか?
イベントが Observability ソリューションで役立つ主な方法は 2 つあります。1 つはその他のデータのコンテキストでイベントを可視化することであり、もう 1 つはイベントに基づいてアクションを実行できるようにすることです。
イベントは、ワークロードにおける変更やアクションについて、人またはシステムに対して有益な情報を提供することを目的としています。
イベントの可視化
アプリケーションから直接発生するものではないものの、アプリケーションのパフォーマンスに影響を与えたり、根本原因に関する追加の洞察を提供したりするイベントシグナルが多数存在します。ダッシュボードはイベントを可視化するための最も一般的なメカニズムですが、一部の分析ツールやビジネスインテリジェンスツールもこのコンテキストで機能します。メールやインスタントメッセージングアプリケーションでも、可視化コンテンツを簡単に受信できます。
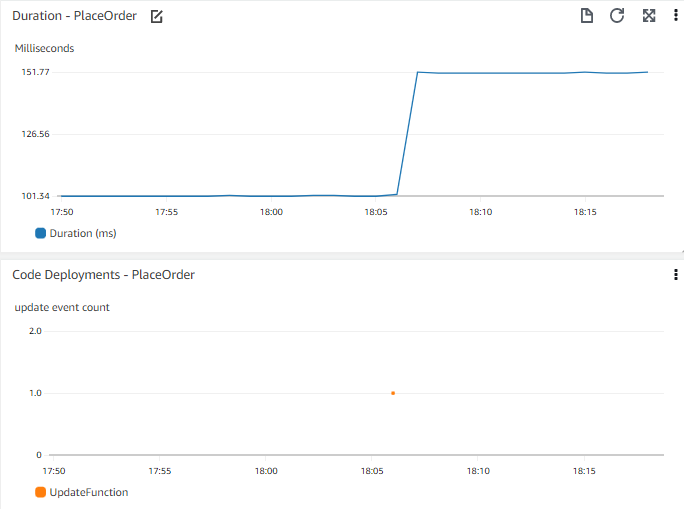
アプリケーションのパフォーマンスのタイムチャート(例えば、Web フロントエンドで注文を完了するまでの時間)を考えてみましょう。タイムチャートを使用すると、数日前にレスポンスタイムに段階的な変化があったことを確認できます。最近のデプロイメントがあったかどうかを把握できると便利かもしれません。最近のデプロイメントのタイムチャートを同じチャートに並べて表示したり、重ねて表示したりできることを想像してみてください。
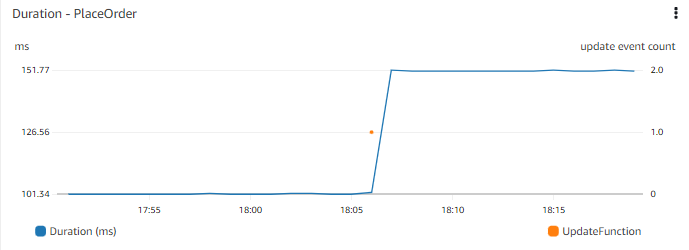
より広いコンテキストを理解するために役立つイベントを検討してください。重要なイベントとしては、コードのデプロイ、インフラストラクチャの変更イベント、新しいデータの追加(販売する新しいアイテムの公開や新規ユーザーの一括追加など)、または機能の変更や追加(ユーザーがカートにアイテムを追加する方法の変更など)が挙げられます。
イベントを他の重要なメトリクスデータと一緒に可視化することで、イベント�を関連付けることができます。
イベントに対してアクションを実行する
オブザーバビリティの世界では、トリガーされたアラームは一般的なイベントです。このイベントには、アラームの識別子、アラームの状態(例えば IN ALARM、または OK)、およびこれをトリガーした内容の詳細が含まれます。多くの場合、このアラームイベントは検出され、メール通知が送信されます。これはアラームに対するアクションの例です。
アラーム通知はオブザーバビリティにおいて非常に重要です。これは、問題が発生したときに適切な担当者に通知する方法です。ただし、オブザーバビリティソリューションでイベントへの対応が成熟すると、人間の介入なしに問題を自動的に修復できるようになります。
しかし、どのようなアクションを取るべきでしょうか?
検出された問題を緩和するアクションを理解せずに、アクションを自動化することはできません。Observability の取り組みを始めたばかりの段階では、これが明確でないことも多いでしょう。しかし、問題の修復経験を積むほど、既知のアクションが存在する領域を検知できるようにアラームを細かく調整できるようになります。使用しているアラームサービスに組み込みのアクションが用意されている場合もあれば、アラームイベントを自分でキャプチャして解決策をスクリプト化する必要がある場合もあります。
水平 Pod オートスケーリングなどの自動スケーリングシステムは、この原則の実装にすぎません。Kubernetes はこの自動化を抽象化してくれます。
アラームの頻度と解決に関するデータにアクセスできることで、自動化の可能性があるかどうかを判断するのに役立ちます。問題の症状に基づいた広範囲のアラームは問題の検出に優れていますが、自動修復にリンクするためにはより具体的な基準が必要になる場合があります。
これを行う際には、インシデント管理/チケット管理/ITSM ツールとの統合を検討してください。多くの組織では、インシデントや関連する解決策、および平均解決時間 (MTTR) などのメトリクスを追跡しています。これを行う場合は、自動化された解決策も同様の方法で記録することを検討してください。これにより、自動的に修復される問題の種類と割合を把握できるだけでなく、根本的なパターンや問題を探ることも可能になります。
誰かが問題を手動で修正する必要がなかったからといって、根本的な原因を調べなくてよいということにはなりません。
例えば、サーバーが応答しなくなるたびに再起動するケースを考えてみましょう。再起動によってシステムは動作を継続できますが、応答しなくなる原因は何でしょうか。これがどのくらいの頻度で発生するか、またパターンがあるかどうか(例えば、レポート生成、ユーザー数の増加、またはシステムバックアップと一致するパターンなど)によって、根本原因の理解と修正に割り当てる優先度とリソースが決まります。
主要パフォーマンス指標に関連するすべてのイベントをメッセージバスに配信して消費できるようにすることを検討してください。また、一部のオブザーバビリティソリューションでは、明示的な設定を必要とせずにこれを透過的に実行することに注意してください。
イベントをオブザーバビリティプラットフォームに取り込む
重要なイベントを特定したら、それらを Observability プラットフォームに取り込む最善の方法を検討する必要があります。 プラットフォームによっては、イベントをキャプチャする特定の方法が用意されている場合もあれば、ログやメトリクスデータとして取り込む必要がある場合もあります。
情報を取り込む簡単な方法の 1 つは、イベントをログファイルに書き込み、他のログイベントと同じ方法で取り込むことです。
システムがこれらをどのように視覚化できるかを確認してください。アプリケーションに関連するイベントを特定できますか?データを単一のチャートにまとめることはできますか?特定のものがない場合でも、少なくとも他のデータと並べてタイムチャートを作成し、視覚的に相関させることができるはずです。時間軸を同じに保ち、比較しやすいようにこれらを縦に積み重ねることを検討してください。