Logs
Logs 是由应用程序或设备发送的一系列消息,由一行或多行关于事件或有时关于应用程序健康状况的详情组成。通常,logs 被写入文件,有时也会发送到执行分析和聚合的收集器。有许多功能完善的 log 聚合器、框架和产品,旨在使生成、摄取和管理任何量级的 log 数据变得更加容易——从每天兆字节到每小时太字节。
Logs 由单个应用程序一次发出,通常与该应用程序的范围相关——尽管开发人员可以让 logs 的内容变得复杂和细致。就我们的目的而言,我们认为 logs 与 traces 是根本不同的信号,traces 由来自多个应用程序或服务的事件组成,并包含服务之间连接的上下文信息,如响应延迟、服务故障、请求参数等。
Logs 中的数据也可以在一段时间内进行聚合。例如,它们可能是统计性的(如过去一分钟内服务的请求数��量)。它们可以是结构化的、自由格式的、详细的,并且可以使用任何语言编写。
Logs 的主要使用场景包括描述:
- 事件,包括其状态和持续时间以及其他关键统计信息
- 与该事件相关的错误或警告(如堆栈跟踪、超时)
- 应用程序启动和关闭消息
Logs 旨在是不可变的,许多 log 管理系统包含保护机制来防止和检测修改 log 数据的尝试。
无论您对 logging 有什么要求,以下是我们确定的最佳实践。
结构化 logging 是成功的关键
许多系统会以半结构化格式输出 logs。例如,Apache Web 服务器可能会像这样写入 logs,每行对应一个 Web 请求:
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395 127.0.0.1 - - [28/Jul/2006:10:22:04 -0300] "GET / HTTP/1.0" 200 2216
而 Java 堆栈跟踪可能是跨多行的单个事件,结构化程度较低:
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Python 错误 log 事件可能是这样的:
Traceback (most recent call last):
File "e.py", line 7, in <module>
raise TypeError("Again !?!")
TypeError: Again !?!
在这三个例子中,只有第一个可以轻松被人类和 log 聚合系统解析。使用结构化 logs 可以快速有效地处理 log 数据,为人类和机器提供他们需要的数据,以便立即找到所需内容。
最常见的 log 格式是 JSON,其中事件的每个组件都表示为键/值对。在 JSON 中,上面的 Python 示例可以重写为:
{
"level", "ERROR"
"file": "e.py",
"line": 7,
"error": "TypeError(\"Again !?!\")"
}
使用结构化 logs 使您的数据可以从一个 log 系统移植到另一个,简化开发,并使操作诊断更快(错误更少)。此外,使用 JSON 将 log 消息的 schema 与实际数据一起嵌入,�使复杂的 log 分析系统能够自动索引您的消息。
适当使用 log 级别
有两种类型的 logs:具有级别的和作为事件序列的。对于具有级别的 logs,这些是成功 logging 策略的关键组成部分。Log 级别在不同框架之间略有不同,但通常遵循以下结构:
| 级别 | 描述 |
|---|---|
DEBUG | 细粒度的信息性事件,对调试应用程序最有用。这些通常对开发人员有价值且非常详细。 |
INFO | 以粗粒度级别突出显示应用程序进度的信息性消息。 |
WARN | 可能有害的情况,表示对应用程序的风险。这些可以触发应用程序中的告警。 |
ERROR | 可能仍允许应用程序继续运行的错误事件。这些可能会触发需要关注的告警。 |
FATAL | 非常严重的错误事件,可能会导致应用程序中止。 |
没有显式级别的 logs 可能被隐式视为 INFO,尽管此行为可能因应用程序而异。
其他常见的 log 级别包括 CRITICAL 和 NONE,具体取决于您的需求、编��程语言和框架。ALL 和 NONE 也很常见,尽管并非在每个应用程序栈中都有。
Log 级别对于告知您的监控和可观测性解决方案有关环境健康状况至关重要,log 数据应使用逻辑值轻松表达此信息。
在 WARN 级别记录过多数据会使您的监控系统充满价值有限的数据,然后您可能会在大量消息中丢失重要数据。
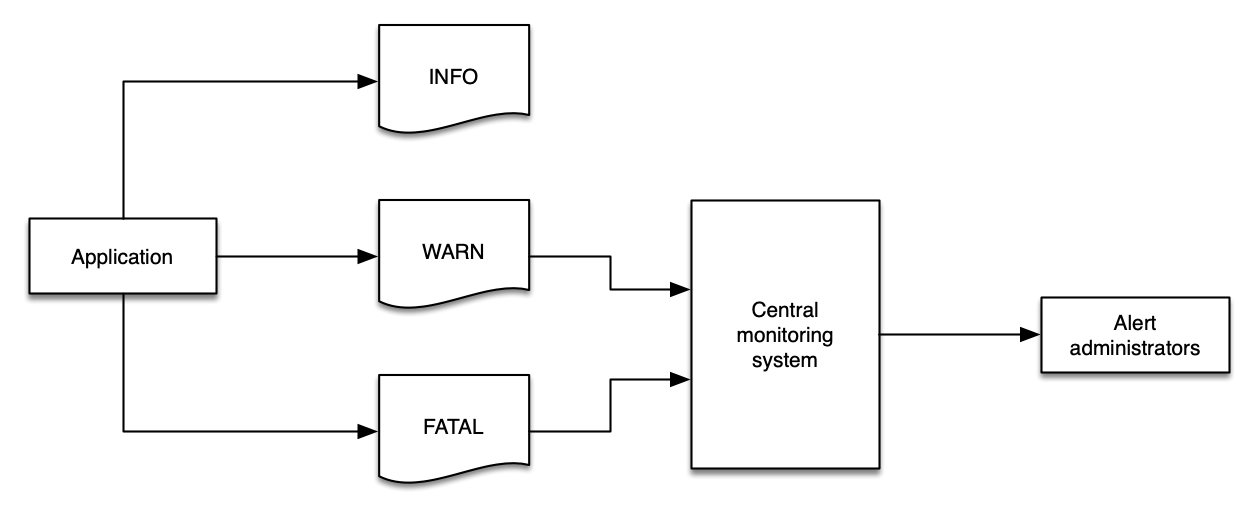
使用标准化的 log 级别策略使自动化更容易,并帮助开发人员快速找到问题的根本原因。
没有标准的 log 级别方法,过滤 logs 将成为一个主要挑战。
在源头附近过滤 logs
尽可能在接近源头的位置减少 logs 的量。遵循此最佳实践有许多原因:
- 摄取 logs 始终需要时间、金钱和资源。
- 从下游系统过滤敏感数据(如个人身份信息)可减少数据泄露的风险暴露。
- 下游系统可能与数据源没有相同的运营关注点。例如,应用程序的
INFOlogs 可能对监视CRITICAL或FATAL消息的监控和告警系统毫无兴趣。 - Log 系统和网络不应承受不必要的压力和流量。
在源头附近过滤 logs 以降低成本、减少数据暴��露风险,并让每个组件专注于重要的事情。
根据您的架构,您可能希望使用基础设施即代码 (IaC) 在一次操作中部署应用程序和环境的更改。这种方法允许您将 log 过滤模式与应用程序一起部署,给予它们同样的严格性和处理方式。
避免双重摄取反模式
管理员追求的一种常见模式是将所有 logging 数据复制到单个系统中,目标是从单个位置查询所有 logs。这样做在手动工作流程方面有一些优势,但这种模式引入了额外的成本、复杂性、故障点和运营开销。
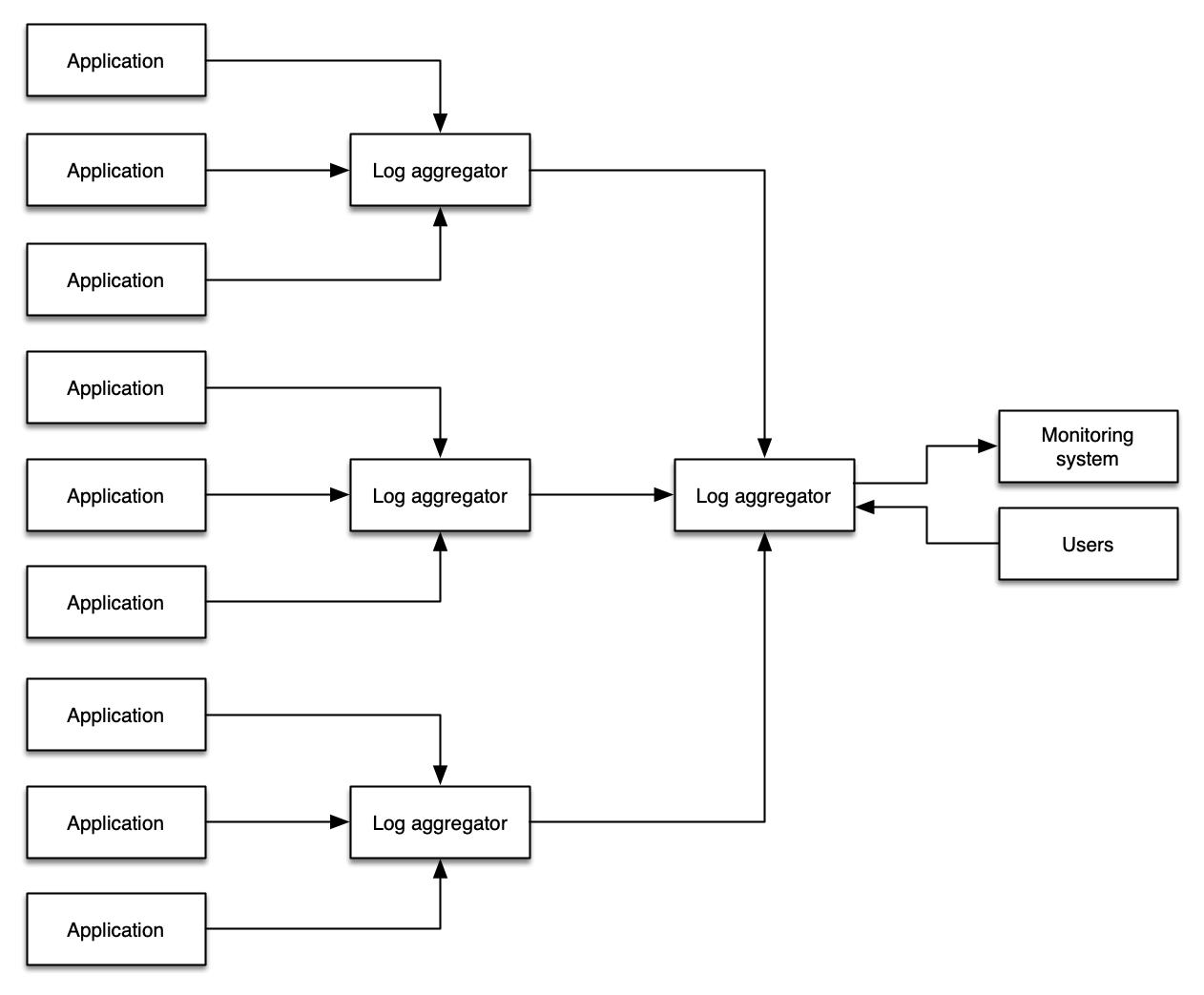
某些组织或工作负载需要 log shipping 以满足法规要求、将 logs 存储在安全位置、提供不可否认性或实现其他目标。这是重新摄取 log 数据的常见使用场景。请注意,适当应用 log 级别和 log 过滤仍然适用于减少进入这些 log 归档的多余数据量。
从 logs 中收集 metric 数据
您的 logs 中包含等待收集的 metrics!即使是 ISV 解决方案或您未自行编写的应用程序也会在其 logs 中输出有价值的数据,您可以从中提取有关整体工作负载健康状况的有意义的洞察。常见示例包括:
- 数据库的慢查询时间
- Web 服务器的正常运行时间
- 事务处理时间
- 一段时间内
ERROR或WARNING事件的计数 - 可升级包的原始计数
当这些数据锁定在静态 log 文件中时用处有限。最佳实践是识别关键 metric 数据,然后将其发布到您的 metric 系统中,在那里可以与其他信号关联。
将 logs 输出到 stdout
在可能的情况下,应用程序应该将 logs 输出到 stdout 而不是固定位置(如文件或 socket)。这使 log 代理能够根据对您的可观测性解决方案有意义的规则来收集和路由您的 log 事件。虽然并非对所有应用程序都可�行,但这是容器化工作负载的最佳实践。
虽然应用程序在其 logging 实践中应该是通用和简单的,与 logging 解决方案保持松耦合,但 log 数据的传输仍然需要 log 收集器将数据从 stdout 发送到文件。重要的概念是避免应用程序和业务逻辑依赖于您的 logging 基础设施——换句话说,您应该努力分离关注点。
将应用程序与 log 管理解耦,使您能够在不更改代码的情况下调整和发展您的解决方案,从而最大限度地减少对环境进行更改的潜在影响范围。