Traces
Traces 表示请求在遍历应用程序不同组件时的整个旅程。
与 logs 或 metrics 不同,traces 由来自多个应用程序或服务的事件组成,并包含服务之间连接的上下文信息,如响应延迟、服务故障、请求参数和元数据。
Logs 和 traces 之间存在概念上的相似性,但 trace 旨在在跨服务上下文中考虑,而 logs 通常限于单个服务或应用程序的执行。
插桩所有集成点
当您的工作负载功能和代码都在一个地方时,查看源代码来了解请求如何在不同函数之间传递是很容易的。在系统层面,您知道应用程序运行在哪台机器上,如果出了问题,可以快速找到根本原因。想象一下在微服务架构中做同样的事情,其中不同组件松耦合并运行在分布式环境中。登录到众多系统来查看每个互连请求的 logs 是不切实际的,即使不是不可能的。
这就是可观测性可以提供帮助的地方。插桩是提高可观测性的关键步骤。广义上讲,插桩是使用代码来测量应用程序中的事件。
典型的插桩方法是为进入系统的每个请求分配一个唯一的 trace 标识符,并在通过不同组件时携带该 trace ID,同时添加额外的元数据。
从一个服务到另一个服务的每个连接都应该被插桩以向中央收集器发出 traces。这种方法帮助您看到工作负载中原本不透明的方面。
当使用自动插桩代理或库时,插桩您的应用程序在很大程度上可以是一个自动化过程。
事务时间和状态很重要,所以要测量它!
一个经过良好插桩的应用程序可以产生端到端的 trace,可以作为瀑布图查看,如下所示:

或者作为服务地图:
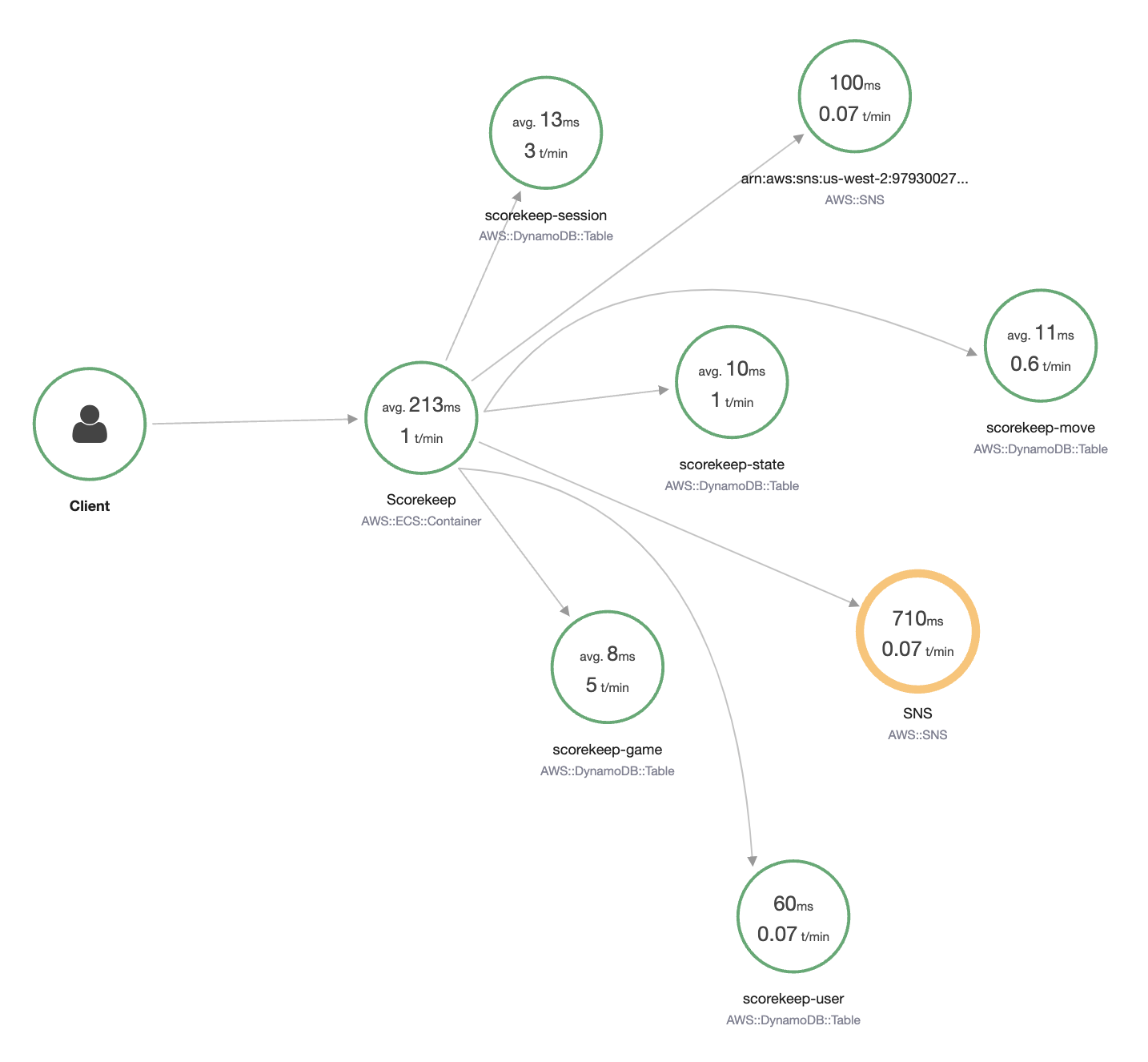
测量每个交互的事务时间和响应代码非常重要。这将有助于计算整体处理时间并跟踪其是否符合您的 SLA、SLO 或业务 KPI。
只有通过理解和记录交互的响应时间和状态码,您才能看到影响整体请求模式和工作负载健康状况的因素。
元数据、注解和标签是您的好帮手
Traces 会被持久化并分配一个唯一 ID,每个 trace 被分解为 spans 或 segments(取决于您使用的工具),记录请求路径中的每个步骤。一个 span 表示 trace 与之交互的实体,与父 trace 一样,每个 span 被分配一个唯一 ID 和时间戳,还可以包含额外的数据和元数据。这些信息对调试很有用,因为它可以告诉您问题发生的确切时间和位置。
通过一个实际例子可以更好地说明这一点。一个电子商务应用程序可能被分为许多领域:认证、授权、配送、库存、支付处理、履行、产品搜索、推荐等等。与其搜索所有这些互连领域的 traces,不如用客户 ID 标记您的 trace,这样您就可以只搜索特定于这一个人的交互。这有助于在诊断运营问题时立即缩小搜索范围。
虽然命名约定可能因供应商而异,但每个 trace 都可以通过元数据、标签或注解进行增强,这些在您的整个工作负载中是可搜索的。添加它们确实需要您编写代码,但可以极大地提高工作负载的可观测性。
Traces 不是 logs,因此请谨慎选择在 traces 中包含的元数据。而且 trace 数据不适用于取证和审计,即使采样率很高也是如此。