Startup Observability Adoption Stages
スタートアップの Observability 導入ステージは、スタートアップが Observability 機能を評価し進化させるための構造化されたフレームワークを提供します。このフレームワークは 3 つの明確なステージにわたり、それぞれが前のステージの上に構築され、運用の可視性を段階的に高めていきます。
すべての段階を通じて、組織は基本原則として継続的なレビューとコスト最適化に焦点を当て続ける必要があります。
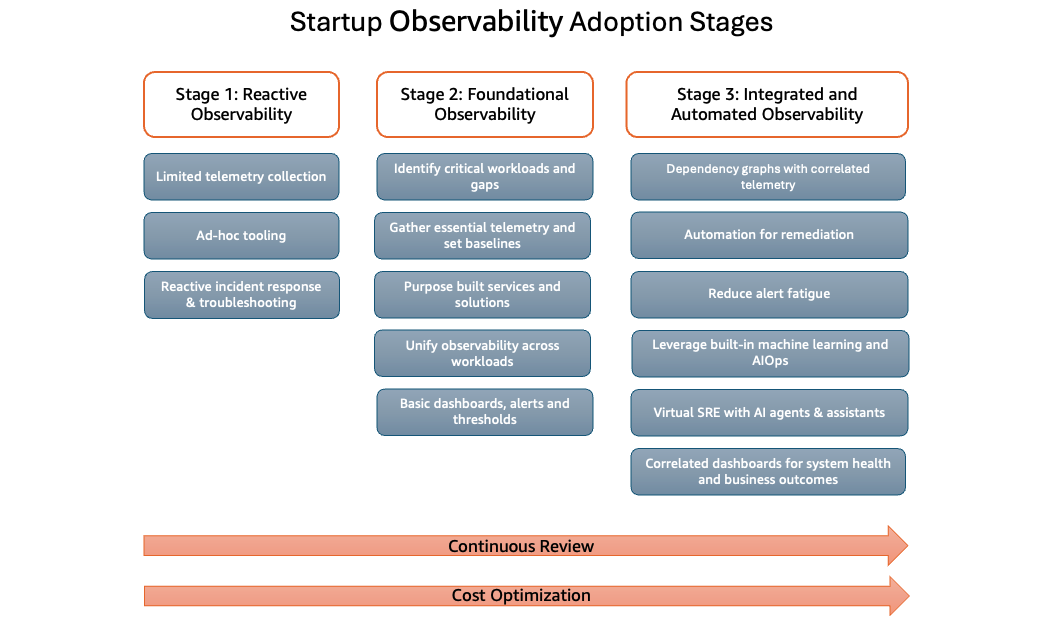
ステージ 1: リアクティブな可観測性
これは、オブザーバビリティの実践が主に反応的な性質を持つ、ほとんどのスタートアップの出発点です。この段階の組織は、通常、限られたリソースで運営され、主に即座の運用ニーズに焦点を�当てています。
主な特徴
- 限定的なテレメトリ収集: 基本的なメトリクス、ログ、トレースは収集されますが、カバレッジは不完全で、システム全体で一貫性がないことがよくあります。データ収集は時折行われるか、最も重要なコンポーネントのみに焦点を当てている場合があります。
- 場当たり的なツール: モニタリングソリューションは必要に応じて実装されるため、異なるチーム間でツールセットが断片化することがよくあります。チームは、無料枠の提供、標準化されていないオープンソースソリューション、または統合が限定的または統合されていないクラウドプロバイダーの組み込みツールに依存する場合があります。
- 事後対応型のインシデント対応とトラブルシューティング: 問題は通常、プロアクティブな検出ではなく、顧客からの苦情やシステム障害を通じて発見されます。トラブルシューティングは手動で、時間がかかり、個々のチームメンバーの知識と専門知識に依存します。
一般的な課題
- 検出までの平均時間 (MTTD) と解決までの平均時間 (MTTR) の延長。
- 問題の再現と診断の困難さ。
- トレンド分析のための履歴データの制限。
- エンジニアリングチーム内の知識のサイロ�化。
ステージ 2: 基礎的なオブザーバビリティ
このステージは、リアクティブなアプローチから意図的なオブザーバビリティ戦略への移行を示します。スタートアップは、モニタリングに対する体系的なアプローチの実装を開始し、スケーラブルなオブザーバビリティプラクティスの基盤を確立します。
主な特徴
-
重要なワークロードとギャップの特定: スタートアップは、カスタマーエクスペリエンス、収益、またはコアオペレーションに最も大きな影響を与えるシステムなど、重要なワークロードを定義することから始め、ビジネスと技術の関係者間の協力を通じて既存のオブザーバビリティのギャップを分析する必要があります。体系的なチェックリストまたはテンプレートを構築することが推奨されます。
- 重要なフロー (e コマーススタートアップの場合、サインアップ、チェックアウト、決済処理など) を定義する体系的なチェックリストを構築し、関連するサービス、データストア、依存関係をマッピングします。
- 説明責任のためにエンジニアリングとビジネスのオーナーを割り当て、各ワークロードの主要な技術�シグナル (レイテンシー、エラー、使用率メトリクス) を定義し、メトリクス、ログ、またはトレースが欠落しているか、サイロ化されている箇所にフラグを立てます。
- 注文完了率やチェックアウト放棄率などのビジネス KPI を各ワークロードにマッピングし、技術とビジネスの両方の観点から完全なオブザーバビリティカバレッジを確保します。
-
重要なテレメトリを収集しベースラインを設定する: メトリクス、ログ、トレースを収集することで、ビジネスチームとエンジニアリングチームがワークロードのパフォーマンスを統一的に把握でき、異常の早期検出と根本原因分析の迅速化が可能になります。時間の経過とともに、この相関データは正常な動作の理解を深め、アラートしきい値の微調整とノイズの削減を容易にします。スタートアップは、3 つのコアカテゴリにわたって一貫したメトリクスの追跡を開始する必要があります。
- コアサービスヘルス リソース使用率 (CPU、メモリ、DB 接続など)、レイテンシー (p95/p99 レスポンスタイムなど)、トラフィック (秒あたりのリクエスト数など)、エラー率 (4xx/5xx など) を含みます。
- 信頼性と可用性 稼働時間と SLO、インシデントメトリクス (MTTR、アラート量など)、顧客影響指標 (失敗したユーザーアクション、サポートチケットなど) をカバーします。
- プロダクトとビジネスメトリクス 収益率、トランザクション成功率、解約率と維持率、アクティブセッション、テナントあたりのコストなど、スタートアップの特定の業界とドメインに合わせて調整されたメトリク��スです。
-
目的別のサービスとソリューション: マネージド型の AWS オブザーバビリティプラットフォームを活用することで、運用オーバーヘッドが大幅に削減され、スタートアップにおけるオブザーバビリティの導入が加速されます。メトリクスとログ用の Amazon CloudWatch と、分散トレーシング用の AWS X-Ray を組み合わせることで、最小限の設定で深いリアルタイムの可視性が実現されます。CloudWatch Container Insights、Lambda Insights、Database Insights などの目的別機能により、特定のワークロードタイプに対する監視設定が容易になります。フルマネージドサービスは、コレクター、ストレージ、可視化ツールのプロビジョニング、スケーリング、セキュリティ保護を処理し、組み込みのアラート、ダッシュボード、分析機能を提供することで、カスタムパイプラインの必要性を排除します。コア AWS サービスとの緊密な統合により、ワークロードの進化に伴い、インサイトからアクションへのループが高速化されます。コストの観点からは、従量課金制の料金体系と、プロビジョニング、スケーリング、セキュリティ保護、アップグレードが必要なクラスターがないなど、監視インフラストラクチャを管理しないことによる隠れたコスト削減により、SRE および DevOps チームは、オブザーバビリティインフラストラクチャではなく、製品機能と顧客体験に集中する機会が得られます。
-
ワークロード全体で可観測性を統一する: 可観測性は、チーム、製品、または環境ごとに断片化されるのではなく、すべてのワークロードにわたって統一された機能として実装された場合に、スタートアップにとって最も効果的です。サイロ化されたツール、一貫性のないデータスキーマ、および異なるテレメトリプロトコルにより、ユーザー向けの症状から根本原因まで問題を追跡することが困難になります。この断片化により、インシデントの検出と解決の平均時間が増加します。共有データモデル、一貫した命名規則、および OpenTelemetry などの標準フレームワークを通じてテレメトリを標準化することで、メトリクス、ログ、およびトレースをサービスと環境全体で確実に関連付けることができます。Amazon CloudWatch などの拡張可能な可観測性プラットフォームを採用することで、単一の信頼できる情報源を提供し、複数のツールの複雑さを軽減し、ビジネスの拡大に伴ってより迅速で信頼性の高いインシデントの検出と解決をサポートします。
-
基本的なダッシュボード、アラート、しきい値: 基本的なダッシュボード、アラート、しきい値の定義は、スタートアップにとって運用可視性の最初の構造化されたレイヤーを形成します。Amazon CloudWatch は、コア AWS サービスのメトリクス、定義されたしきい値に対してメトリクスを評価するアラーム、リージョンやアカウント全体のシステムヘルスを可視化するダッシュボードなど、すぐに使える重要な機能を提供します。この基盤により、チームは顧客からの苦情を通じて問題を発見することから、インフラストラクチャとアプリケーションのシグナルを通じて問題を検出することへと移行できます。主要なメトリクス、アラーム状態、トレンドを表示する共有 CloudWatch ダッシュボードは、エンジニア、プロダクトマネージャー�、リーダーにシステムヘルスの共通理解を提供し、Amazon SNS やインシデントツールと統合された CloudWatch アラームは、しきい値違反時に即座に通知を提供します。CloudWatch 推奨アラームは、マネージドサービスのベストプラクティスメトリクスとしきい値をチームが特定するのに役立ちます。これらのプリミティブに早期に投資することで、スタートアップは、監視基盤の複雑なリファクタリングを必要とせずに、少数のサービスから複雑なアーキテクチャまでスケールする一貫した運用インターフェースを作成できます。
一般的な結果
- インシデント対応時間の短縮。
- チーム間のコラボレーションと知識共有の改善。
- 運用手順の標準化。
- データ駆動型の意思決定のための基盤。
ステージ 3: 統合された自動化されたオブザーバビリティ
統合された自動化されたオブザーバビリティは、スタートアップが高度なツール、自動化、機械学習を活用して運用の卓越性を達成する、成熟したオブザーバビリティプラクティスを表します。オブザーバビリティは、技術運用とビジネス戦略の両方に深く統合されます。
主な特徴
-
相関するテレメトリを使用した依存関係グラフ: Amazon CloudWatch Application Signals、Application Maps、AWS X-Ray トレースマップなどの AWS オブザーバビリティサービスを活用して、サービス、ダウンストリームの依存関係、クロスアカウントのインタラクションを自動的に検出し、可視化します。この依存関係グラフは、サービス、データストア、外部 API、インフラストラクチャコンポーネントを接続する軽量なナレッジグラフとして機能します。この基盤に SLO とクリティカルパスを組み合わせることで、チームは影響範囲を迅速に評価し、変更、デプロイ、インシデント発生時の潜在的な影響を理解し、問題が顧客に到達する前にリスクを軽減するためのプロアクティブなアクションを実行する能力を獲得します。
-
修復の自動化: AWS オブザーバビリティサービスを使用して繰り返し発生するアラートを分析し、自動修復ワークフローを実装することで、運用オーバーヘッドを削減し、一貫したインシデント対応を確保します。Amazon EventBridge、AWS Lambda、AWS Systems Manager などの AWS サービスを連携させて、定義されたアラート条件に基づいて自動修復アクションをトリガーおよび実行します。Amazon CloudWatch ダッシュボードと Amazon SNS やチャットプラットフォームなどの統合通知チャネルを通じて高シグナルのアラートを表示することで、チームがランブッ�クを反復的に改善し、シグナル対ノイズ比を向上させ、日常的なインシデント処理における手動介入を最小限に抑えることができます。
-
アラート疲労を軽減する: 低レベルのシグナルではなく、明確に定義されたビジネス目標と信頼性目標を中心にアラート戦略を設計します。アラートを重要なサービス、SLO、顧客に影響を与える動作にマッピングし、持続的または重大な逸脱に対してのみトリガーされるようにしきい値を調整します。関連する条件をより高レベルのアラームにグループ化して関連付け、適切な場合は動的または異常ベースのしきい値を適用し、既知のメンテナンスウィンドウ中はアラートを抑制して、通知を実際のインシデントに集中させます。各アラートクラスの重大度レベル、所有権、対応期待値を定義してガバナンスを確立し、可用性、パフォーマンス、またはコストに実質的に影響を与えるイベントに対してのみ運用上の注意が向けられるようにします。
-
組み込みの機械学習と AIOps を活用する: スタートアップは、AWS オブザーバビリティサービス内の組み込み機械学習機能を活用して、最小限のセットアップで生のテレメトリを実用的なインサイトに変換する必要があります。AIOps 機能により、少人数のチームでも問題を早期に検出し、トラブルシューティングを迅速に行い、カスタム検出パイプラインの維持や複雑なアラートルールの手動作成ではなく、製品開発にエンジニアリングリソースを集中させることができます。AWS オブザーバビリティサービスは、多くの組み込み機械学習機能を提供しています。
- CloudWatch Anomaly Detection は、通常のベースラインを自動的に学習し、季節性を考慮し、静的なしきい値なしで異常な動作を表面化することで、パフォーマンスの低下や信頼性の問題を早期に検出できます。
- CloudWatch Outlier Detection は、システムとアプリケーションのメトリクスを継続的に分析し、通常のベースラインを決定し、最小限のユーザー介入で異常を表面化します。
- CloudWatch Log Anomaly Detection は、ログ内のパターンを自動的に認識してクラスタリングし、新しい、予期しない、または頻繁なエラーなどの異常を識別します。トークンのバリエーション、新しいログパターン、頻度の変化を検出でき、問題の診断を迅速に行うのに役立ちます。
- CloudWatch Log Insights は、自然言語を使用して CloudWatch Logs Insights クエリを生成、更新、または要約し、特定のクエリ構文を知らなくても質問できるようにします。
- X-Ray Insights は、アプリケーションパフォーマンスの異常を自動的に検出し、分散サービス全体の問題の根本原因を特定し、手動のトレース分析なしで障害パターンと応答時間の低下を強調表示します。
- CloudWatch Investigations は、システムのインシデントへの対応を支援する生成 AI 駆動のアシスタントを提供します。生成 AI を使用してシステムのテレメトリをスキャンし、問題に関連する可能性のあるテレメトリデータと提案を迅速に表面化します。
- DevOps Guru は、機械学習を適用して異常な動作を検出し、推奨される修復アクションとともに優先順位付けされた運用インサイトを生成します。
-
AI エージェントとアシスタントによる仮想 SRE: CloudWatch Application Signals MCP Server を使用すると、AI エージェントが Application Signals にクエリを実行することで、AWS サービスの仮想 SRE として機能できます。サービスの健全性の監査、SLO コンプライアンスの追跡、オペレーションレベルのパフォーマンス分析、トレース、メトリクス、ログ、変更イベントを使用した問題の調査など、すべて自然言語で実行できるツールを公開します。これにより、スタートアップチームは、CloudWatch や X-Ray のクエリを手動で記述することなく、IDE や AI アシスタントから直接、より迅速な根本原因分析、より優れた SLO モニタリング、豊富なオブザーバビリティワークフローを実現できます。
-
システムヘルスとビジネス成果の相関ダッシュボード: システムヘルスとビジネス成果を結びつける相関ダッシュボードは、オブザーバビリティを運用ツールから戦略的機能へと変革します。これらのダッシュボードは、テレメトリを技術的シグナルと顧客または収益への影響という 2 つの視点で提示するため、レイテンシーのスパイクやエラーが、ユーザージャーニーの低下やトランザクション完了率の減少として即座に可視化されます。少人数のチームにとって、これらのダッシュボードは、メトリクス、ログ、トレース、実ユーザーデータを単一のペインに統合することで、インフラストラクチャ中心の監視と製品中心の意思決定を橋渡しします。SRE、プロダクトマネージャー、リーダーシップは、インシデント発生時やレビュー時に同じ真実に基づいて作業を行うため、摩擦が減少��し、学習が加速されます。スタートアップが成長するにつれて、この相関ビューは異常検知、AI 支援診断、自動修復の基盤となり、チームが自律的で影響を認識するオブザーバビリティシステムの監督へと移行できるようにします。
一般的な結果
- 手動運用オーバーヘッドの大幅な削減。
- 問題の予防と予測の積極的な実施。
- 技術的な意思決定がビジネスに与える影響の明確な可視化。
- AI/ML を活用した機能によるリソース割り当てとコスト効率の最適化。
- 信頼性の向上による顧客体験の強化。
横断的な考慮事項
継続的なレビュー
すべての導入段階にあるスタートアップは、オブザーバビリティの実践、ツールの有効性、および進化するビジネスニーズとの整合性を定期的に評価する必要があります。この反復的なアプローチにより、オブザーバビリティ機能が組織とともに成長することが保証されます。
コスト最適化
オブザーバビリティへの投資は、その価値提供とバランスを取る必要があります。これには、データ保持期間の適正化、テレメトリ収集の最適化、適切な価格ティアの活用、冗長なツールの排除が含まれ、成熟度の向上過程全体を通じてコスト効率を維持します。
進行に関する考慮事項
スタートアップは、オブザーバビリティを反復的な機能として扱い、テレメトリと分析の要件が十分に特徴付けられる前に、高コストなツールへの大規模な初期投資を避けるべきです。システムの複雑さとトラフィックパターンが進化するにつれて、チームは定期的にオブザーバビリティの態勢を再評価し、サンプリングと保持ポリシーを調整し、可視性、パフォーマンスオーバーヘッド、コストの間の適切なバランスを維持するために、ツールスタックを段階的に進化させることができます。
これらの段階を通じた進歩は厳密に線形ではなく、組織は異なるシステムやチーム間で複数の段階の特性を同時に示す場合があります。適切な進歩のペースは、以下を含む要因に依存します。
- スタートアップの成長率とスケーリング要件
- 利用可能なエンジニアリングリソースと専門知識
- 予算の制約と投資の優先順位
- 規制とコンプライアンスの義務
組織は現在の状態を評価し、ビジ��ネスへの影響に基づいて改善の優先順位を付け、運用ニーズと戦略目標に沿ってオブザーバビリティの導入を進めるために段階的に投資する必要があります。