AWS におけるビッグデータのオブザーバビリティ
この図は、AWS 上の Spark ビッグデータワークフローにオブザーバビリティを実装するためのベストプラクティスパターンを示しています。このパターンは、Spark ジョブによって生成��されるログとメトリクスを収集、処理、分析するために、さまざまな AWS サービスを活用します。
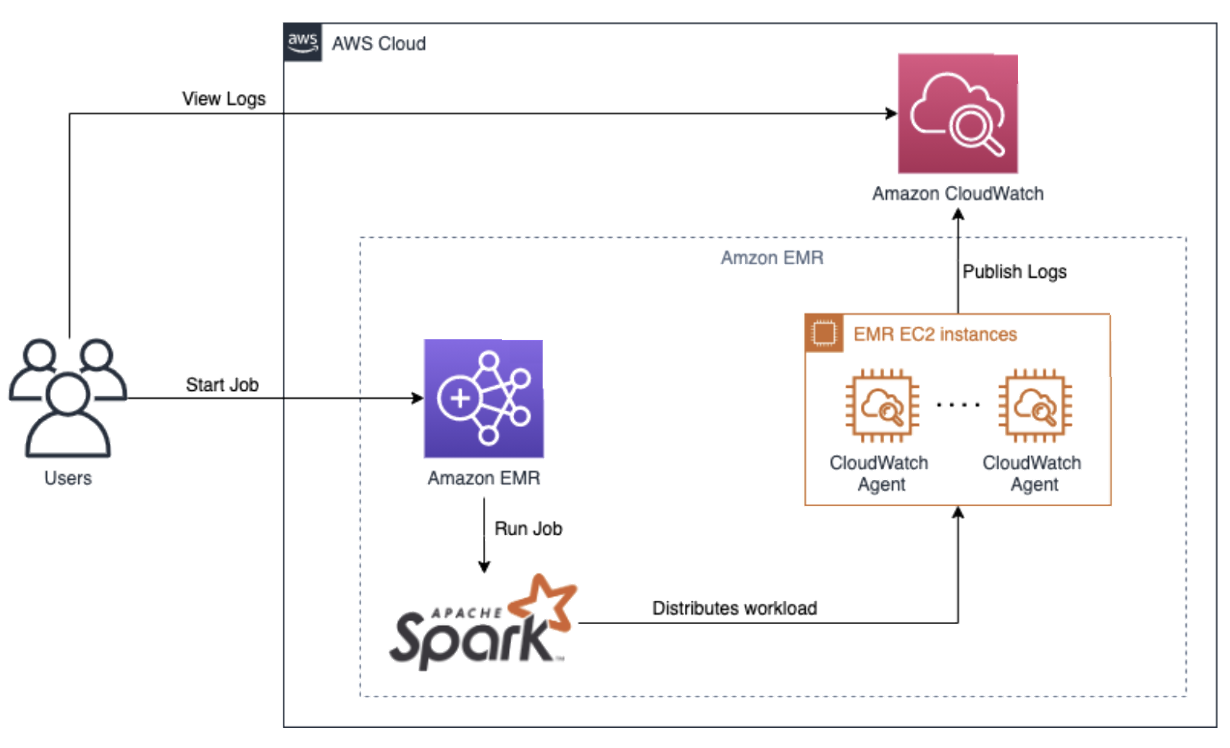 図 1: Spark ビッグデータのオブザーバビリティ
図 1: Spark ビッグデータのオブザーバビリティ
ワークフロー
- ユーザーが Amazon EMR クラスターに Spark ジョブを送信します。
- Amazon EMR クラスターが Spark ジョブを実行し、Apache Spark を使用してクラスター全体にワークロードを分散します。
- Spark ジョブの実行中に、ログとメトリクスが生成され、Amazon CloudWatch と Amazon EMR によって収集されます。
オブザーバビリティコンポーネント
Amazon EMR
Amazon EMR は、AWS 上で Apache Spark などのビッグデータフレームワークの実行を簡素化するマネージドサービスです。大量のデータを処理するためのスケーラブルでコスト効率の高いプラ��ットフォームを提供します。
Amazon CloudWatch
Amazon CloudWatch は、さまざまな AWS リソースやアプリケーションからメトリクス、ログ、イベントを収集して追跡する監視およびオブザーバビリティサービスです。このパターンでは、CloudWatch は次の目的で使用されます。
- Spark ジョブを実行している EMR EC2 インスタンスからログとメトリクスを収集します。
- 収集したログを Amazon CloudWatch Logs に発行して、一元的なログ管理と分析を行います。
EMR EC2 インスタンス
Spark ジョブは EMR EC2 インスタンスで実行されます。これらは EMR クラスターのコンピューティングノードです。これらのインスタンスはログとメトリクスを生成し、CloudWatch Agent によって収集されて Amazon CloudWatch に送信されます。
ベストプラクティス
AWS 上の Spark ビッグデータワークロードの効果的なオブザーバビリティを確保するには、以下のベストプラクティスを考慮してください。
-
一元化されたロ�グ管理: Amazon CloudWatch Logs を使用して、Spark ジョブと EMR インスタンスによって生成されたログの収集、保存、分析を一元化します。これにより、Spark ワークフローのトラブルシューティングと監視が容易になります。
-
メトリクスの収集: CloudWatch Agent を活用して、EMR EC2 インスタンスから CPU 使用率、メモリ使用量、ディスク I/O などの関連メトリクスを収集します。これらのメトリクスは、Spark ジョブのパフォーマンスと健全性に関する洞察を提供します。
-
ダッシュボードとアラーム: CloudWatch ダッシュボードを作成して、主要なメトリクスとログをリアルタイムで可視化します。CloudWatch アラームを設定して、特定のしきい値や異常が検出されたときに通知とアラートを送信し、プロアクティブな監視とインシデント対応を可能にします。
-
ログ分析: Amazon CloudWatch Logs Insights を利用するか、他のログ分析ツールと統合して、アドホッククエリの実行、問題のトラブルシューティング、収集されたログからの貴重なインサイトの取得を行います。
-
パフォーマンスの最適化: 収集されたメトリクスとログを使用して、Spark ジョブのパフォーマンスを継続的に監視および分析します。ボトルネックを特定し、リソース割り当てを最適化し、Spark 設定を調整して、ビッグデータワークロードの効率とパフォーマンスを向上させます。
このオブザーバビリティパターンを実装し、ベストプラクティスに従うことで、組織は AWS 上の Spark ビッグデータワークロードを効果的に監視、トラブルシューティング��、最適化でき、大規模で信頼性が高く効率的なデータ処理を確保できます。