アラーム
アラームとは、プローブ、モニター、または特定のしきい値を超えた(または下回った)値の変化の状態を指します。シンプルな例として、ディスクが一杯になった時やウェブサイトがダウンした時にメールを送信するアラームがあります。より高度なアラームは完全にプログラム化されており、自動スケーリングやサーバークラスタ�ー全体の作成などの複雑な相互作用を駆動するために使用されます。
ただし、ユースケースに関係なく、アラームはメトリクスの現在の 状態 を示します。この状態は、対象のシステムに応じて OK、WARNING、ALERT、または NO DATA となります。
アラームは一定期間この状態を反映し、時系列データの上に構築されています。そのため、時系列データ から 派生したものです。以下のグラフは 2 つのアラームを示しています:1 つは警告しきい値を持つアラーム、もう 1 つはこの時系列データの平均値を示すアラームです。このトラフィック量が示すように、警告しきい値のアラームは、定義された値を下回った時に違反状態になるはずです。
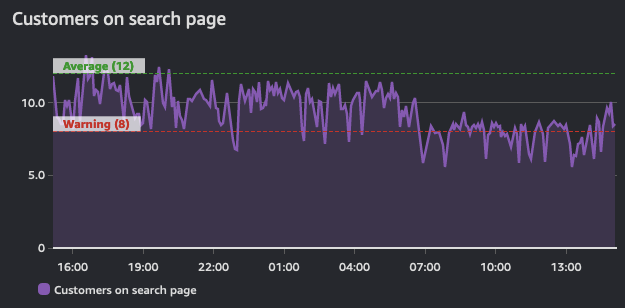
アラームの目的は、アクション(人的またはプログラム的)をトリガーすること、またはしきい値違反の情報を提供することです。アラームはメトリクスのパフォーマンスに関する洞察を提供します。
アクショ�ンにつながるものにアラートを設定する
アラーム疲れとは、人々があまりにも多くのアラートを受け取るため、それらを無視するようになってしまう状態です。これは適切にモニタリングされているシステムの特徴ではありません!むしろ、これはアンチパターンです。
アクションにつながるものにアラームを作成し、常に目的から逆算して考える必要があります。
例えば、迅速なレスポンスタイムが必要な Web サイトを運用している場合、レスポンスタイムが特定のしきい値を超えた時にアラートを送信するように設定します。また、パフォーマンスの低下が CPU 使用率の上昇と関連していることが分かっている場合は、問題が発生する前に 事前に このデータポイントでアラートを設定します。しかし、目的に 影響を与えない 場合は、環境内の すべての CPU 使用率についてアラートを設定する必要はないかもしれません。
アラームがアラートを必要としない、または自動化プロセスをトリガーする必要がない場合、アラートを設定する必要はありません。不要なアラームからは通知を削除するべきです。
「すべて OK アラーム」に注意
同様に、一般的なパターンとして「すべて OK アラーム」があります。これは、オペレーターが常に警告を受け取ることに慣れすぎて、突然警告が来なくなった時だけ気付くという状態です! これは非常に危険な運用モードであり、オペレーショナルエクセレンスに反するパターンです。
「すべて OK アラー��ム」は通常、人による解釈が必要です!このため、自己修復アプリケーションのようなパターンが実現できなくなります。1
アラーム疲れを集約で解消する
オブザーバビリティは技術的な問題ではなく、人間 の問題です。そのため、アラーム戦略は、アラームを増やすのではなく、削減することに重点を置くべきです。テレメトリ収集を実装すると、環境からより多くのアラートが発生するのは自然なことです。ただし、アクション可能な事象のみにアラートを設定する よう注意してください。アラートの原因となった状態にアクションを取れない場合、それを報告する必要はありません。
これは例を見るとよく分かります。5 台の Web サーバーがバックエンドに単一のデータベースを使用している場合、データベースがダウンすると Web サーバーはどうなるでしょうか?多くの場合、Web サーバーに対して 5 つ 、データベースに対して 1 つ 、少なくとも 6 つ のアラートが発生します!
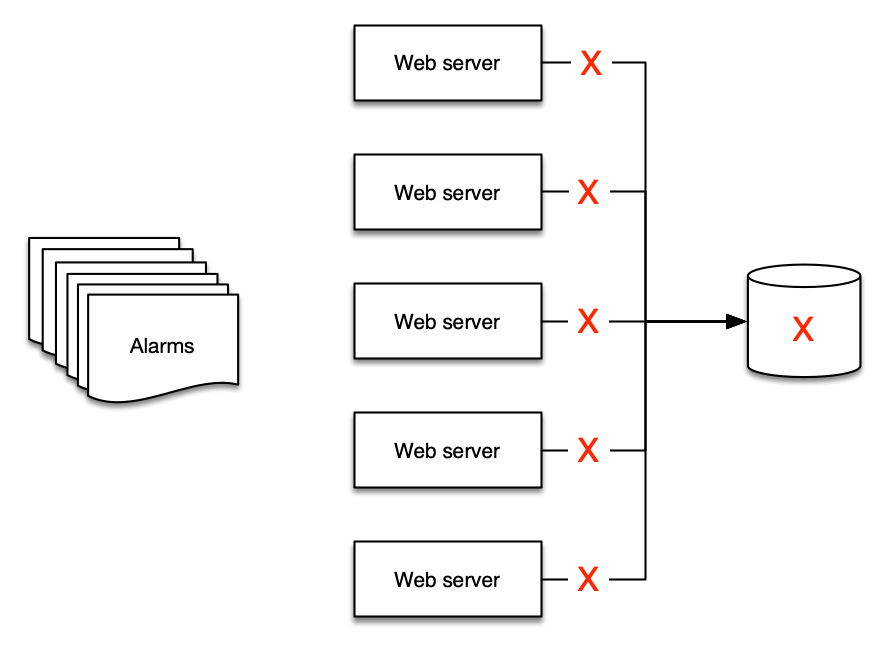
しかし、実際に意味のあるアラートは 2 つだけです:
- Web サイトがダウンしている
- データベースが原因である
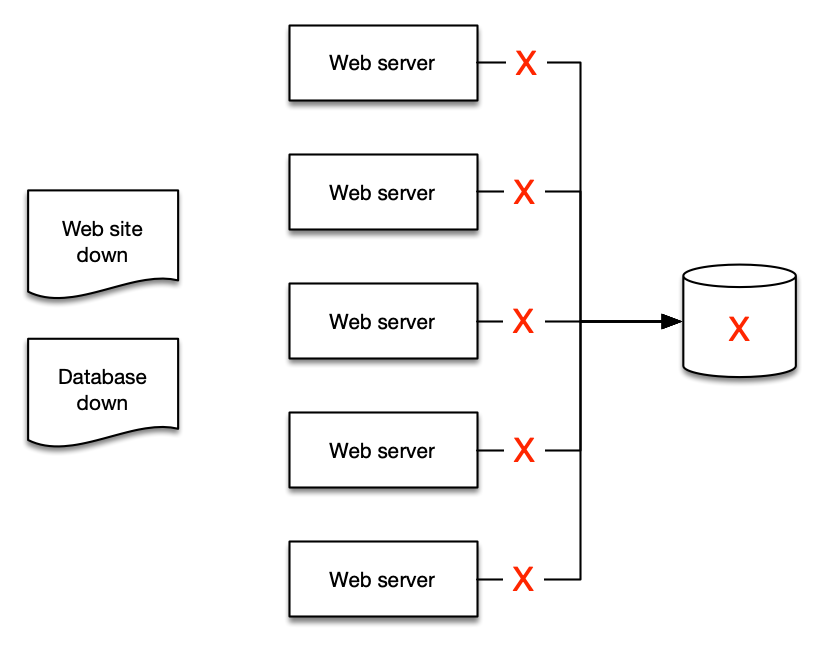
アラートを集約して本質的な情報に絞り込むことで、人々が理解しやすくなり、ランブックや自動化の作成も容易になります。
既存の ITSM とサポートプロセスを活用する
モニタリングとオブザーバビリティのプラットフォームに関係なく、それらは現在のツールチェーンと統合する必要があります。
アラートからこれらのツールへのプログラムによる統合を使用してトラブルチケットや課題を作成し、人的作業を削減しプロセスを効率化します。
これにより、DORA メトリクス などの重要な運用データを取得できます。