イベント
イベントとは何を意味するのでしょうか?
最近では、多くのアーキテクチャがイベント駆動型になっています。イベント駆動型アーキテクチャでは、イベントは異なるシステムからのシグナルであり、それを捕捉して他のシステムに渡します。イベントは通常、状態の変更または更新を表します。
例えば、e コマースシステムでは、商品がカートに追加されたときにイベントが発生する可能性があります。このイベントを捕捉し、システムのショッピングカート部分に渡して、商品の詳細とともにカート内のアイテム数と合計金額を更新することができます。
一部のお客様にとって、イベントは購入完了などの マイルストーン である場合があります。ワークフローの完了時点を集約してイベントとして扱うという考え方もありますが、ここではマイルストーン自体をイベントとは考えません。
イベントが有用な理由
オブザーバビリティソリューションにおいて、イベントが有用な主な方法は 2 つあります。1 つは他のデータのコンテキストでイベントを可視化�すること、もう 1 つはイベントに基づいてアクションを実行できるようにすることです。
イベントは、ワークロードの変更やアクションについて、人間やマシンに価値のある情報を提供することを目的としています。
イベントの可視化
アプリケーションから直接得られるものではありませんが、アプリケーションのパフォーマンスに影響を与えたり、根本原因の分析に役立つイベントシグナルが多数存在します。 ダッシュボードはイベントを可視化する最も一般的な手段ですが、分析やビジネスインテリジェンスツールもこの目的で使用できます。 メールやインスタントメッセージングアプリケーションでも、容易に可視化結果を受け取ることができます。
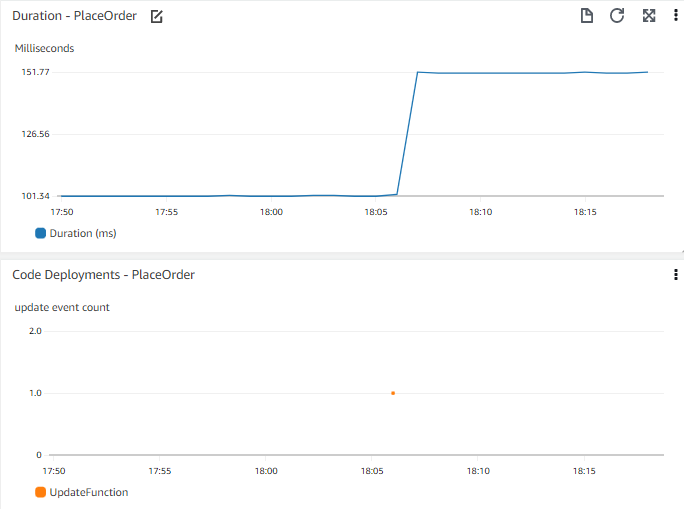
Web フロントエンドでの注文処理時間など、アプリケーションのパフォーマンスを示す時系列チャートを考えてみましょう。 時系列チャートを見ると、数日前にレスポンスタイムが段階的に変化したことがわかります。 最近のデプロイメントの状況を知ることができれば有用かもしれません�。 最近のデプロイメントの時系列チャートを並べて表示したり、同じチャート上に重ねて表示したりすることを検討してみてはいかがでしょうか?
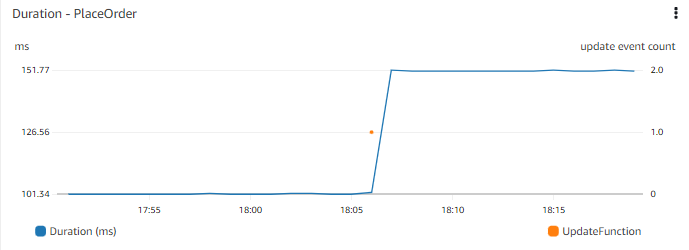
より広い文脈を理解するために、どのようなイベントが有用かを検討してください。 重要なイベントとしては、コードのデプロイメント、インフラストラクチャの変更イベント、新しいデータの追加(販売する新商品の公開や、ユーザーの一括追加など)、機能の変更や追加(カートへの商品追加方法の変更など)が考えられます。
重要なメトリクスデータと共にイベントを可視化することで、イベントの相関関係を把握することができます。
イベントに対するアクション
オブザーバビリティの世界では、アラームのトリガーは一般的なイベントです。このイベントには、アラームの識別子、アラームの状態(IN ALARM や OK など)、トリガーの詳細が含まれます。多くの場合、このアラームイベントが検出され、メール通知が送信されます。これはアラームに対するアクションの一例です。
アラーム通知はオブザーバビリティにおいて重要です。これにより、問題が発生した際に適切な担当者に通知することができます。しかし、オブザーバビリティソリューションでイベントに対するアクションが成熟すると、人の介入なしに問題を自動的に修復することができます。
どのようなアクションを取るべきか?
検出された問題を緩和するためのアクションを��理解せずに、自動化することはできません。 オブザーバビリティの取り組みを始めた段階では、多くの場合それは明確ではありません。 しかし、問題の修復経験を積むほど、既知のアクションが必要な領域を捉えるようにアラームを微調整できるようになります。 アラームサービスに組み込まれたアクションがある場合もあれば、アラームイベントを自身でキャプチャしてスクリプトで解決する必要がある場合もあります。
水平 Pod 自動スケーリング などの自動スケーリングシステムは、このプリンシパルの実装に過ぎません。 Kubernetes は単にこの自動化を抽象化しているだけです。
アラームの頻度と解決に関するデータにアクセスできれば、自動化の可能性を判断するのに役立ちます。 問題の症状に基づく広範囲のアラームは問題の検出に優れていますが、自動修復とリンクさせるにはより具体的な基準が必要になる場合があります。
これを行う際は、インシデント管理/チケット発行/ITSM ツールとの統合を検討してください。 多くの組織では、インシデントとそれに関連する解決策、平均解決時間 (MTTR) などのメトリクスを追跡しています。 �これを行う場合は、自動化された 解決策も同様の方法で記録することを検討してください。 これにより、自動的に修復される問題の種類と割合を理解できるだけでなく、根本的なパターンや問題を探ることもできます。
誰かが手動で問題を修正する必要がなかったからといって、根本的な原因を調査しなくてよいわけではありません。
例えば、サーバーが応答しなくなるたびに再起動する場合を考えてみましょう。 再起動によってシステムは機能し続けることができますが、応答しなくなる原因は何でしょうか。 これがどのくらいの頻度で発生するか、そしてパターン(レポート生成、ユーザー数の増加、システムバックアップなどと一致する)があるかどうかによって、根本原因の理解と修正に投入する優先順位とリソースが決まります。
重要業績評価指標 に関連するすべてのイベントをメッセージバスに配信して使用することを検討してください。 また、一部のオブザーバビリティソリューションでは、明示的な設定要件なしにこれを透過的に行うことに注意してください。
オブザーバビリティプラットフォームへのイベントの取り込み
重要なイベントを特定したら、それらをオブザーバビリティプラットフォームに取り込む最適な方法を検討する必要があります。 プラットフォームには、イベントを取り込むための特定の方法がある場合や、ログやメトリクスデータとして取り込む必要がある場合があります。
イベントを取り込む簡単な方法の 1 つは、イベントをログファイルに書き込み、他のログイベントと同じ方法で取り込むことです。
システムでこれらをどのように可視化できるか検討してください。アプリケーションに関連するイベントを特定できますか?データを 1 つのチャートに統合できますか?特定の方法がない場合でも、少なくとも他のデータと並べて時系列チャートを作成し、視覚的に相関関係を確認できるはずです。時間軸を同じにし、比較しやすいように垂直方向に積み重ねることを検討してください。