ロギング
ロギングツールの選択は、データの送信、フィルタリング、保持、キャプチャ、およびデータ�を生成するアプリケーションとの統合に関する要件に結びついています。 オブザーバビリティのために AWS を使用する場合(オンプレミスまたは他のクラウド環境でホストしているかに関わらず)、CloudWatch エージェント や Fluentd などのツールを活用して、分析用のログデータを送信できます。
ここでは、ロギング用の CloudWatch エージェントの実装と、AWS コンソールまたは API 内での CloudWatch Logs の使用に関するベストプラクティスについて詳しく説明します。
CloudWatch エージェントを使用したログの収集
転送
クラウドファーストアプローチ によるオブザーバビリティでは、原則として、ログを取得するためにマシンにログインする必要がある場合、それはアンチパターンとなります。 ワークロードは、ログ分析システムにほぼリアルタイムでログデータを送信する必要があり、送信とイベント発生の間の遅延は、ワークロードに災害が発生した場合に、その時点の情報が失われる可能性を意味します。
アーキテクトとして、許容可能なログデータの損失を判断し、それに応じて CloudWatch エージェントの force_flush_interval を調整する必要があります。
force_flush_interval は、バッファサイズに達しない限り、エージェントに定期的にログデータをデータプレーンに送信するよう指示します。
バッファサイズに達した場合は、バッファされたすべてのログを直ちに送信します。
エッジデバイスは、AWS 内の低レイテンシーワークロードとは大きく異なる要件を持つ場合があり、より長い force_flush_interval 設定が必要になる場合があります。
例えば、低帯域幅のインターネット接続を使用する IoT デバイスでは、15 分ごとにログをフラッシュするだけで十分な場合があります。
コンテナ化されたワークロードやステートレスワークロードは、ログのフラッシュ要件に特に敏感な場合があります。
いつでもスケールインできるステートレスな Kubernetes アプリケーションや EC2 フリートを考えてみてください。
これらのリソースが突然終了した場合、将来ログを抽出する方法がなくなり、ログが失われる可能性があります。
標��準の force_flush_interval は通常これらのシナリオに適していますが、必要に応じて短縮することができます。
ロググループ
CloudWatch Logs では、アプリケーションに論理的に適用されるログのコレクションは、1 つの ロググループ に配信される必要があります。そのロググループ内では、ログストリームを作成するソースシステム間に 共通性 が必要です。
LAMP スタックを例に考えてみましょう。Apache、MySQL、PHP アプリケーション、ホスティング Linux オペレーティングシステムからのログは、それぞれ別のロググループに属します。
このグループ化は重要です。保持期間、暗号化キー、メトリクスフィルター、サブスクリプションフィルター、Contributor Insights ルールを同じように扱うことができるためです。
ロググループ内のログストリーム数に制限はなく、CloudWatch Logs Insights クエリを使用して、アプリケーションのすべてのログを一度に検索できます。Kubernetes サービスの各 Pod や、フリート内の各 EC2 インスタンスに対して個別のログストリームを持つことは、標準的なパターンです。
ロググループのデフォルトの保持期間は 無期限 です。ベストプラクティスは、ロググループ作成時に保持期間を設定することです。
CloudWatch コンソールでいつでも設定できますが、ベストプラクティスとしては、Infrastructure as Code (CloudFormation、Cloud Development Kit など) を使用してロググループ作成と同時に設定するか、CloudWatch エージェント設定内の retention_in_days 設定を使用することをお勧めします。
いずれのアプローチでも、プロジェクトのデータ保持要件に合わせて、ログ保持期間を事前に設定できます。
ロググループのデータは CloudWatch Logs で常に暗号化されます。デフォルトでは、CloudWatch Logs は保管時のログデータに対して サーバーサイド 暗号化を使用します。代替として、この暗号化に AWS Key Management Service を使用することもできます。AWS KMS を使用した暗号化 は、ロググループの作成時または作成後に KMS キーをロググループに関連付けることで、ロググループレベルで有効化されます。これは Infrastructure as Code (CloudFormation、Cloud Development Kit など) を使用して設定できます。
CloudWatch Logs のキー管理に AWS Key Management Service を使用するには、追加の設定とユーザーへのキーに対する権限付与が必要です。1
ログのフォーマット
CloudWatch Logs は、取り込み時に自動的にログフィールドを検出し、JSON データをインデックス化する機能を持っています。 この機能により、アドホッククエリとフィルタリングが容易になり、ログデータの使いやすさが向上します。 ただし、自動インデックス化は構造化データにのみ適用されることに注意してください。 非構造化ログデータは自動的にインデックス化されませんが、CloudWatch Logs に配信することは可能です。
非構造化ログは、parse コマンドを使用して正規表現で検索やクエリを実行することができます。
CloudWatch Logs を使用する際のログフォーマットに関する 2 つのベストプラクティス:
- Log4j、
python-json-logger、またはフレームワーク固有の JSON エミッターなどの構造化ログフォーマッターを使用する。 - ログの出力先に 1 イベントにつき 1 行のログを送信する。
複数行の JSON ログを送信する場合、各行が 1 つのイベントとして解釈されることに注意してください。
stdout の取り扱い
ログシグナル のページで説明したように、ベストプラクティスはロギングシステムをアプリケーションから切り離すことです。しかし、stdout からファイルにデータを送信することは、多くのプラットフォームで一般的なパターンです。
Kubernetes や Amazon Elastic Container Service などのコンテナオーケストレーションシステムは、stdout からログファイルへの配信を自動的に管理し、コレクターから各ログを収集できるようにします。CloudWatch エージェントはこのファイルをリアルタイムで読み取り、データをロググループに転送します。
可能な限り、エージェントによる収集と組み合わせて、stdout へのシンプルなアプリケーションロギングのパターンを使用してください。
ログのフィルタリング
個人データの永続的な保存を防ぐ場合や、特定のログレベルのデータのみを取得する場合など、ログをフィルタリングする理由は多くあります。 いずれの場合も、発生源システムにできるだけ近い場所でフィルタリングを実行することがベストプラクティスです。 CloudWatch の場合、これは分析のために CloudWatch Logs にデータが配信される 前 を意味します。 CloudWatch エージェントはこのフィルタリングを実行できます。
filters 機能を使用して、必要なログレベルを include し、クレジットカード番号や電話番号など、望ましくないパターンを exclude します。
ログに漏洩する可能性のある既知のデータの特定の形式をフィルタリングすることは、時間がかかり、エラーが発生しやすい場合があります。 ただし、特定の種類の望ましくないデータ(クレジットカード番号、社会保障番号など)を扱うワークロードの場合、これらのレコードのフィルターを設定することで、将来の潜在的なコンプライ�アンス問題を防ぐことができます。 たとえば、社会保障番号を含むすべてのレコードを削除するには、次のような簡単な設定で実現できます:
"filters": [
{
"type": "exclude",
"expression": "\b(?!000|666|9\d{2})([0-8]\d{2}|7([0-6]\d))([-]?|\s{1})(?!00)\d\d\2(?!0000)\d{4}\b"
}
]
マルチライン ロギング
すべてのロギングのベストプラクティスは、個別のログイベントごとに 1 行を出力する 構造化ロギング を使用することです。
しかし、この選択肢がない多くのレガシーシステムや ISV サポートのアプリケーションが存在します。
これらのワークロードでは、マルチライン対応のプロトコルを使用して出力しない限り、CloudWatch Logs は各行を個別のイベントとして解釈します。
CloudWatch エージェントは multi_line_start_pattern ディレクティブを使用してこれを実行できます。
CloudWatch Logs へのマルチラインログの取り込みを容易にするために、multi_line_start_pattern ディレクティブを使用してください。
ログクラスの設定
CloudWatch Logs では、2 つのクラスのロググループを提供しています:
-
CloudWatch Logs Standard ログクラスは、リアルタイムモニタリングが必要なログや頻繁にアクセスするログのための、フル機能を備えたオプションです。
-
CloudWatch Logs Infrequent Access ログクラスは、ログを費用対効果の高い方法で統合できる新しいログクラスです。このログクラスは、管理されたインジェスト、ストレージ、クロスアカウントログ分析、暗号化などの CloudWatch Logs の機能のサブセットを、GB あたりの低いインジェスト価格で提供します。Infrequent Access ログクラスは、アドホックなクエリやアクセス頻度の低いログに対する事後のフォレンジック分析に最適です。
新しいロググループに使用するロググループクラスを指定するには、log_group_class ディレクティブを使用します。有効な値は STANDARD と INFREQUENT_ACCESS です。このフィールドを省略した場合、エージェントはデフォルトの STANDARD を使用します。
適切なクラス指定のための既存ログの監査
CloudWatch Logs の Infrequent Access 階層のログクラスは、CloudWatch ログ機能の一部を利用します。 標準のロググループを Infrequent Access ロググループとして再作成できるかどうかを確認するため、既存のロググループを監査することをお勧めします。 これを行うには、log-ia-checker CLI ツールを実行するのが良い方法です。 このツールは、指定されたリージョン内のすべてのロググループを分析し、Infrequent Access に移行可能なログの出力を提供します。
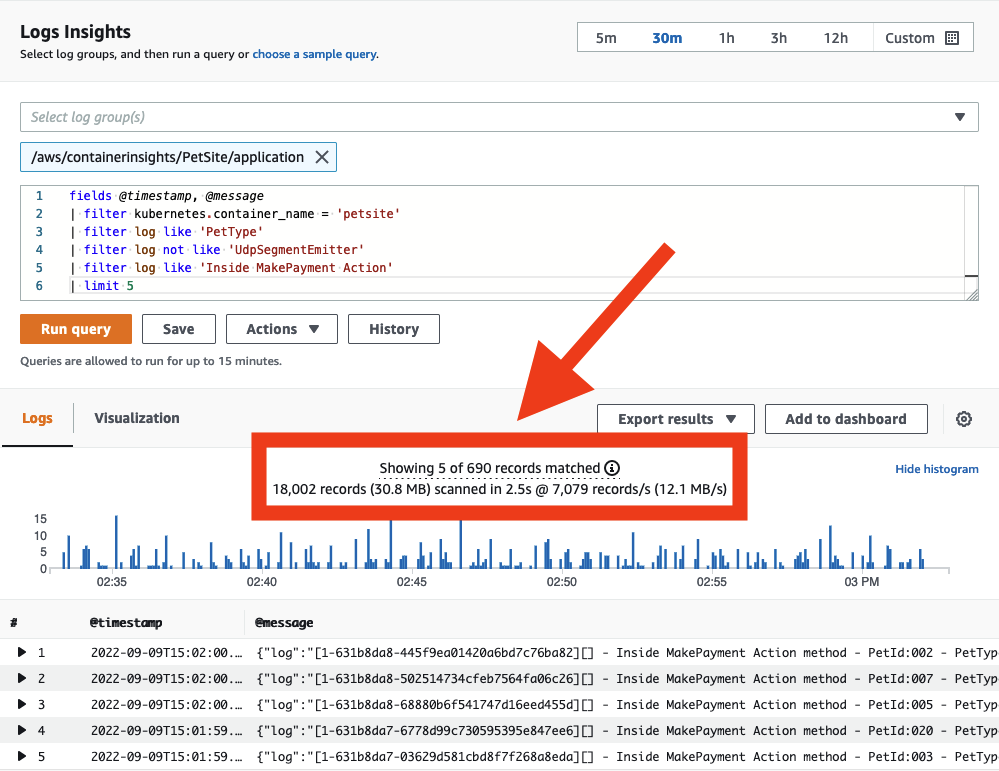
CloudWatch Logs での検索
クエリスコープによるコストの管理
CloudWatch Logs にデータが配信されると、必要に応じてデータを検索できるようになります。CloudWatch Logs はスキャンされたデータ量に応じて料金が発生することに注意してください。クエリスコープを制御し、スキャンされるデータ量を削減するための戦略がいくつかあります。
ログを検索する際は、時間と日付の範囲が適切であることを確認してください。CloudWatch Logs では、スキャンの相対的または絶対的な時間範囲を設定できます。前日のエントリのみを探している場合、今日のログのスキャンを含める必要はありません!
1 つのクエリで複数のロググループを検索できますが、その場合はスキャンされるデータ量が増加します。対象とするロググループを特定したら、それに合わせてクエリスコープを縮小してください。
CloudWatch コンソールから、各クエリが実際にスキャンしたデータ量を直接確認できます。この方法を使用することで、効率的なクエリを作成するのに役立ちます。
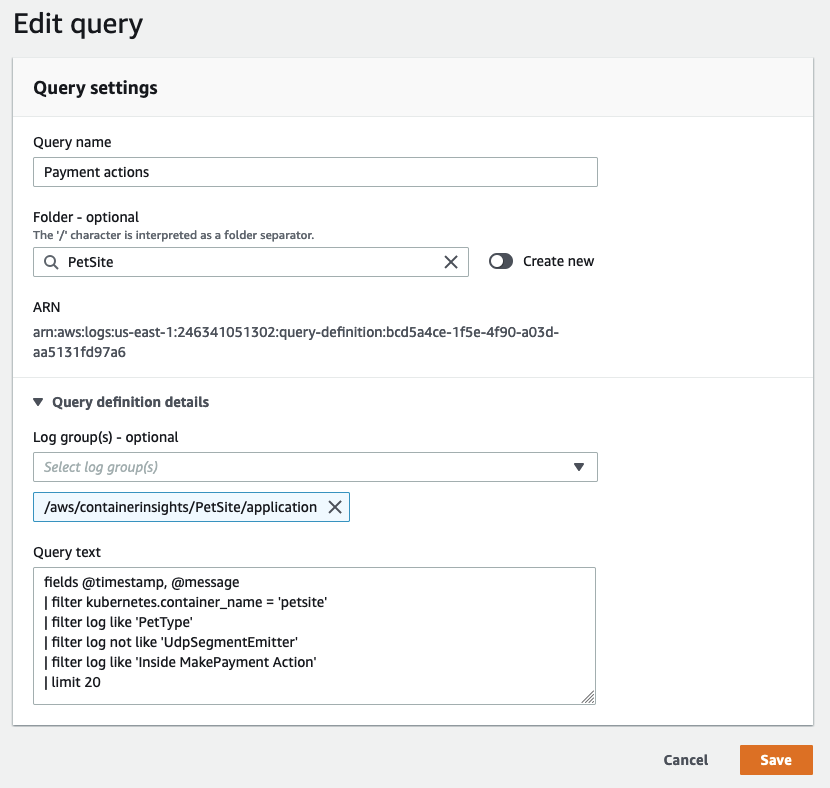
クエリの共有
CloudWatch Logs のクエリ構文 は複雑ではありませんが、特定のクエリを一から作成するのは時間がかかる場合があります。
同じ AWS アカウント内のユーザー間で、適切に作成されたクエリを共有することで、アプリケーションログの調査を効率化できます。
これは AWS マネジメントコンソール から直接、または CloudFormation や AWS CDK を使用してプログラムで実現できます。
これにより、ログデータを分析する必要がある他のユーザーの作業量を削減できます。
頻繁に使用されるクエリを CloudWatch Logs に保存することで、ユーザーがすぐに利用できるようになります。
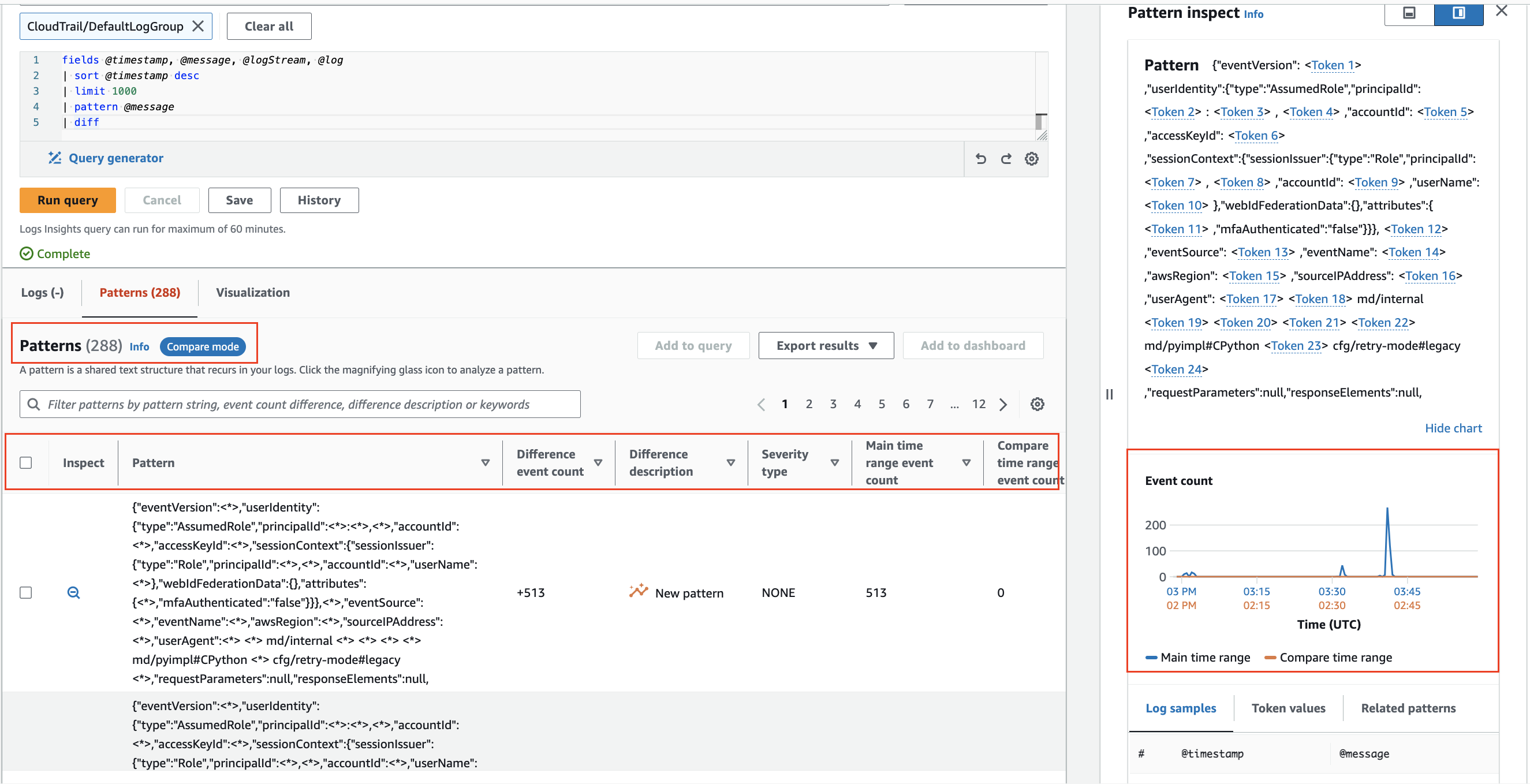
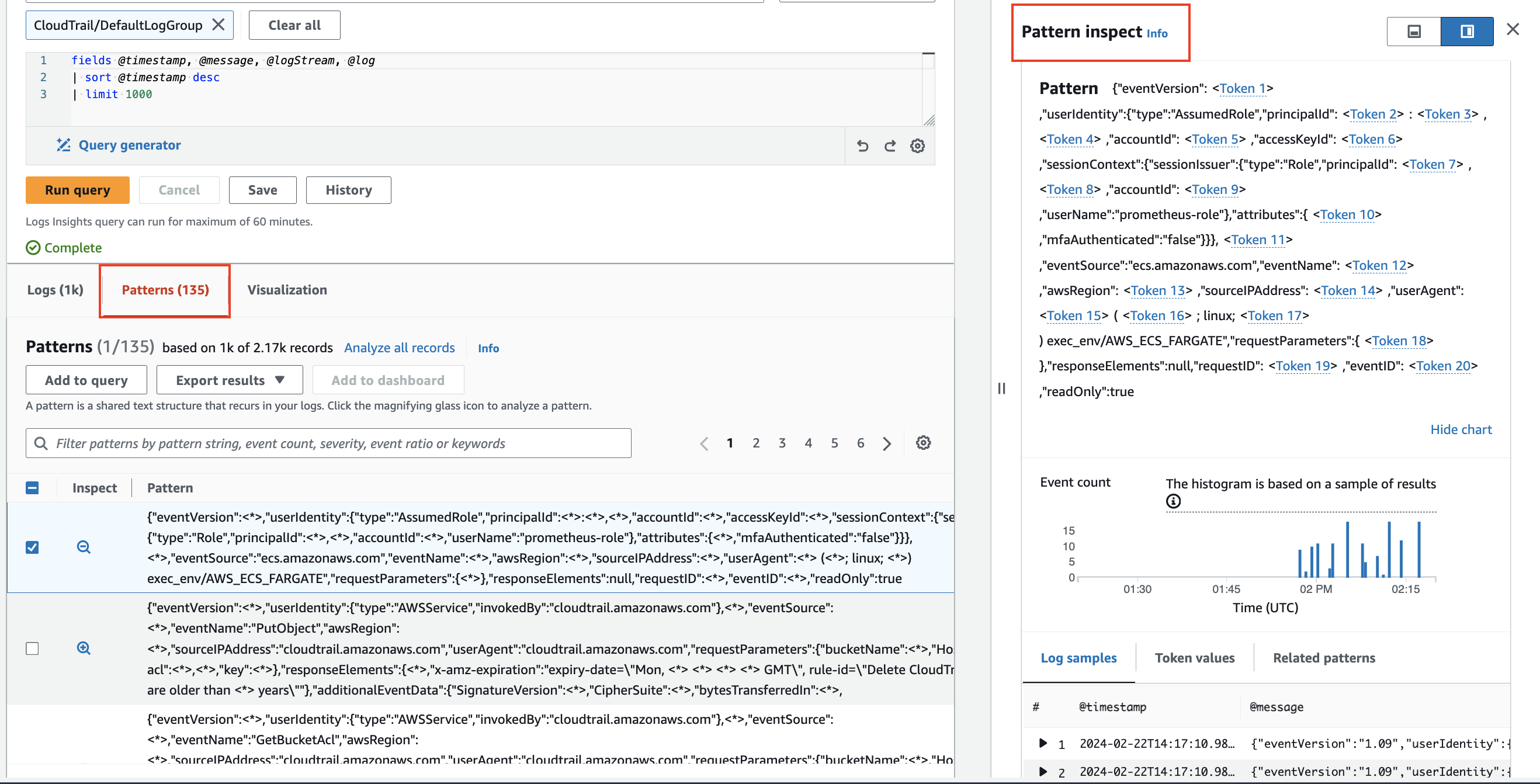
パターン分析
CloudWatch Logs Insights は、ログをクエリする際に機械学習アルゴリズムを使用してパターンを見つけます。 パターンは、ログフィールド間で繰り返し出現する共通のテキスト構造です。 多数のログイベントを少数のパターンに圧縮できることが多いため、パターンは大規模なログセットの分析に役立ちます。2
パターンを使用��して、ログデータを自動的にパターンにクラスタリングします。
前の時間範囲との比較 (diff)
CloudWatch Logs Insights では、時間の経過に伴うログイベントの変更を比較することができ、エラーの検出とトレンドの特定に役立ちます。 比較クエリはパターンを明らかにし、迅速なトレンド分析を容易にし、より詳細な調査のためにサンプルの生ログイベントを調べることができます。 クエリは、選択された期間と同じ長さの比較期間の 2 つの時間帯に対して分析されます。3
diff コマンドを使用して、時間の経過に伴うログイベントの変更を比較します。