メトリクス
メトリクスは、システムのパフォーマンスに関するデータです。システムやリソースに関連するすべてのメトリクスを一元化された場所で管理することで、メトリクスの比較、パフォーマンスの分析、リソースのスケールアップやスケールインといった戦略的な意思決定をより適切に行うことができます。また、メトリクスはリソースの健全性を把握し、予防的な対策を講じるうえでも重要です。
メトリクスデータは基盤となるものであり、アラーム、異常検出、イベント、ダッシュボードなどを駆動するために使用されます。
ベンダーメトリクス
CloudWatch メトリクスは、システムのパフォーマンスに関するデータを収集します。デフォルトでは、ほとんどの AWS サービスがリソースの無料メトリクスを提供しています。これには、Amazon EC2 インスタンス、Amazon RDS、Amazon S3 バケットなど、多くのサービスが含まれます。
これらのメトリクスをベンダーメトリクスと呼びます。AWS アカウントでのベンダーメトリクスの収集には料金はかかりません。
CloudWatch にメトリクスを送信する AWS サービスの完全なリストについては、このページを参照してください。
メトリクスのクエリ
CloudWatch のメトリクス数式機能を使用して、複数のメトリクスをクエリし、数式を使ってより詳細なメトリクス分析を行うことができます。たとえば、次のようなメトリクス数式を記述して、クエリごとの Lambda エラーレートを求めることができます。
Errors/Requests
CloudWatch コンソールでの表示例を以下に示します。
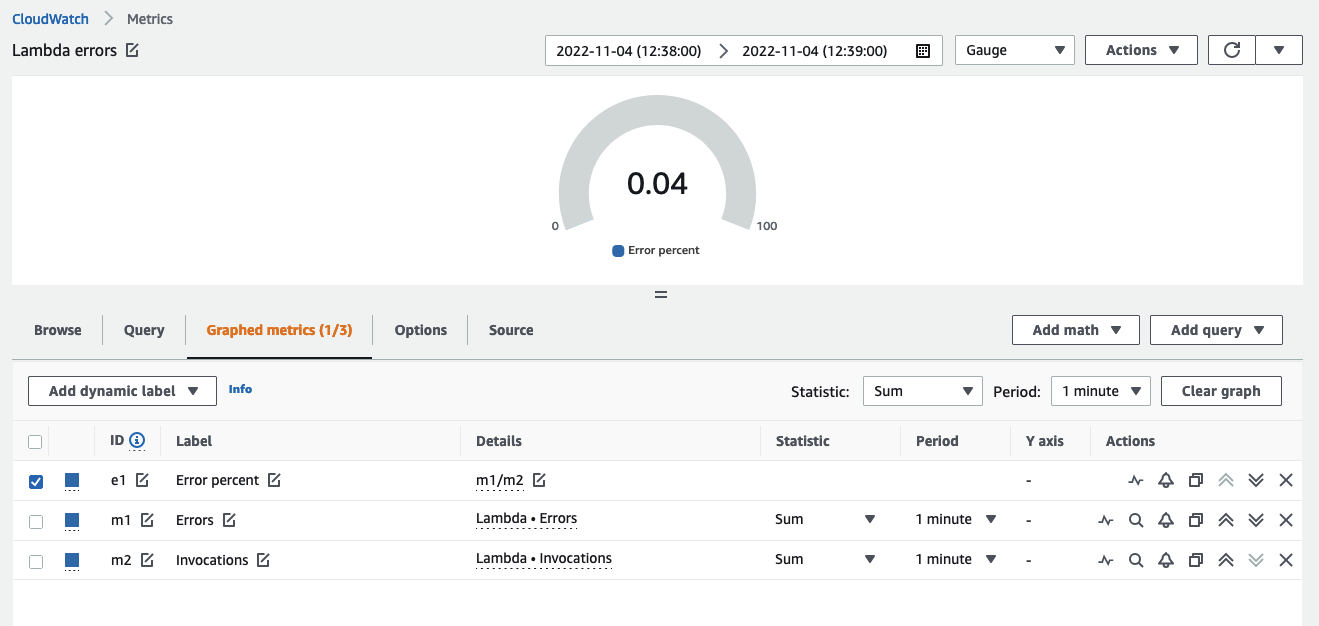
メトリクス数式を使用して、データから最大限の価値を引き出し、個別のデータソースのパフォーマンスから値を導き出します。
CloudWatch は条件文もサポートしています。たとえば、レイテンシーが特定のしきい値を超える各タイムシリーズに対して値 1 を返し、その他のすべてのデータポイントに対して 0 を返すには、クエリは次のようになります。
IF(latency>threshold, 1, 0)
CloudWatch コンソールでは、このロジックを使用してブール値を作成し、そ��れをCloudWatch アラームやその他のアクションのトリガーにすることができます。これにより、派生データポイントからの自動アクションが可能になります。CloudWatch コンソールの例を以下に示します。
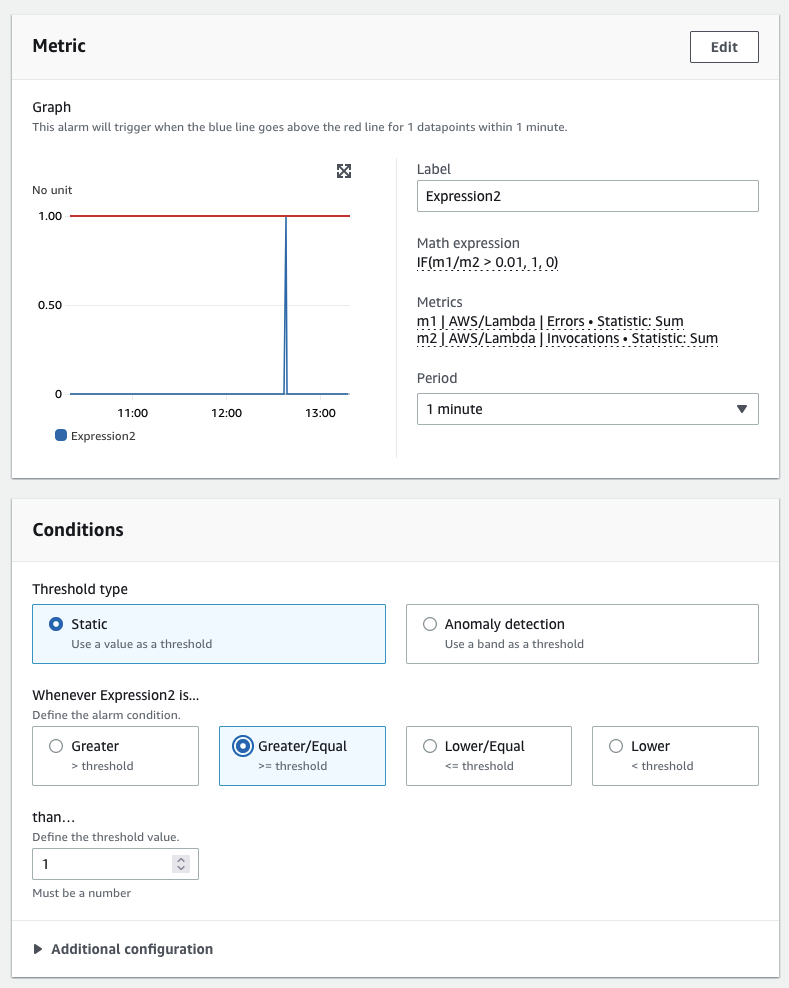
派生値のパフォーマンスがしきい値を超えた場合にアラームと通知をトリガーするには、条件文を使用します。
SEARCH 関数を使用して、任意のメトリクスの上位 n 件を表示することもできます。多数の時系列(例:数千台のサーバー)にわたって最もパフォーマンスが高い、または低いメトリクスを可視化する場合、このアプローチにより最も重要なデータのみを確認できます。以下は、過去 5 分間の平均で CPU 消費量が上位 2 位の EC2 インスタンスを返す検索の例です。
SLICE(SORT(SEARCH('{AWS/EC2,InstanceId} MetricName="CPUUtilization"', 'Average', 300), MAX, DESC),0, 2)
CloudWatch コンソールでの同じ表示:
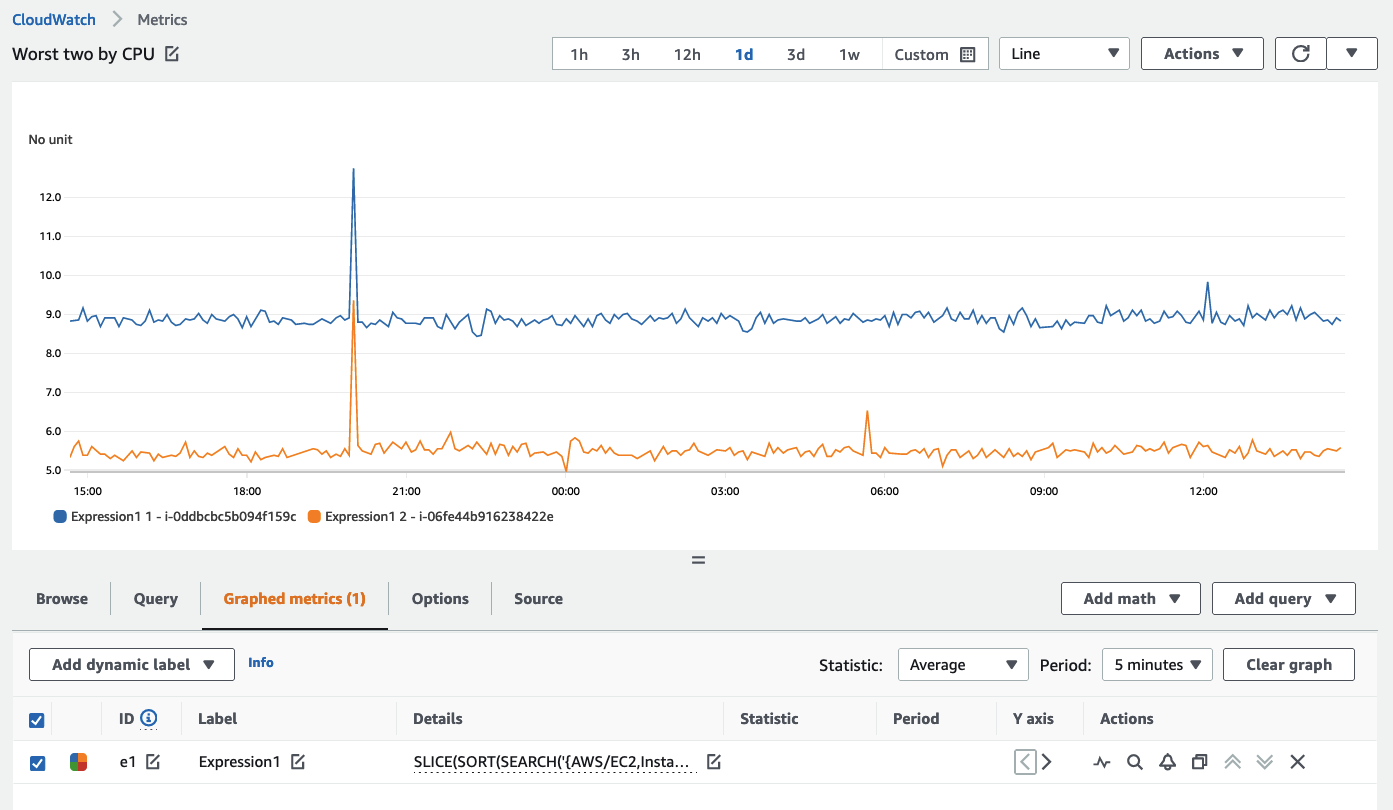
SEARCH アプローチを使用して、環境内で価値のある、またはパフォーマンスが最も低いリソースを迅速に表示し、それらをダッシュボードに表示します。
メトリクスの収集
EC2 インスタンスのメモリやディスク使用率などの追加メトリクスが必要な場合は、CloudWatch エージェントを使用して、このデータを代わりに CloudWatch にプッシュできます。または、グラフィカルな方法で可視化する必要があるカスタム処理データがあり、そのデータを CloudWatch メトリクスとして表示したい場合は、PutMetricData API を使用して、カスタムメトリクスを CloudWatch に発行します。
ベアな API ではなく、AWS SDK のいずれかを使用して、メトリクスデータを CloudWatch にプッシュしてください。
PutMetricData API コールはクエリ数に基づいて課金されます。PutMetricData API を最適に使用することがベストプラクティスです。この API の Values and Counts メソッドを使用すると、1 回の PutMetricData リクエストで 1 つのメトリクスにつき最大 150 個の値を発行でき、このデータのパーセンタイル統計の取得もサポートされま�す。そのため、各データポイントに対して個別の API 呼び出しを行う代わりに、すべてのデータポイントをまとめてグループ化し、1 回の PutMetricData API コールで CloudWatch にプッシュする必要があります。このアプローチはユーザーに 2 つの利点をもたらします。
- CloudWatch の料金
PutMetricDataAPI スロットリングを防ぐことができます
PutMetricData を使用する場合、可能な限りデータをまとめて単一の PUT 操作にバッチ処理することがベストプラクティスです。
大量のメトリクスが CloudWatch に送信される場合は、代替アプローチとして Embedded Metric Format の使用を検討してください。Embedded Metric Format は PutMetricData を使用せず、その使用に��対して課金されることもありませんが、CloudWatch Logs の使用による課金は発生します。
異常検出
CloudWatch には、記録されたメトリクスに基づいて正常な状態を学習することで、オブザーバビリティ戦略を強化する異常検出機能があります。異常検出の使用は、あらゆるメトリクスシグナル収集システムにおけるベストプラクティスです。
異常検出は、2 週間の期間にわたってモデルを構築します。
異常検出は、作成時点以降のデータのみからモデルを構築します。過去に遡って以前の外れ値を検出することはありません。
異常検出は、メトリクスにとって何が良いかを知っているわけではなく、標準偏差に基づいて何が正常かのみを把握しています。
異常検出モデルは、通常の動作が期待される時間帯のみを分析するようにトレーニングするのがベストプラクティスです。トレーニングから除外する時間帯(夜間、週末、祝日など)を定義できます。
異常検出バンドの例をここで確認できます。バンドはグレーで表示されています。
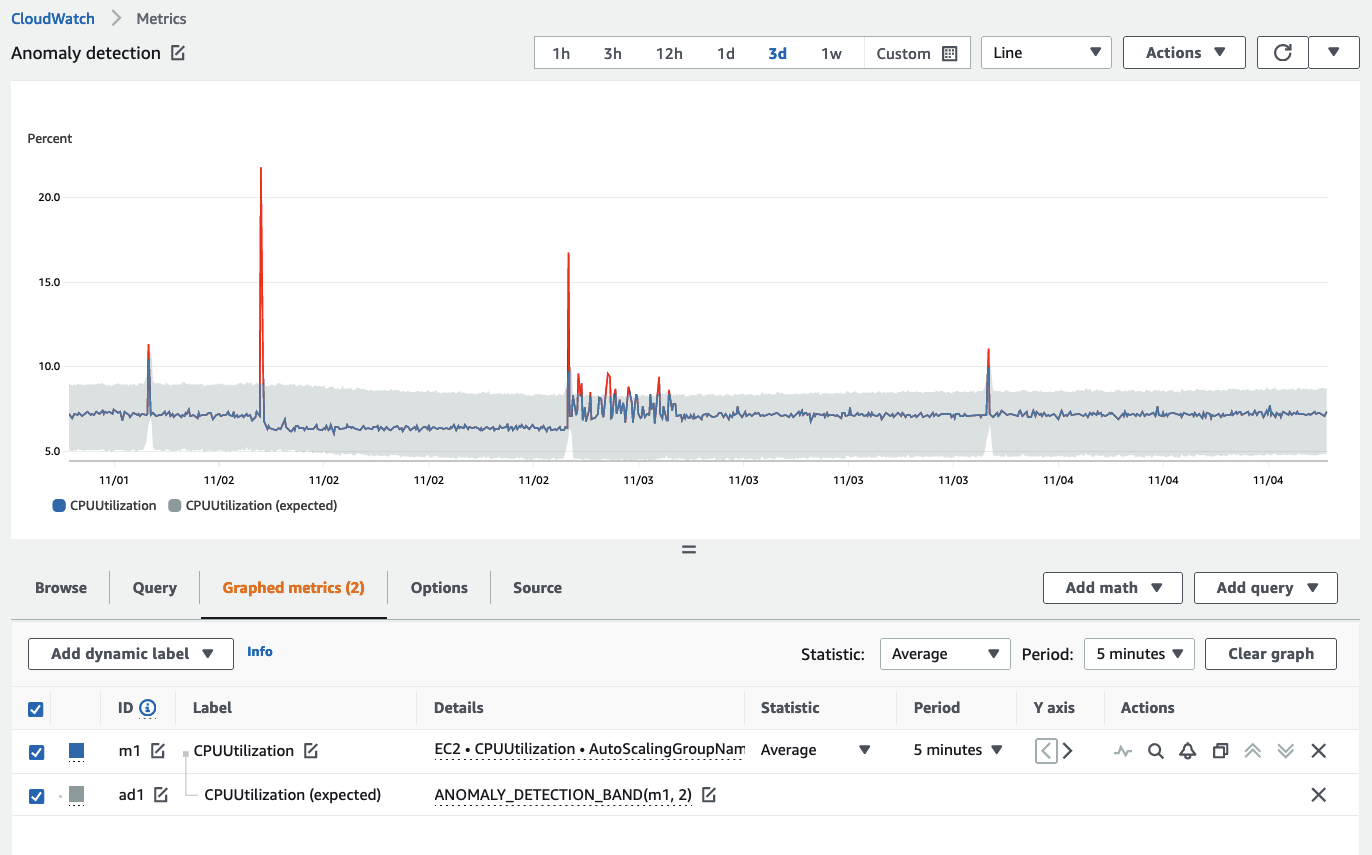
異常検出の除外ウィンドウの設定は、CloudWatch コンソール、CloudFormation、またはいずれかの AWS SDK を使用して行うことができます。