AWS 可观测性成熟度模型
介绍
可观测性的核心是能够通过分析系统的外部输出来理解和获得系统内部状态洞察的能力。这一概念已经从关注预定义 metrics 或事件的传统监控方法演变为一种更全面的方法,涵盖了环境中各种组件生成的数据的收集、分析和可视化。一个系统如果没有被观察就无法被控制或优化。有效的可观测性策略使团队能够快速识别和解决问题、优化资源使用,并获得对系统整体健康状况的洞察。可观测性提供了高效检测、调查和修复问题的能力,这可以且应该改善整体运营可用性和工作负载的健康状况。

监控和可观测性之间的区别在于,监控告诉您系统是否正常工作,而可观测性告诉您系统为什么不正常工作。监控通常是一种被动措施,而可观测性的目标是能够以主动方式改善您的关键绩效指标 (KPI)。持续监控和可观测性提高了敏捷性,改善了客户体验并降低了云环境的风险。
可观测性成熟度模型
可观测性成熟度模型是组织优化其工作负载可观测性和管理流程的重要框架。该模型为企业提供了一个全面的路线图,用于评估其当前能力、确定改进领域,并战略性地投资于正确的工具和流程以实现最佳可观测性。在云计算、微服务、临时和分布式系统的时代,可观测性已成为确保数字服务可靠性和性能的关键因素。通过提供改善可观测性的结构化方法,该模型使组织能够对其系统获得更深刻的理解和控制,为更具韧性、高效和高性能的业务铺平道路。
可观测性成熟度模型的阶段
随着组织扩展其工作负载,可观测性成熟度模型也应该随之成熟。然而,通往可观测性成熟度的道路并不总是随着工作负载的增长而增长。其目的是帮助客户在扩展和发展其组织能力时达到所需的成熟度水平。
-
可观测性成熟度模型的第一阶段通常涉及建立对组织当前状态的基线理解。这包括评估现有的监控工具和流程,以及识别可见性或功能方面的差距。在这个阶段,组织可以盘点其当前能力并设定切实可行的改进目标,甚至从工程周期的早期阶段就开始。
-
在下一个阶段,组织通过采用高级可观测性策略和服务向更复杂的方法迈进。这可能包括实施主动告警、分布式追踪以获得对不同系统之间交互的洞察,通过此方式组织可以开始获得增强可见性的好处、降低认知负荷和更高效的故障排除。
-
随着企业进入可观测性成熟度模型的第三阶段,他们可以利用额外的能力,如自动修复、人工智能和机器学习技术来自动化异常检测和根因分析。这些高级功能使组织不仅能够检测问题,还能在问题影响终端用户或中��断业务运营之前采取纠正措施。通过将可观测性工具与事件管理平台等其他关键系统集成,组织可以简化其事件响应流程并最小化解决问题所需的时间。
-
可观测性成熟度模型的最后阶段涉及利用监控和可观测性工具生成的大量数据来推动持续改进。这可能涉及使用高级分析来识别工作负载性能中的模式和趋势,以及将此信息反馈到工程和运营流程中以优化资源分配、架构和部署策略。
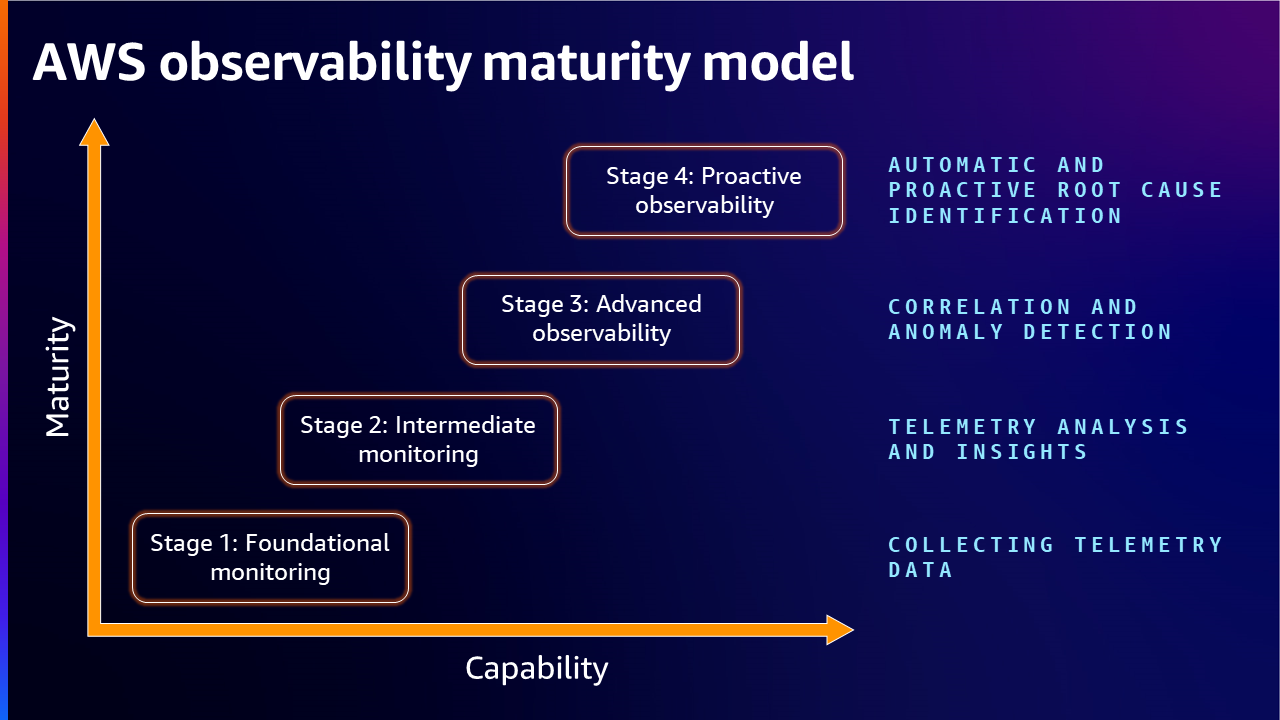
阶段 1:基础监控 - 收集遥测数据
作为最低标准采用并在孤立状态下工作,基本监控没有定义组织中系统或工作负载总体监控所需的策略。大多数时候,不同的团队如应用程序所有者、网络运营中心 (NOC) 或 CloudOps 或 DevOps 团队使用不同的工具来满足其监控需求,因此这种方法在跨系统调试或环境优化方面价值有限。
通常,处于此阶段的客户对其工作负载有不同的监控解决方案。不同的团队,大多数时候他们以不同的方式收集相同的数据,因为与其他团队没有或有限的合作。团队倾向于使用获得的数据来优化他们需要的内容。此外,团队无法使用彼此的数据,因为从另一个团队获得的数据可能格式不同。创建识别关键工作负载的计划、以统一的可观测性解决方案为目标、定义 metrics 和��日志是此级别的关键方面。设计您的工作负载以捕获其提供的基本遥测数据对于了解其内部状态和工作负载健康状况是必要的。
为了构建提高成熟度水平的基础,通过收集 metrics、日志、traces 来插桩工作负载,并使用正确的监控和可观测性工具获得有意义的洞察,帮助客户控制和优化环境。插桩是指从环境中测量、跟踪和捕获关键数据,这些数据可用于观察工作负载的行为和性能。示例包括应用程序 metrics(如错误、成功或不成功的事务)和基础设施 metrics(如 CPU 和磁盘资源的利用率)。
阶段 2:中级监控 - 遥测分析和洞察
在此阶段,客户看到其组织在从本地和云等各种环境收集信号方面变得更加清晰。他们已经设计了从工作负载收集 metrics、日志和 traces 的机制,因为这些构成了可观测性的基础结构,创建了可视化、告警策略,并且能够根据明确定义的标准对问题进行优先级排序。客户不再是被动和猜测,而是有一个调用所需操作的工作流程,相关团队能够根据捕获的信息和历史知识进行分析和故障排除。此级别的客户致力于为其传统或现代、高度可扩展、分布式、敏捷和微服务架构的环境实现可观测性实践。
虽然监控在大多数情况下似乎运作良好,但组织往往花费更多时间调试问题,因此总体平均解决时间 (MTTR) 在一段时间内不一致或没有得到有意义的改善。此外,调试问题的认知时间和精力高于预期,因此事件响应时间更长。还往往存在数据过载的情况,这也让运营不堪重负。我们发现大多数企业被困在这个阶段而没有意识到他们下一步可以去哪里。可以采取的具体行动将组织推进到下一个级别包括:1) 定期审查系统架构设计并部署策略和实践以减少影响和停机时间,从而减少告警。2) 通过定义可操作的 KPI、为告警发现添加有价值的上下文、按严重性/紧急性分类、发送到不同的工具和团队来帮助工程师更快解决问题,从而防止告警疲劳。
定期分析这些告警并自动修复常见重复告警。与相关团队分享和沟通告警发现,以提供运营和流程改进的反馈。
制定计划逐步构建知识图谱,帮助您关联不同实体并了解系统不同部分之间的依赖关系。它使客户能够可视化系统变化的影响,帮助预测和缓解潜在问题。
阶段 3:高级可观测性 - 关联和异常检测
在此阶段,��组织能够清楚地了解问题的根因,无需花费大量时间进行故障排除。当问题出现时,告警为网络运营中心 (NOC)、CloudOps 或 DevOps 团队等相关团队提供足够的上下文信息。监控团队能够查看告警并通过关联 metrics、日志和 traces 等信号立即确定问题的根因。Traces 是从应用程序收集的关于请求的数据,可以与工具一起使用来查看、过滤和获得洞察以识别问题和优化机会。应用程序的追踪请求不仅提供有关请求和响应的详细信息,还提供应用程序对下游 AWS 资源、微服务、数据库和 Web API 的调用信息。他们可以查看 trace,在 traces 被捕获时找到相应的日志事件,还可以查看来自基础设施和应用程序的 metrics,获得 360 度的情况视图。
相关团队可以通过提供解决问题的修复来立即采取补救措施。在这种情况下,MTTR 非常小,服务级别目标 (SLO) 为绿色,错误预算的消耗速率是可容忍的。通常,处于此级别的客户已经为其现代、敏捷、高度可扩展和微服务环境实现了可观测性实践。
许多组织已经在其可观测性环境中达到了这种复杂性和成熟度水平。这个阶段已经使组织能够支持复杂的基础设施,以高可用性运营其系统,为其应用程序提供更高的服务级别可用性 (SLA),并通过提供可靠的基础设施实现业务创新。客户还使用异常检测器来监控不匹配通常模式的异常和离群值,并具有近实时的告警机制。
然而,此类组织中的团队始终希望超越已知的可能性。团队希望了解重复问题,创建一个知识库,可以用来对场景进行建模以预测未来可能出现的问题。这就是客户进入成熟度模型下一阶段的时候,在这个阶段他们可以获得对未知事物的洞察。为了达到这一目标,需要新的工具,还需要在存储和利用数据方面确定新的技能和技术。��可以利用 IT 运营人工智能 (AIOps) 来创建自动关联信号、识别根因、基于使用过去收集的数据训练的模型创建解决方案计划的系统。
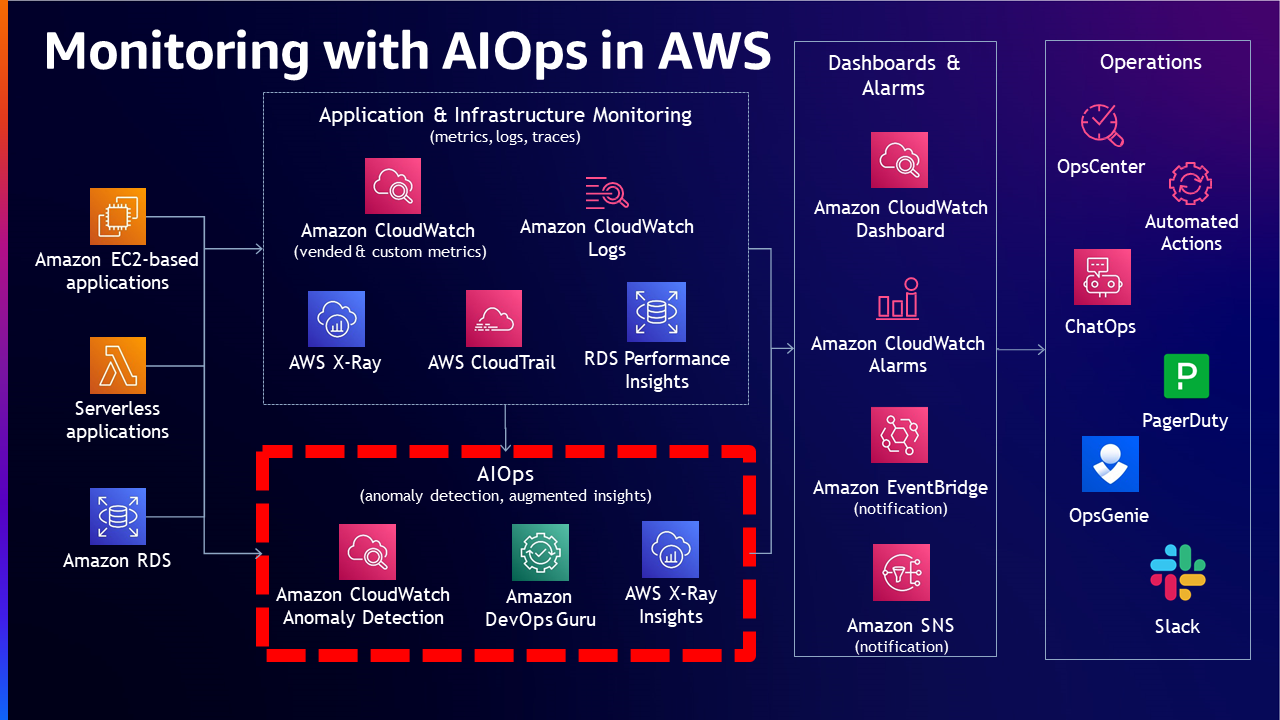
阶段 4:主动可观测性 - 自动和主动的根因识别
在这里,可观测性数据不仅在问题发生"之后"使用,而是在问题发生"之前"实时利用数据。使用训练有素的模型,主动进行问题识别,解决方案变得更容易和更简单。通过分析收集的信号,监控系统能够自动提供问题洞察,并列出解决问题的解决方案选项。
可观测性软件供应商正在不断扩展其在这一领域的能力,随着生成式 AI 的流行这一趋势只会加速,使得期望达到此成熟度水平的组织能够更轻松地实现。一旦这个阶段成熟并成形,客户会看到可观测性服务能够自动创建动态 dashboard 的情况。Dashboard 只包含与当前问题相关的信息。这将节省查询和可视化无关数据的时间和成本。随着生成式 AI (GenAI) 和执行机器学习的计算能力日益民主化,我们可能会看到主动监控能力在未来变得比现在更加普遍。
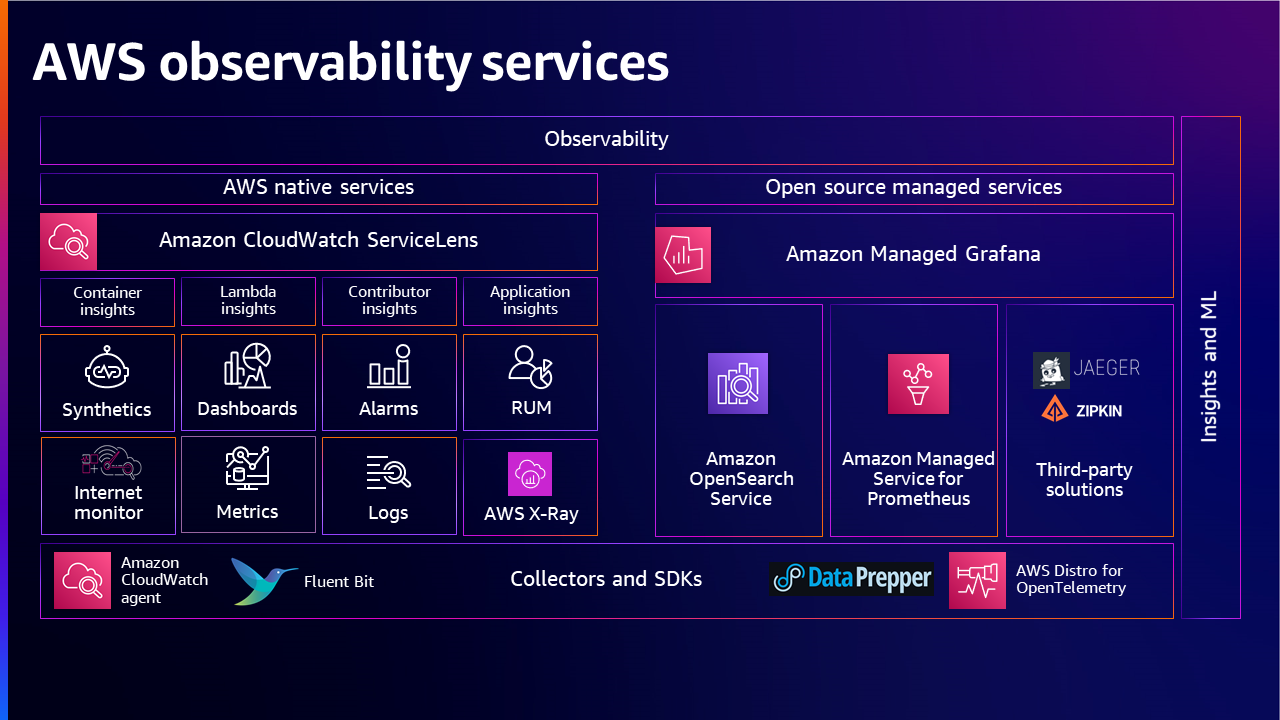
以下是可观测性组合的概述,提供了一个全面的图景,包含各种 AWS 原生和开源解决方案用于数据收集、数据处理、数据洞察和分析,客户可以通过选择适当的解决方案来�满足其端到端的可观测性需求。
AWS Well-Architected 和 Cloud Adoption Framework 用于可观测性
组织可以利用 AWS Well-Architected 和 Cloud Adoption Framework 来增强其可观测性能力并有效监控和排除云环境故障。
AWS Well-Architected 和 Cloud Adoption Framework 用于可观测性提供了设计、部署和运营工作负载的结构化方法,确保遵循最佳实践。这导致了改善的可用性、系统性能、可扩展性和可靠性。这些框架还为组织提供了标准化的实践集和规范性指导,使得在组织间协作、分享知识和实施一致解决方案变得更加容易。
为了有效利用这些框架,组织需要了解称为支柱的关键组件(卓越运营、安全性、可靠性、性能效率、成本优化和可持续性),这些支柱为设计和运营云环境提供了全面的方法。另一方面,Cloud Adoption Framework 提供了云采用的结构化方法,重点关注业务、人员、治理和平台等领域。通过将这些组件与可观测性需求对齐,组织可以构建强大且可扩展的工作负载。
实施 AWS Well-Architected 和 Cloud Adoption Framework 用于可观测性涉及几个步骤。首先,组织需要评估其当前状态并确定改进领域。这可以通过进行可观测性成熟度模型评估来完成,该评估根据这些框架评估工作负载。基于审查结果,组织可以优先排列和规划其可观测性举措。这包括定义监控和日志记录需求、选择适当的 AWS 服务以及实施必要的基础设施和工具。最后,组织需要持续监控和优化其可观测性解决方案以确保持续有效性。
此外,客户可以利用 AWS Well-Architected Tool,这是 AWS 中的一项服务,可以使用 AWS Well-Architected Framework 的最佳实践来记录和衡量其工作负载。该工具提供了通过 AWS Well-Architected Framework 的支柱衡量工作负载的一致流程,帮助记录所做的决策,提供改善工作负载的建议,并指导他们使工作负载更可靠、安全、高效和经济。
评估
可观测性成熟度模型评估可用于衡量您当前的可观测性状态并确定改进领域。每个阶段的评估涉及评估不同团队的现有监控和管理实践、识别差距和改进领域,以及确定进入下一阶段的整体准备度。成熟度评估始于业务流程概述、工作负载清单�和工具发现、识别当前挑战以及了解组织优先事项和目标。
评估帮助确定目标 metrics 和 KPI,为现有布局的进一步开发和优化奠定基础。对可观测性成熟度模型的评估在确保您的业务准备好处理现代系统的复杂、动态性质方面起着关键作用。它有助于识别盲点和可能导致系统故障或性能问题的薄弱领域。
此外,定期评估确保您的业务保持敏捷和适应性。它使您能够跟上不断发展的技术和方法,从而确保您的系统始终处于效率和可靠性的巅峰。
该评估旨在帮助您根据 AWS 最佳实践审查可观测性策略的状态,确定改进机会并跟踪进展。以下问题应帮助您评估当前的可观测性成熟度水平。要使用我们的"AWS 可观测性成熟度模型评估"工具进行免费评估,请联系您的 AWS 账户团队。
日志
- 您如何收集日志?
- 您如何使用日志?
- 您如何访问日志?
- 您的日志保留策略对安全和合规有什么要求?
- 您目前是否使用任何 ML/AI 功能?
Metrics
- 您收集什么类型的 metrics?
- 您如何使用 metrics?
- 您如何访问 metrics?
Traces
- 您如何收集 traces?
- 您如何使用 traces?
Dashboard 和告警
- 您如何使用告警?
- 您如何使用 dashboard?
组织
- 您是否有企业可观测性策略?
- 您如何使用 SLO?
构建可观测性策略
一旦组织�确定了其可观测性阶段,就应该开始构建策略以优化当前流程和工具,并开始朝着成熟度方向努力。组织希望确保其客户拥有出色的客户体验,因此他们从这些客户需求开始并从中逆向推导。然后与您的利益相关者合作,因为他们非常了解这些需求。以可观测性策略为目标,组织必须首先定义其可观测性目标,因为它们应该与整体业务目标保持一致,并应明确阐述组织通过该策略旨在实现的目标,为构建和实施可观测性计划提供路线图。
接下来,组织需要确定将提供系统性能洞察的关键 metrics (KPI)。这些可能包括延迟、错误率、资源利用率和事务量。需要注意的是,metrics 的选择在很大程度上取决于业务的性质及其特定需求。
确定关键 metrics 后,组织可以决定数据收集所需的工具和技术。工具的选择应基于其与组织目标的一致性、与现有系统的集成便利性、成本优化、可扩展性、满足客户需求和改善整体客户体验。
最后,组织还应培养重视可观测性的文化。这包括培训团队成员了解可观测性的重要性,鼓励他们主动监控系统性能,并培育持续学习和改进的文化。这一策略创造了持续收集、行动和改进的良性循环,以实现最佳的客户体验。
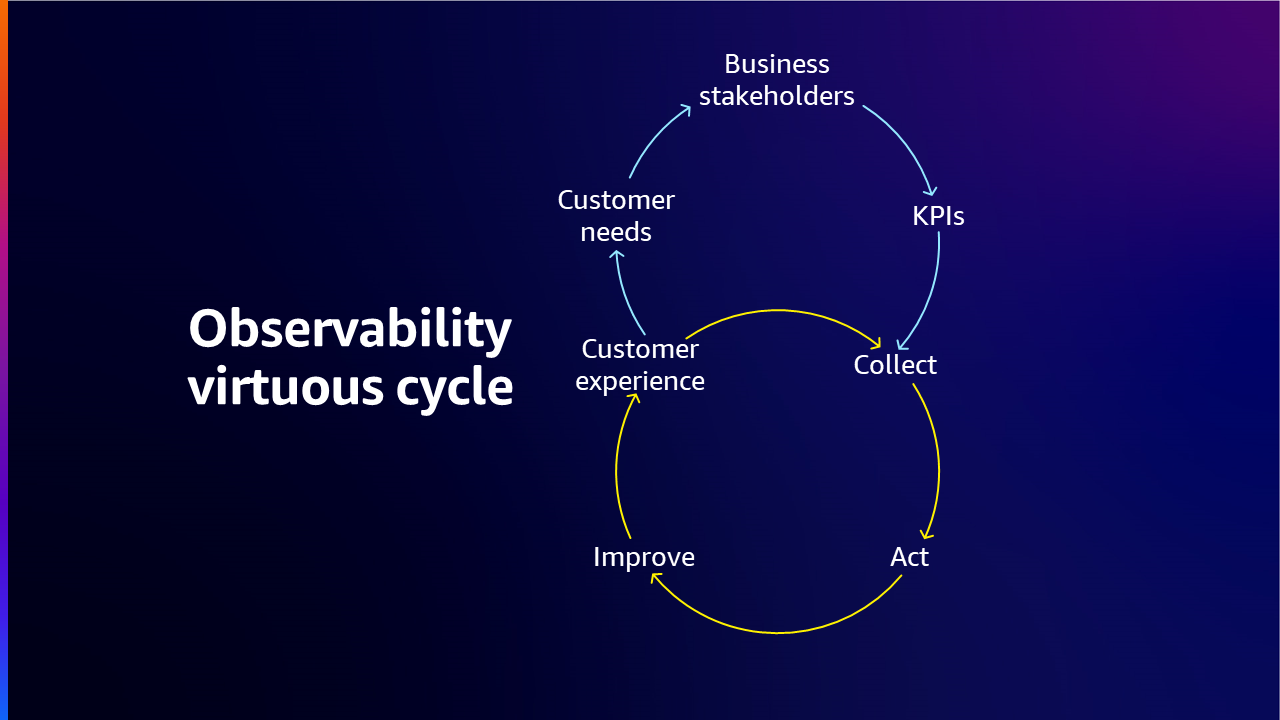
总之,要构建可观测性策略,需要考虑三个主要方面:1) 需要收集什么 2) 需要观察哪些系统和工作负载 3) 当出现问题时如何反应以及应该有什么机制来修复它们。
结论��
可观测性成熟度模型是组织评估其当前状态和寻求改善其理解、分析和响应工作负载和基础设施行为的能力的路线图。通过遵循结构化方法来评估当前能力、采用高级监控技术和利用数据驱动的洞察,企业可以达到更高的可观测性水平,并对其工作负载和基础设施做出更明智的决策。该模型概述了组织需要发展的关键能力和实践,以便在不同成熟度级别之间进步,最终达到能够充分利用主动可观测性优势的状态。
有用资源
- Building an effective 可观测性 strategy - AWS re:Invent 2023
- AWS 可观测性 Best Practices
- What is 可观测性 and Why does it matter?
- How to develop an 可观测性 strategy?
- Guidance for Deep Application 可观测性 on AWS
- How Discovery increased operational efficiency with AWS 可观测性 - AWS re:Invent 2022
- Developing an 可观测性 strategy - AWS re:Invent 2022
- Explore Cloud Native 可观测性 with AWS - AWS Virtual Workshop
- Increase availability with AWS 可观测性 solutions - AWS re:Invent 2020
- 可观测性 best practices at Amazon - AWS re:Invent 2022
- 可观测性: Best practices for modern applications - AWS re:Invent 2022
- 可观测性 the open-source way - AWS re:Invent 2022
- Elevate your 可观测性 Strategy with AIOps
- Let's Architect! Monitoring production systems at scale
- Full-stack 可观测性 and application monitoring with AWS - AWS Summit SF 2022