AWS 上的 Databricks 监控和可观测性最佳实践
Databricks 是一个管理数据分析和 AI/ML 工作负载的平台。本指南旨在帮助在 AWS 上运行 Databricks 的客户,使用 AWS 原生可观测性服务或开源托管服务来监控这些工作负载。
为什么要监控 Databricks
管理 Databricks 集群的运维团队可以从集成的自定义 dashboard 中受益,用于跟踪工作负载状态、错误、性能瓶颈;对不良行为进行告警,例如总资源使用随时间的变化或错误百分比;以及集中日志记录,用于根因分析和提取额外的自定义 metrics。
监控什么
Databricks 在其集群实例中运行 Apache Spark,Spark 具有原生功能来暴露 metrics。这些 metrics 将提供有关 driver、worker 和在集群中执行的工作负载的信息。
运行 Spark 的实例还包含有关存储、CPU、内存和网络的额外有用信息。了解哪些外部因素可能影响 Databricks 集群的性能非常重要。对于具有大量实例的集群,了解瓶颈和整体健康状况也很重要。
如何监控
要安装收集器及其依赖项,需要 Databricks init 脚本。这些脚本在 Databricks 集群的每个实例启动时运行。
Databricks 集群权限还需要使用实例配置文件发送 metrics 和 logs 的权限。
最后,最佳实践是在 Databricks 集群的 Spark 配置中配置 metrics 命名空间,将 testApp 替换为对集群的适当引用。
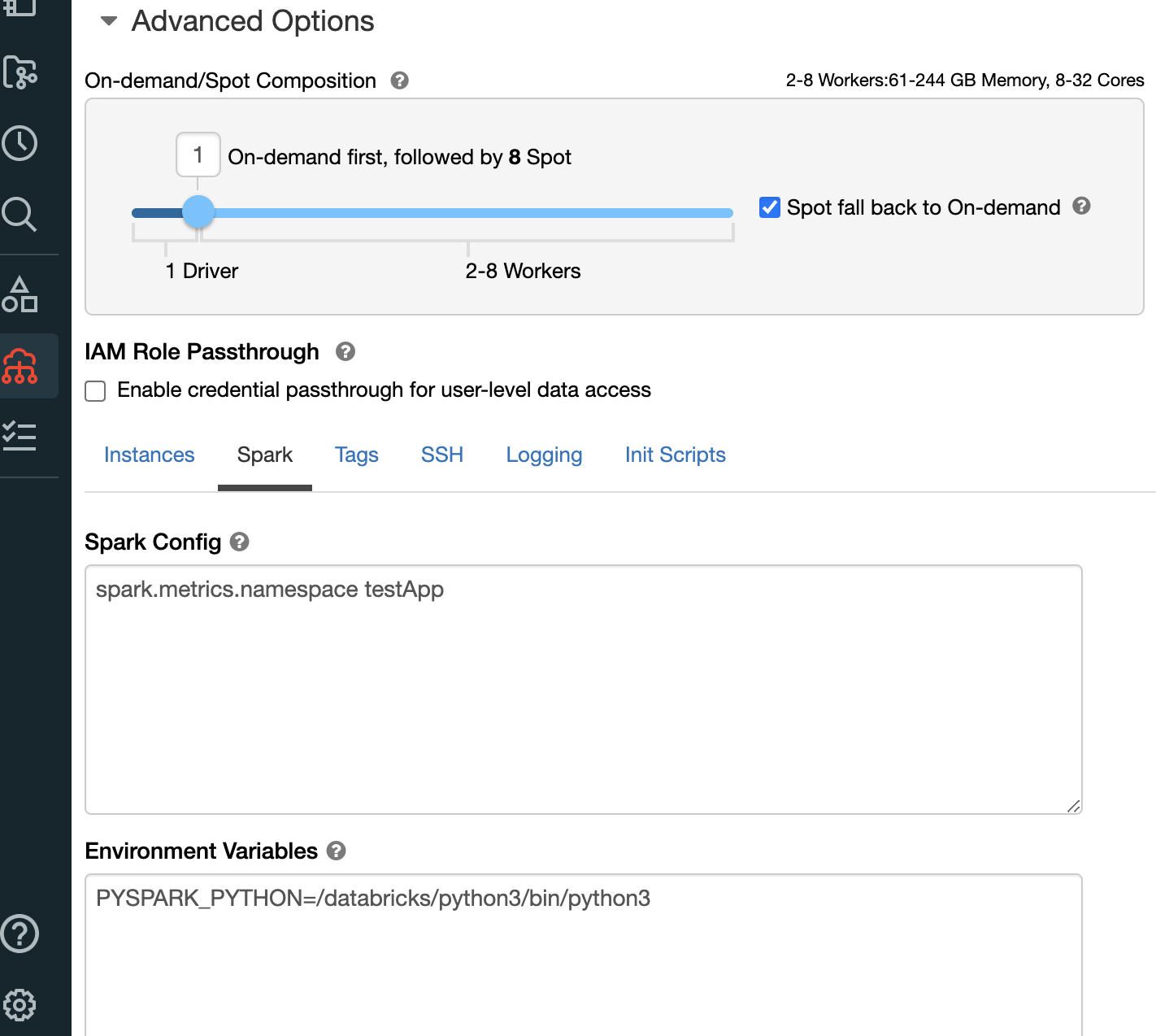 图 1:metrics 命名空间 Spark 配置示例
图 1:metrics 命名空间 Spark 配置示例
良好的 Databricks 可观测性解决方案的关键组成部分
1) Metrics: Metrics 是描述在一段时间内测量的活动或特定过程的数字。以下是 Databricks 上不同类型的 metrics:
系统资源级别 metrics,如 CPU、内存、磁盘和网络。 使用 Custom Metrics Source、StreamingQueryListener 和 QueryExecutionListener 的应用程序 metrics。 由 MetricsSystem 暴露的 Spark metrics。
2) Logs: Logs 是已发生事件的序列表示,它们讲述了一个线性故事。以下是 Databricks 上不同类型的 logs:
- Event logs
- Audit logs
- Driver logs:stdout、stderr、log4j 自定义 logs(启用结构化日志记录)
- Executor logs:stdout、stderr、log4j 自定义 logs(启用结构化日志记录)
3) Traces: Stack traces 提供端到端可见性,展示了各阶段的完整流程。当您需要调试以确定哪些阶段/代码导致错误/性能问题时,这非常有用。
4) Dashboards: Dashboards 提供应用程序/服务黄金 metrics 的出色摘要视图。
5) 告警: 告警通知工程师需要关注的状况。
AWS 原生可观测性选项
原生解决方案(如 Ganglia UI 和 Log Delivery)是收集系统 metrics 和查询 Apache Spark metrics 的优秀解决方案。但是,某些方面可以改进:
- Ganglia 不支持告警。
- Ganglia 不支持从 logs 创建派生 metrics(例如,ERROR 日志增长率)。
- 您无法使用自定义 dashboards 来跟踪与数据正确性、数据新鲜度或端到端延迟相关的 SLO(服务级别目标)和 SLI(服务级别指标),然后用 Ganglia 进行可视化。
Amazon CloudWatch 是监控和管理 AWS 上 Databricks 集群的关键工具。它提供有关集群性能的宝贵洞察,帮助您快速识别和解决问题。将 Databricks 与 CloudWatch 集成并启用结构化日志记录可以帮助改善这些方面。CloudWatch Application Insights 可以帮助您自动发现 logs 中包含的字段,CloudWatch Logs Insights 提供专用查询语言,用于更快的调试和分析。
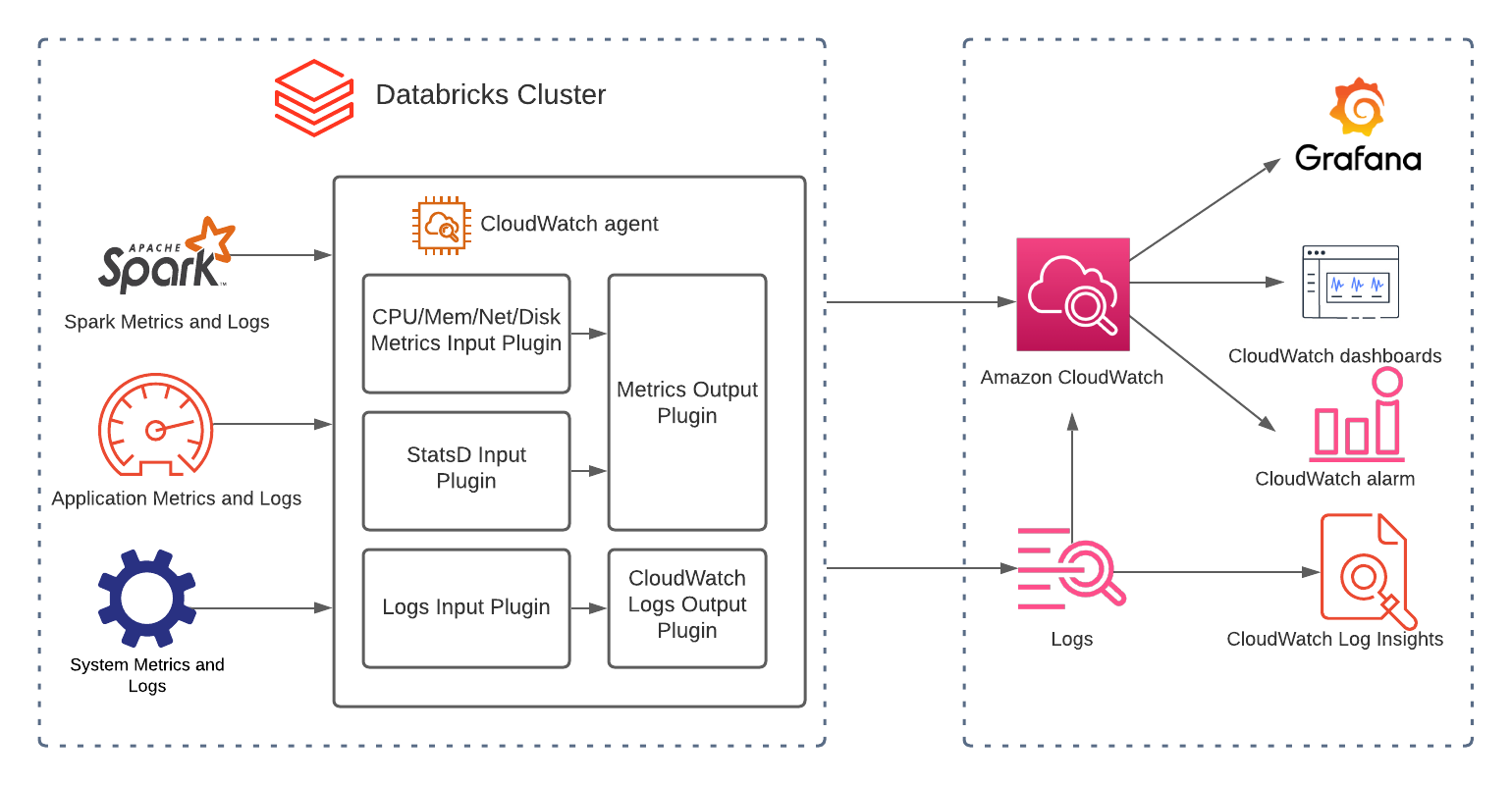 图 2:Databricks CloudWatch 架构
图 2:Databricks CloudWatch 架构
有关如何使用 CloudWatch 监控 Databricks 的更多信息,请参阅: How to Monitor Databricks with Amazon CloudWatch
开源软件可观测性选项
Amazon Managed Service for Prometheus 是与 Prometheus 兼容的监控托管无服务器服务,负责存储 metrics 和管理基于这些 metrics 创建的告警。Prometheus 是流行的开源监控技术,是继 Kubernetes 之后第二个属于 Cloud Native Computing Foundation 的项目。
Amazon Managed Grafana 是 Grafana 的托管服务。Grafana 是用于时间序列数据可视化的开源技术,常用于可观测性。我们可以使用 Grafana 可视化来自多个来源的数据,如 Amazon Managed Service for Prometheus、Amazon CloudWatch 等。它将用于可视化 Databricks metrics 和告警。
AWS Distro for OpenTelemetry 是 OpenTelemetry 项目的 AWS 支持发行版,提供用于收集 traces 和 metrics 的开源标准、库和服务。通过 OpenTelemetry,我们可以收集多种不同的可观测性数据格式(如 Prometheus 或 StatsD),丰富这些数据,并将其发送到多个目的地(如 CloudWatch 或 Amazon Managed Service for Prometheus)。
使用场景
虽然 AWS 原生服务将提供管理 Databricks 集群所需的可观测性,但在某些场景中,使用开源托管服务是最佳选择。
Prometheus 和 Grafana 都是非常流行的技术,已经在许多公司中使用。AWS 开源可观测性服务将允许运维团队使用相同的现有基础设施、相同的查询语言以及现有的 dashboards 和告警来监控 Databricks 工作负载,而无需承担管理这些服务基础设施、可扩展性和性能的繁重工作。
ADOT 是需要将 metrics 和 traces 发送到不同目的地(如 CloudWatch 和 Prometheus)或使用不同类型数据源(如 OTLP 和 StatsD)的团队的最佳替代方案。
最后,Amazon Managed Grafana 支持许多不同的数据源,包括 CloudWatch 和 Prometheus,帮助决定使用多个工具的团队关联数据,允许创建适用于所有现有和新 Databricks 集群的模板,以及强大的 API 允许通过基础设施即代码进行配置和管理。
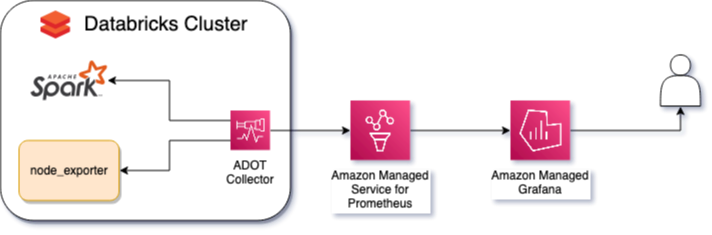 图 3:Databricks 开源可观测性架构
图 3:Databricks 开源可观测性架构
要使用 AWS 托管开源可观测性服务观察 Databricks 集群的 metrics,您需要一个 Amazon Managed Grafana 工作区来可视化 metrics 和告警,以及一个 Amazon Managed Service for Prometheus 工作区(在 Amazon Managed Grafana 工作区中配置为数据源)。
有两种重要的 metrics 需要收集:Spark metrics 和节点 metrics。
Spark metrics 将提供诸如集群中当前 worker 数量或 executor 数量、shuffle(节点在处理过程中交换数据时发生)或 spill(数据从 RAM 到磁盘以及从磁盘到 RAM)等信息。要暴露这些 metrics,必须通过 Databricks 管理控制台启用 Spark 原生 Prometheus(自 3.0 版本起可用),并通过 init_script 进行配置。
要跟踪节点 metrics(如磁盘使用率、CPU 时间、内存、存储性能),我们使用 node_exporter,它可以无需进一步配置即可使用,但应仅暴露重要的 metrics。
必须在集群的每个节点上安装 ADOT Collector,抓取 Spark 和 node_exporter 暴露的 metrics,过滤这些 metrics,注入元数据(如 cluster_name),并将这些 metrics 发送到 Prometheus 工作区。
ADOT Collector 和 node_exporter 都必须通过 init_script 安装和配置。
Databricks 集群必须配置具有在 Prometheus 工作区中写入 metrics 权限的 IAM Role。
最佳实践
优先选择有价值的 metrics
Spark 和 node_exporter 都暴露了多种 metrics,以及同一 metrics 的多种格式。如果不过滤哪些 metrics 对监控和事件响应有用,检测问题的平均时间会增加,存储样本的成本会增加,有价值的信息将更难找到和理解。使用 OpenTelemetry processors,可以过滤并仅保留有价值的 metrics,或过滤掉无意义的 metrics;�在发送到 AMP 之前聚合和计算 metrics。
避免告警疲劳
一旦有价值的 metrics 被摄入 AMP,配置告警就至关重要。然而,对每次资源使用突增都告警可能会导致告警疲劳,即过多的噪音会降低对告警严重性的信任,使重要事件未被发现。应使用 AMP 告警规则组功能避免歧义,即多个相关告警产生分散的通知。此外,告警应接收适当的严重性级别,并应反映业务优先级。
复用 Amazon Managed Grafana dashboards
Amazon Managed Grafana 利用 Grafana 原生模板功能,允许为所有现有和新的 Databricks 集群创建 dashboards。它消除了为每个集群手动创建和维护可视化的需要。要使用此功能,metrics 中需要有正确的标签来按集群分组这些 metrics。同样,这可以通过 OpenTelemetry processors 实现。