AWS에서의 Databricks 모니터링 및 Observability 모범 사례
Databricks는 데이터 분석 및 AI/ML 워크로드를 관리하기 위한 플랫폼입니다. 이 가이드는 AWS에서 Databricks를 실행하는 고객이 AWS 네이티브 Observability 서비스 또는 오픈소스 관리형 서비스를 사용하여 이러한 워크로드를 모니터링하는 것을 지원하는 것을 목표로 합니다.
Databricks를 모니터링해야 하는 이유
Databricks 클러스터를 관리하는 운영 팀은 워크로드 상태, 오류, 성능 병목 현상을 추적하기 위한 통합된 맞춤형 대시보드를 갖추면 유리합니다. 또한 시간에 따른 총 리소스 사용량이나 오류 비율과 같은 원치 않는 동작에 대한 알림, 근본 원인 분석을 위한 중앙 집중식 로깅, 추가적인 맞춤형 metrics 추출에도 유리합니다.
무엇을 모니터링해야 하나요
Databricks는 클러스터 인스턴스에서 Apache Spark를 실행하며, Spark에는 metrics를 노출하는 네이티브 기능이 있습니다. 이러한 metrics는 드라이버, 워커 및 클러스터에서 실행되는 워크로드에 대한 정보를 제공합니다.
Spark를 실행하는 인스턴스에는 스토리지, CPU, 메모리, 네트워킹에 대한 추가적인 유용한 정보가 있습니다. Databricks 클러스터의 성능에 영향을 미칠 수 있는 외부 요인을 이해하는 것이 중요합니다. 수많은 인스턴스가 있는 클러스터의 경우, 병목 현상과 전반적인 상태를 이해하는 것도 중요합니다.
모니터링하는 방법
collector와 그 종속성을 설치하려면 Databricks init 스크립트가 필요합니다. 이는 Databricks 클러스터의 각 인스턴스에서 부팅 시 실행되는 스크립트입니다.
Databricks 클러스터 권한에는 인스턴스 프로파일을 사용하여 metrics와 로그를 전송할 수 있는 권한도 필요합니다.
마지막으로, Databricks 클러스터 Spark 구성에서 metrics 네임스페이스를 구성하는 것이 모범 사례이며, testApp을 클러스터에 대한 적절한 참조로 대체합니다.
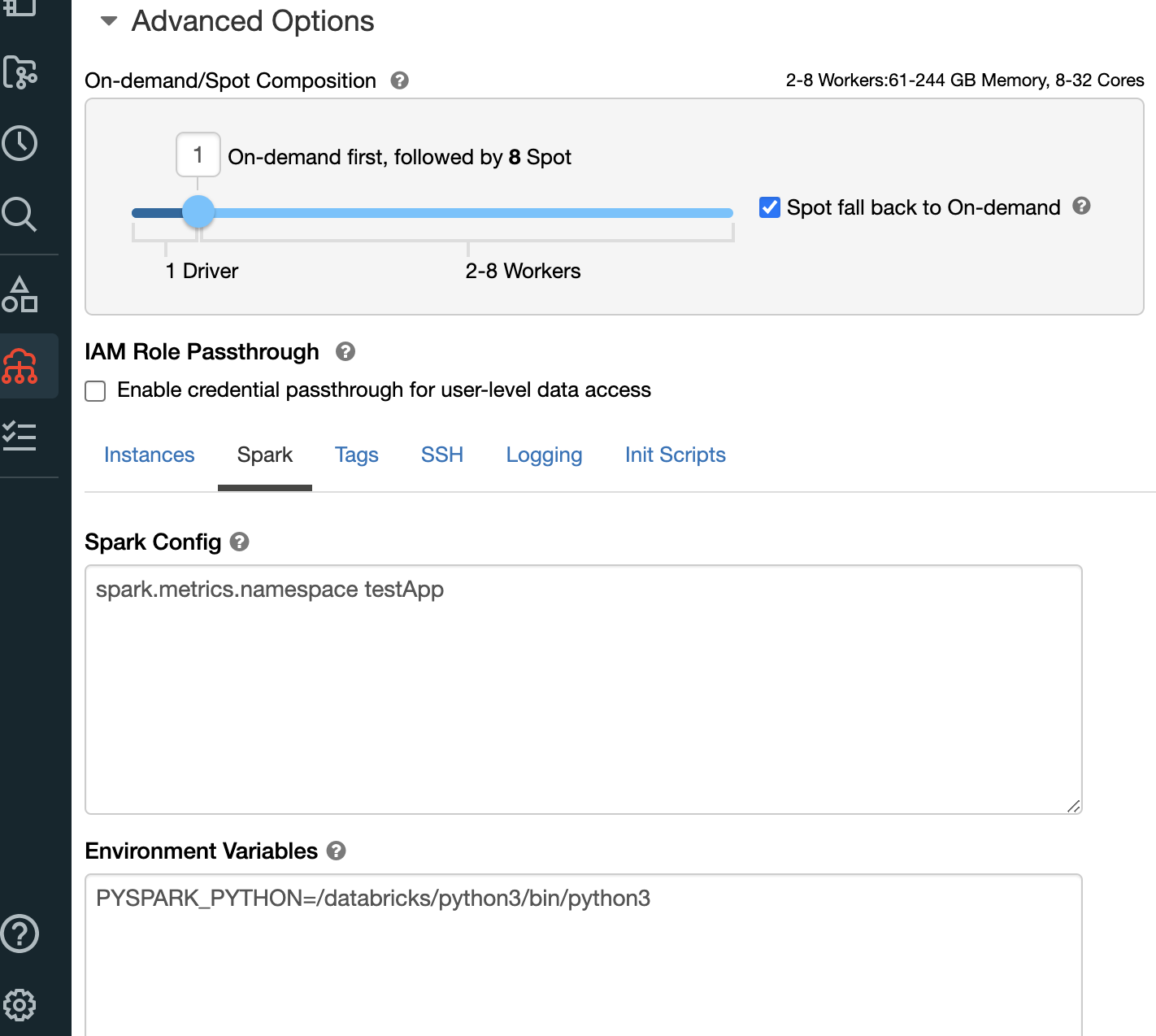 그림 1: metrics 네임스페이스 Spark 구성 예시
그림 1: metrics 네임스페이스 Spark 구성 예시
Databricks를 위한 좋은 Observability 솔루션의 핵심 요소
1) Metrics: Metrics는 일정 기간에 걸쳐 측정된 활동이나 특정 프로세스를 설명하는 숫자입니다. Databricks의 다양한 유형의 metrics는 다음과 같습니다:
CPU, 메모리, 디스크, 네트워크와 같은 시스템 리소스 수준 metrics. Custom Metrics Source, StreamingQueryListener, QueryExecutionListener를 사용한 애플리케이션 Metrics. MetricsSystem에 의해 노출되는 Spark Metrics.
2) Logs: Logs는 발생한 연속적인 이벤트를 표현하며, 이에 대한 선형적인 이야기를 전달합니다. Databricks의 다양한 유형의 로그는 다음과 같습니다:
- Event logs
- Audit logs
- Driver logs: stdout, stderr, log4j 커스텀 로그 (구조화된 로깅 활성화)
- Executor logs: stdout, stderr, log4j 커스텀 로그 (구조화된 로깅 활성화)
3) Traces: Stack traces는 엔드투엔드 가시성을 제공하며, 전체 단계의 흐름을 보여줍니다. 어떤 단계/코드가 오류/성능 문제를 일으키는지 디버깅해야 할 때 유용합니다.
4) Dashboards: 대시보드는 애플리케이션/서비스의 주요 metrics에 대한 훌륭한 요약 뷰를 제공합니다.
5) Alerts: 알림은 엔지니어에게 주의가 필요한 조건에 대해 �알립니다.
AWS 네이티브 Observability 옵션
Ganglia UI와 Log Delivery와 같은 네이티브 솔루션은 시스템 metrics를 수집하고 Apache Spark™ metrics를 쿼리하기 위한 훌륭한 솔루션입니다. 그러나 일부 영역은 개선할 수 있습니다:
- Ganglia는 알림을 지원하지 않습니다.
- Ganglia는 로그에서 파생된 metrics 생성을 지원하지 않습니다(예: ERROR 로그 증가율).
- 데이터 정확성, 데이터 신선도 또는 엔드투엔드 지연 시간과 관련된 SLO(Service Level Objectives)와 SLI(Service Level Indicators)를 추적하기 위한 커스텀 대시보드를 만들어 ganglia로 시각화할 수 없습니다.
Amazon CloudWatch는 AWS에서 Databricks 클러스터를 모니터링하고 관리하는 데 중요한 도구입니다. 클러스터 성능에 대한 귀중한 인사이트를 제공하고 문제를 빠르게 식별하고 해결할 수 있도록 합니다. Databricks를 CloudWatch와 통합하고 구조화된 로깅을 활성화하면 이러한 영역을 개선할 수 있습니다. CloudWatch Application Insights는 로그에 포함된 필드를 자동으로 검색할 수 있으며, CloudWatch Logs Insights는 더 빠른 디버깅과 분석을 위한 전용 쿼리 언어를 제공합니다.
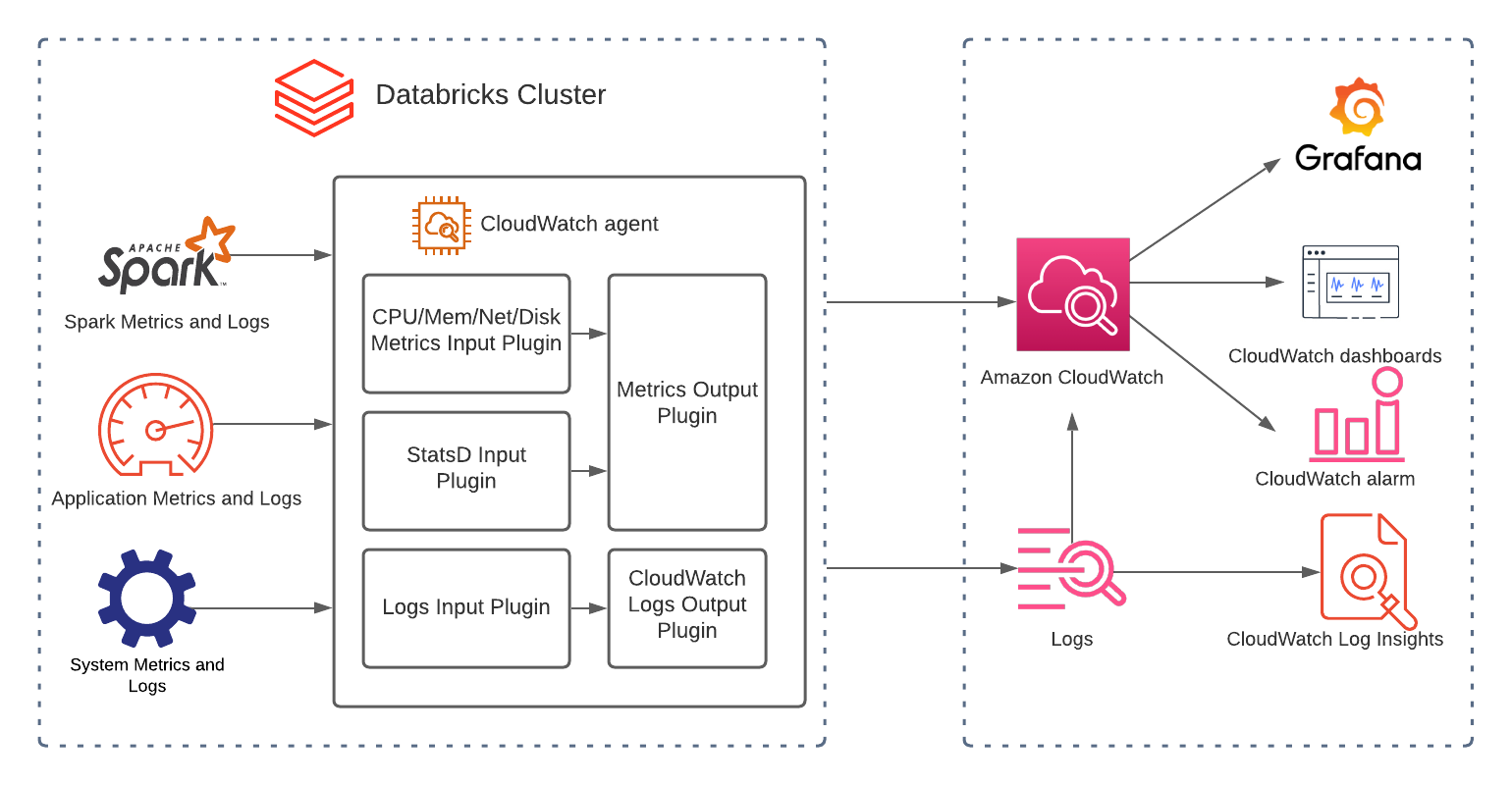 그림 2: Databricks CloudWatch 아키텍처
그림 2: Databricks CloudWatch 아키텍처
CloudWatch를 사용하여 Databricks를 모니터링하는 방법에 대한 자세한 내용은 다음을 참조하세요: Amazon CloudWatch로 Databricks 모니터링하는 방법
오픈소스 소프트웨어 Observability 옵션
Amazon Managed Service for Prometheus는 Prometheus 호환 모니터링 관리형 서버리스 서비스로, metrics를 저장하고 이러한 metrics 위에 생성된 알림을 관리합니다. Prometheus는 인기 있는 오픈소스 모니터링 기술로, Kubernetes 다음으로 Cloud Native Computing Foundation에 속하는 두 번째 프로젝트입니다.
Amazon Managed Grafana는 Grafana의 관리형 서비스입니다. Grafana는 Observability에 일반적으로 사용되는 시계열 데이터 시각화를 위한 오픈소스 기술입니다. Amazon Managed Service for Prometheus, Amazon CloudWatch 등 다양한 소스의 데이터를 시각화하는 데 Grafana를 사용할 수 있습니다. Databricks metrics와 알림을 시각화하는 데 사용됩니다.
AWS Distro for OpenTelemetry는 AWS가 지원하는 OpenTelemetry 프로젝트의 배포판으로, traces와 metrics를 수집하기 위한 오픈소스 표준, 라이브러리 및 에이전트를 제공합니다. OpenTelemetry를 통해 Prometheus나 StatsD�와 같은 여러 가지 Observability 데이터 형식을 수집하고, 이 데이터를 보강한 다음 CloudWatch나 Amazon Managed Service for Prometheus와 같은 여러 대상으로 전송할 수 있습니다.
사용 사례
AWS 네이티브 서비스가 Databricks 클러스터를 관리하는 데 필요한 Observability를 제공하지만, 오픈소스 관리형 서비스를 사용하는 것이 최선인 시나리오가 있습니다.
Prometheus와 Grafana는 모두 매우 인기 있는 기술이며 이미 많은 회사에서 사용되고 있습니다. AWS 오픈소스 Observability 서비스를 사용하면 운영 팀이 이러한 서비스의 인프라, 확장성 및 성능을 관리하는 부담 없이 동일한 기존 인프라, 동일한 쿼리 언어, 기존 대시보드와 알림을 사용하여 Databricks 워크로드를 모니터링할 수 있습니다.
ADOT는 CloudWatch와 Prometheus와 같은 다른 대상으로 metrics와 traces를 전송하거나, OTLP와 StatsD와 같은 다양한 유형의 데이터 소스를 사용해야 하는 팀에 최적의 대안입니다.
마지막으로, Amazon Managed Grafana는 CloudWatch와 Prometheus를 포함한 많은 다양한 Data Sources를 지원하며, 둘 이상의 도구를 사용하기로 결정한 팀의 데이터 상관 관계를 돕고, 모든 Databricks 클러스터에 Observability를 활성화하는 템플릿을 생성할 수 있으며, Infrastructure as Code를 통한 프로비저닝과 구성을 가능하게 하는 강력한 API를 제공합니다.
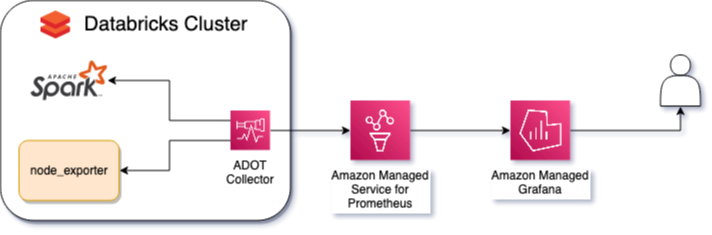 그��림 3: Databricks 오픈소스 Observability 아키텍처
그��림 3: Databricks 오픈소스 Observability 아키텍처
AWS Managed Open Source Observability 서비스를 사용하여 Databricks 클러스터에서 metrics를 관찰하려면 metrics와 알림을 모두 시각화하기 위한 Amazon Managed Grafana workspace와 Amazon Managed Grafana workspace에서 데이터 소스로 구성된 Amazon Managed Service for Prometheus workspace가 필요합니다.
수집해야 할 두 가지 중요한 종류의 metrics가 있습니다: Spark와 노드 metrics.
Spark metrics는 클러스터의 현재 워커 수나 executor; 처리 중에 노드 간 데이터를 교환하는 shuffle; RAM에서 디스크로, 디스크에서 RAM으로 데이터가 이동하는 spill과 같은 정보를 제공합니다. 이러한 metrics를 노출하려면 Spark 3.0 이후 사용 가능한 Spark 네이티브 Prometheus를 Databricks 관리 콘솔을 통해 활성화하고 init_script를 통해 구성해야 합니다.
디스크 사용량, CPU 시간, 메모리, 스토리지 성능과 같은 노드 metrics를 추적하기 위해 node_exporter를 사용하며, 추가 구성 없이 사용할 수 있지만 중요한 metrics만 노출해야 합니다.
각 클러스터 노드에 ADOT Collector를 설치하여 Spark와 node_exporter가 노출하는 metrics를 스크래핑하고, 이러한 metrics를 필터링하고, cluster_name과 같은 메타데이터를 주입하고, 이러한 metrics를 Prometheus workspace로 전송합니다.
ADOT Collector와 node_exporter 모두 init_script를 통해 설치하고 구성해야 합니다.
Databricks 클러스터는 Prometheus workspace에 metrics를 쓸 수 있는 권한이 있는 IAM Role로 구성해야 합니다.
모범 사례
가치 있는 metrics 우선 순위 지정
Spark와 node_exporter는 모두 여러 metrics와 동일한 metrics의 여러 형식을 노출합니다. 모니터링 및 인시던트 대응에 유용한 metrics를 필터링하지 않으면 문제 감지 평균 시간이 증가하고, 샘플 저장 비용이 증가하며, 가치 있는 정보를 찾고 이해하기 어려워집니다. OpenTelemetry 프로세서를 사용하면 유용한 metrics만 필터링하여 유지하거나, 의미 없는 metrics를 필터링하고, AMP로 전송하기 전에 metrics를 집계하고 계산할 수 있습니다.
알림 피로 방지
가치 있는 metrics가 AMP에 수집되면 알림을 구성하는 것이 필수적입니다. 그러나 모든 리소스 사용 급증에 대해 알림을 보내면 알림 피로를 유발할 수 있습니다. 이는 너무 많은 노이즈로 인해 알림 심각도에 대한 신뢰가 저하되고 중요한 이벤트가 감지되지 않을 수 있습니다. AMP 알림 규칙 그룹 기능을 사용하여 모호성을 방지해야 합니다. 즉, 여러 연결된 알림이 별도의 알림을 생성하는 것을 방지합니다. 또한 알림에는 적절한 심각도를 부여해야 하며 비즈니스 우선 순위를 반영해야 합니다.
Amazon Managed Grafana 대시보드 재사용
Amazon Managed Grafana는 Grafana 네이티브 템플릿 기능을 활용하여 모든 기존 및 새 Databricks 클러스터에 대한 대시보드를 생성할 수 있습니다. 각 클러스터에 대해 시각화를 수동으로 생성하고 유지할 필요가 없습니다. 이 기능을 사용하려면 클러스터별로 metrics를 그룹화하기 위해 metrics에 올바른 레이블이 있어야 합니다. 다시 한번, OpenTelemetry 프로세서를 사용하면 가능합니다.