AWS Lambda 기반 서버리스 Observability
분산 시스템과 서버리스 컴퓨팅 환경에서 Observability를 확보하는 것은 애플리케이션의 안정성과 성능을 보장하는 핵심 요소입니다. 이는 전통적인 모니터링을 넘어서는 개념으로, Amazon CloudWatch와 AWS X-Ray 같은 AWS Observability 도구를 활용하면 서버리스 애플리케이션에 대한 깊은 인사이트를 확보하고, 문제를 해결하며, 애플리케이션 성능을 최적화할 수 있습니다. 이 가이드에서는 Lambda 기반 서버리스 애플리케이션의 Observability를 구현하기 위한 핵심 개념, 도구, 모범 사례를 다룹니다.
인프라 또는 애플리케이션에 Observability를 구현하기 전 첫 번째 단계는 핵심 목표를 결정하는 것입니다. 사용자 경험 향상, 개발자 생산성 증대, 서비스 수준 목표(SLO) 달성, 비즈니스 수익 증가, 또는 애플리케이션 유형에 따른 기타 특정 목표가 될 수 있습니다. 이러한 핵심 목표를 명확히 정의하고 어떻게 측정할 �것인지를 확립한 다음, 그로부터 역순으로 Observability 전략을 설계하세요. 자세한 내용은 "중요한 것을 모니터링하기"를 참고하세요.
Observability의 핵심 축
Observability에는 세 가지 핵심 축이 있습니다:
- 로그: 애플리케이션이나 시스템 내에서 발생한 개별 이벤트의 타임스탬프가 기록된 기록으로, 실패, 오류, 상태 변환 등이 포함됩니다
- 메트릭: 다양한 시간 간격으로 측정된 수치 데이터(시계열 데이터)로, SLI(요청률, 오류율, 지속 시간, CPU% 등)가 해당됩니다
- 트레이스: 여러 애플리케이션과 시스템(주로 마이크로서비스)을 거치는 단일 사용자의 요청 경로를 나타냅니다
AWS는 AWS Lambda 애플리케이션에 대한 로깅, 메트릭 모니터링, 트레이싱을 지원하여 실행 가능한 인사이트를 제공하기 위해 네이티브 도구와 오픈소스 도구를 모두 제공합니다.
로그
이 Observability 모범 사례 가이드의 이번 섹션에서는 다음 주제를 심층적으로 다룹니다:
- 비정형 로그 vs 정형 로그
- CloudWatch Logs Insights
- 상관관계 ID 로깅
- Lambda Powertools를 활용한 코드 예제
- CloudWatch Dashboards를 활용한 로그 시각화
- CloudWatch 로그 보관 기간
로그는 애플리케이션 내에서 발생한 개별 이벤트입니다. 실패, 오류, 실행 경로 등의 이벤트가 포함될 수 있으며, 비정형, 반정형, 또는 정형 형식으로 기록됩니다.
비정형 로그 vs 정형 로그
개발자들은 흔히 print나 console.log 문을 사용하여 간단한 로그 메시지를 작성하는 것부터 시작합니다. 이러한 로그는 대규모로 프로그래밍 방식으로 파싱하고 분석하기 어렵습니다. 특히 여러 로그 그룹에 걸쳐 많은 로그 메시지를 생성하는 AWS Lambda 기반 애플리케이션에서는 더욱 그렇습니다. 결과적으로 CloudWatch에서 이러한 로그를 통합하는 것이 어렵고 분석이 힘들어집니다. 관련 정보를 찾으려면 텍스트 매칭이나 정규 표현식을 사용해야 합니다. 다음은 비정형 로깅의 예시입니다:
[2023-07-19T19:59:07Z] INFO Request started
[2023-07-19T19:59:07Z] INFO AccessDenied: Could not access resource
[2023-07-19T19:59:08Z] INFO Request finished
보시다시피, 로그 메시지에 일관된 구조가 없어 유용한 인사이트를 도출하기 어렵습니다. 또한 컨텍스트 정보를 추가하기도 어렵습니다.
반면 정형 로깅은 JSON과 같은 일관된 형식으로 정보를 기록하는 방식으로, 로그를 텍스트가 아닌 데이터로 취급할 수 있어 쿼리와 필터링이 간편해집니다. 개발자는 로그를 프로그래밍 방식으로 효율적으로 저장, 검색, 분석할 수 있으며 디버깅도 수월해집니다. 정형 로깅은 로그 레벨을 통해 서로 다른 환경에서 로그의 상세 수준을 쉽게 조절할 수 있는 방법을 제공합니다. 로그 레벨에 주의를 기울이세요. 과도한 로깅은 비용을 증가시키고 애플리케이션 처리량을 감소시킵니다. 개인 식별 정보는 로깅 전에 반드시 마스킹하세요. 다음은 정형 로깅의 예시입니다:
{
"correlationId": "9ac54d82-75e0-4f0d-ae3c-e84ca400b3bd",
"requestId": "58d9c96e-ae9f-43db-a353-c48e7a70bfa8",
"level": "INFO",
"message": "AccessDenied",
"function-name": "demo-observability-function",
"cold-start": true
}
정형 로깅을 사용하여 CloudWatch 로그에 중앙 집중화하는 것을 권장합니다. 이를 통해 트랜잭션에 대한 운영 정보, 서로 다른 컴포넌트 간의 상관관계 식별자, 애플리케이션의 비즈니스 결과를 기록하세요.
CloudWatch Logs Insights
CloudWatch Logs Insights를 사용하면 JSON 형식의 로그에서 필드를 자동으로 검색할 수 있습니다. 또한, JSON 로그를 확장하여 애플리케이션에 특화된 커스텀 메타데이터를 로깅할 수 있으며, 이를 통해 로그를 검색, 필터링, 집계할 수 있습니다.
상관관계 ID 로깅
예를 들어, API Gateway를 통해 들어오는 HTTP 요청의 경우 상관관계 ID는 requestContext.requestId 경로에 설정되며, Lambda Powertools를 사용하여 다운스트림 Lambda 함수에서 쉽게 추출하고 로깅할 수 있습니다. 분산 시스템에서는 여러 서비스와 컴포넌트가 함께 작동하여 요청을 처리하므로, 상관관계 ID를 로깅하고 다운스트림 시스템에 전달하는 것이 종단 간 트레이싱과 디버깅에 매우 중요합니다. 상관관계 ID는 요청의 시작 시점에 할당되는 고유 식별자입니다. 요청이 여러 서비스를 거치면서 상관관계 ID가 로그에 포함되므로, 요청의 전체 경로를 추적할 수 있습니다. AWS Lambda 로그에 상관관계 ID를 수동으로 삽입하거나, AWS Lambda Powertools와 같은 도구를 사용하여 API Gateway에서 상관관계 ID를 쉽게 추출하고 애플리케이션 로그와 함께 기록할 수 있습니다. 예를 들어, HTTP 요청의 상관관계 ID는 API Gateway에서 시작된 request-id가 될 수 있으며, 이를 Lambda 함수와 같은 백엔드 서비스로 전달할 수 있습니다.
Lambda Powertools를 활용한 코드 예제
모범 사례로서, 서버리스 애플리케이션의 진입점인 API Gateway나 Application Load Balancer에서 가능한 한 빨리 요청 수명 주기 초기에 상관관계 ID를 생성하세요. UUID, request ID, 또는 분산 시스템에서 요청을 추적할 수 있는 기타 고유 속성을 사용하세요. 각 요청과 함께 상관관계 ID를 커스텀 헤더, 본문 또는 메타데이터의 일부로 전달하세요. 다운스트림 서비스의 모든 로그 항목과 트레이스에 상관관계 ID가 포함되도록 하세요.
Lambda 함수 로그에 상관관계 ID를 수동으로 캡처하여 포함하거나, AWS Lambda Powertools를 사용할 수 있습니다. Lambda Powertools를 사용하면 지원되는 업스트림 서비스에 대한 사전 정의된 요청 경로 매핑에서 상관관계 ID를 쉽게 추출하여 애플리케이션 로그에 자동으로 추가할 수 있습니다. 또한, 장애 발생 시 근본 원인을 쉽게 디버깅하고 식별하여 원래 요청으로 추적할 수 있도록 모든 오류 메시지에 상관관계 ID를 포함하세요.
아래 서버리스 아키텍처에서 상관관계 ID를 사용한 정형 로깅을 시연하고 CloudWatch에서 확인하는 코드 예제를 살펴보겠습니다:

// Initializing Logger
Logger log = LogManager.getLogger();
// Uses @Logger annotation from Lambda Powertools, which takes optional parameter correlationIdPath to extract correlation Id from the API Gateway header and inserts correlation_id to the Lambda function logs in a structured format.
@Logging(correlationIdPath = "/headers/path-to-correlation-id")
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
...
// The log statement below will also have additional correlation_id
log.info("Success")
...
}
이 예제에서는 Java 기반 Lambda 함수가 Lambda Powertools 라이브러리를 사용하여 API Gateway 요청에서 들어오는 correlation_id를 로깅합니다.
위 코드 예제의 CloudWatch 로그 샘플:
{
"level": "INFO",
"message": "Success",
"function-name": "demo-observability-function",
"cold-start": true,
"lambda_request_id": "52fdfc07-2182-154f-163f-5f0f9a621d72",
"correlation_id": "<correlation_id_value>"
}_
CloudWatch Dashboards를 활용한 로그 시각화
데이터를 정형 JSON 형식으로 로깅하면, CloudWatch Logs Insights가 JSON 출력에서 값을 자동으로 검색하고 메시지를 필드로 파싱합니다. CloudWatch Logs Insights는 전용 SQL 유사 쿼리 언어를 제공하여 여러 로그 스트림을 검색하고 필터링할 수 있습니다. glob 및 정규 표현식 패턴 매칭을 사용하여 여러 로그 그룹에 걸쳐 쿼리를 수행할 수 있습니다. 또한 커스텀 쿼리를 작성하고 저장하여 매번 다시 만들지 않고도 재실행할 수 있습니다.
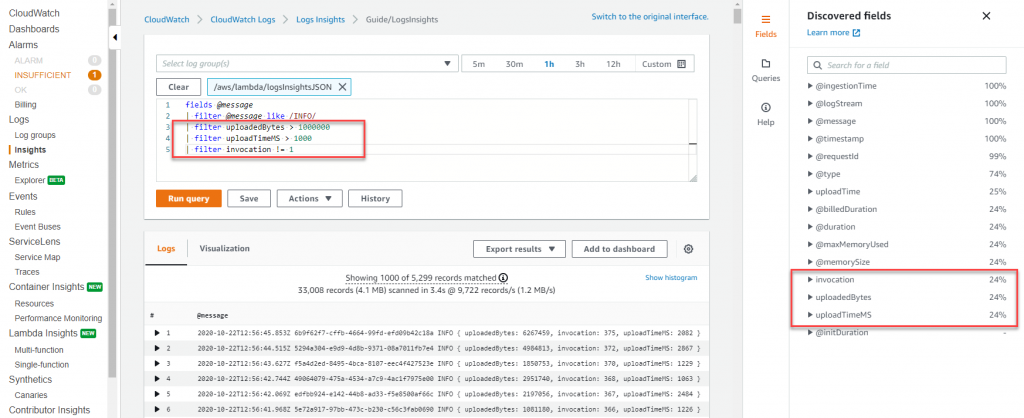 CloudWatch Logs Insights에서는 하나 이상의 집계 함수를 포함하는 쿼리로 라인 차트, 막대 차트, 누적 영역 차트와 같은 시각화를 생성할 수 있습니다. 그런 다음 이러한 시각화를 CloudWatch Dashboards에 쉽게 추가할 수 있습니다. 아래 샘플 대시보드는 Lambda 함수 실행 시간의 백분위수 보고서를 보여줍니다. 이러한 대시보드를 통해 애플리케이션 성능 개선에 집중해야 할 부분을 빠르게 파악할 수 있습니다. 평균 지연 시간도 유용한 메트릭이지만,
CloudWatch Logs Insights에서는 하나 이상의 집계 함수를 포함하는 쿼리로 라인 차트, 막대 차트, 누적 영역 차트와 같은 시각화를 생성할 수 있습니다. 그런 다음 이러한 시각화를 CloudWatch Dashboards에 쉽게 추가할 수 있습니다. 아래 샘플 대시보드는 Lambda 함수 실행 시간의 백분위수 보고서를 보여줍니다. 이러한 대시보드를 통해 애플리케이션 성능 개선에 집중해야 할 부분을 빠르게 파악할 수 있습니다. 평균 지연 시간도 유용한 메트릭이지만, 평균 지연 시간이 아닌 p99를 최적화하는 것을 목표로 해야 합니다.
 플랫폼, 함수, 확장 로그를 CloudWatch 외의 다른 위치로 보내려면, Lambda Extensions와 함께 Lambda Telemetry API를 사용할 수 있습니다. 다수의 파트너 솔루션이 Lambda Telemetry API를 사용하는 Lambda 레이어를 제공하여 해당 시스템과의 통합을 쉽게 해줍니다.
플랫폼, 함수, 확장 로그를 CloudWatch 외의 다른 위치로 보내려면, Lambda Extensions와 함께 Lambda Telemetry API를 사용할 수 있습니다. 다수의 파트너 솔루션이 Lambda Telemetry API를 사용하는 Lambda 레이어를 제공하여 해당 시스템과의 통합을 쉽게 해줍니다.
CloudWatch Logs Insights를 최대한 활용하려면, 정형 로깅 형태로 로그에 어떤 데이터를 수집해야 하는지 고민하세요. 이를 통해 애플리케이션의 상태를 더 효과적으로 모니터링할 수 있습니다.
CloudWatch 로그 보관 기간
기본적으로 Lambda 함수에서 stdout에 기록된 모든 메시지는 Amazon CloudWatch 로그 스트림에 저장됩니다. Lambda 함수의 실행 역할에는 CloudWatch 로그 스트림을 생성하고 스트림에 로그 이벤트를 기록할 수 있는 권한이 있어야 합니다. CloudWatch 요금은 수집된 데이터 양과 사용된 스토리지에 따라 청구된다는 점을 인지하는 것이 중요합니다. 따라서 로깅 양을 줄이면 관련 비용을 최소화할 수 있습니다. 기본적으로 CloudWatch 로그는 무기한 보관되며 만료되지 않습니다. 로그 스토리지 비용을 줄이기 위해 로그 보관 정책을 구성하는 것이 권장되며, 모든 로그 그룹에 적용하세요. 환경별로 서로 다른 보관 정책을 원할 수 있습니다. 로그 보관 기간은 AWS 콘솔에서 수동으로 구성할 수 있지만, 일관성과 모범 사례를 보장하려면 Infrastructure as Code(IaC) 배포의 일부로 구성해야 합니다. 다음은 Lambda 함수의 로그 보관 기간을 구성하는 CloudFormation 템플릿 예제입니다:
Resources:
Function:
Type: AWS::Serverless::Function
Properties:
CodeUri: .
Runtime: python3.8
Handler: main.handler
Tracing: Active
# Explicit log group that refers to the Lambda function
LogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub "/aws/lambda/${Function}"
# Explicit retention time
RetentionInDays: 7
이 예제에서는 Lambda 함수와 해당 로그 그룹을 생성했습니다. RetentionInDays 속성이 7일로 설정되어 있어, 이 로그 그룹의 로그는 7일 동안 보관된 후 자동으로 삭제되므로 로그 스토리지 비용을 관리하는 데 도움이 됩니다.
메트릭
이 Observability 모범 사례 가이드의 이번 섹션에서는 다음 주제를 심층적으로 다룹니다:
- 기본 제공 메트릭 모니터링 및 알림 설정
- 커스텀 메트릭 게시
- Embedded Metrics를 사용하여 로그에서 메트릭 자동 생성
- CloudWatch Lambda Insights를 사용한 시스템 수준 메트릭 모니터링
- CloudWatch 알람 생성
기본 제공 메트릭 모니터링 및 알림 설정
메트릭은 다양한 시간 간격으로 측정된 수치 데이터(시계열 데이터)이자 서비스 수준 지표(요청률, 오류율, 지속 시간, CPU 등)입니다. AWS 서비스는 애플리케이션의 운영 상태를 모니터링하는 데 도움이 되는 다양한 기본 제공 표준 메트릭을 제공합니다. 애플리케이션에 적합한 핵심 메트릭을 파악하고 이를 사용하여 애플리케이션 성능을 모니터링하세요. 핵심 메트릭의 예로는 함수 오류, 큐 깊이, 실패한 상태 머신 실행, API 응답 시간 등이 있습니다.
기본 제공 메트릭의 한 가지 과제는 CloudWatch 대시보드에서 이를 분석하는 방법을 아는 것입니다. 예를 들어, 동시 실행을 볼 때 최대값, 평균값, 백분위수 중 무엇을 확인해야 할까요? 각 메트릭에 따라 모니터링해야 할 올바른 통계가 다릅니다.
모범 사례로서, Lambda 함수의 ConcurrentExecutions 메트릭은 Count 통계를 확인하여 계정 및 리전 제한에 근접하고 있는지, 또는 Lambda 예약 동시성 제한(해당하는 경우)에 근접하고 있는지 확인하세요.
Duration 메트릭은 함수가 이벤트를 처리하는 데 걸리는 시간을 나타내며, Average 또는 Max 통계를 확인하세요. API 지연 시간을 측정하려면 API Gateway의 Latency 메트릭에서 Percentile 통계를 확인하세요. P50, P90, P99가 평균보다 훨씬 더 나은 지연 시간 모니터링 방법입니다.
모니터링할 메트릭을 파악했으면, 애플리케이션 컴포넌트가 비정상일 때 알림을 받을 수 있도록 이러한 핵심 메트릭에 알림을 구성하세요. 예를 들면:
- AWS Lambda의 경우, Duration, Errors, Throttling, ConcurrentExecutions에 알림을 설정하세요. 스트림 기반 호출의 경우 IteratorAge에, 비동기 호출의 경우 DeadLetterErrors에 알림을 설정하세요.
- Amazon API Gateway의 경우, IntegrationLatency, Latency, 5XXError, 4XXError에 알림을 설정하세요
- Amazon SQS의 경우, ApproximateAgeOfOldestMessage, ApproximateNumberOfMessageVisible에 알림을 설정하세요
- AWS Step Functions의 경우, ExecutionThrottled, ExecutionsFailed, ExecutionsTimedOut에 알림을 설정하세요
커스텀 메트릭 게시
애플리케이션에 대해 원하는 비즈니스 및 고객 결과를 기반으로 핵심 성과 지표(KPI)를 식별하세요. KPI를 평가하여 애플리케이션의 성공과 운영 상태를 판단하세요. 핵심 메트릭은 애플리케이션 유형에 따라 다를 수 있지만, 사이트 방문 수, 주문 건수, 항공권 구매 수, 페이지 로드 시간, 고유 방문자 수 등이 예시가 됩니다.
커스텀 메트릭을 AWS CloudWatch에 게시하는 한 가지 방법은 CloudWatch 메트릭 SDK의 putMetricData API를 호출하는 것입니다. 그러나 putMetricData API 호출은 동기식이므로 Lambda 함수의 실행 시간을 늘리고 애플리케이션의 다른 API 호출을 차단하여 성능 병목을 초래할 수 있습니다. 또한 Lambda 함수의 실행 시간이 길어지면 더 높은 비용으로 이어집니다. 추가로 CloudWatch로 전송되는 커스텀 메트릭 수와 API 호출(즉, PutMetricData API 호출) 수 모두에 대해 요금이 부과됩니다.
커스텀 메트릭을 게시하는 더 효율적이고 비용 효과적인 방법은 CloudWatch Embedded Metrics Format (EMF)를 사용하는 것입니다. CloudWatch Embedded Metric Format을 사용하면 CloudWatch 로그에 기록된 로그로서 커스텀 메트릭을 비동기적으로 생성할 수 있어 더 낮은 비용으로 애플리케이션 성능을 향상시킬 수 있습니다. EMF를 사용하면 상세한 로그 이벤트 데이터와 함께 커스텀 메트릭을 포함할 수 있으며, CloudWatch가 이러한 커스텀 메트릭을 자동으로 추출하여 기본 제공 메트릭과 동일하게 시각화하고 알람을 설정할 수 있습니다. Embedded Metric Format으로 로그를 전송하면 CloudWatch Logs Insights를 사용하여 쿼리할 수 있으며, 메트릭 비용이 아닌 쿼리 비용만 지불하면 됩니다.
이를 달성하려면 EMF 사양을 사용하여 로그를 생성하고 PutLogEvents API를 통해 CloudWatch로 전송할 수 있습니다. 이 과정을 단순화하기 위해, EMF 형식으로 메트릭 생성을 지원하는 두 가지 클라이언트 라이브러리가 있습니다.
- 저수준 클라이언트 라이브러리 (aws-embedded-metrics)
- Lambda Powertools Metrics
CloudWatch Lambda Insights를 사용한 시스템 수준 메트릭 모니터링
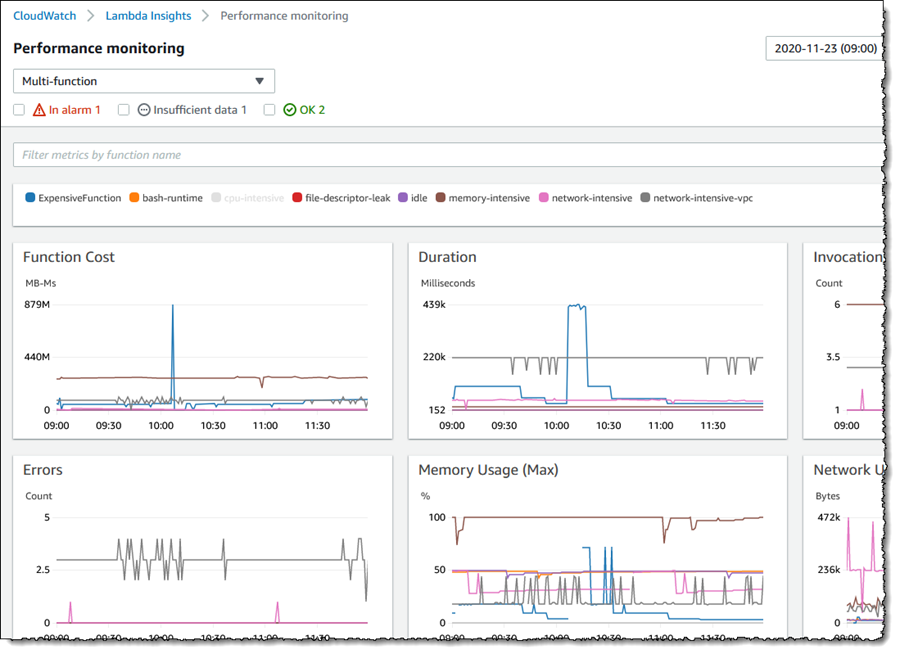
CloudWatch Lambda Insights는 CPU 시간, 메모리 사용량, 디스크 활용률, 네트워크 성능을 포함한 시스템 수준 메트릭을 제공합니다. Lambda Insights는 또한 **콜드 스타트**와 Lambda 워커 종료와 같은 진단 정보를 수집, 집계, 요약합니다. Lambda Insights는 Lambda 레이어로 패키징된 CloudWatch Lambda 확장을 활용합니다. 활성화되면 시스템 수준 메트릭을 수집하고, 해당 Lambda 함수의 모든 호출에 대해 Embedded Metrics Format으로 단일 성능 로그 이벤트를 CloudWatch Logs에 전송합니다.
CloudWatch Lambda Insights는 기본적으로 활성화되어 있지 않으며, Lambda 함수별로 개별 설정해야 합니다.
AWS 콘솔 또는 Infrastructure as Code(IaC)를 통해 활성화할 수 있습니다. 다음은 AWS Serverless Application Model(SAM)을 사용하여 활성화하는 예제입니다. Lambda 함수에 LambdaInsightsExtension 확장 레이어를 추가하고, 관리형 IAM 정책 CloudWatchLambdaInsightsExecutionRolePolicy를 추가하여 Lambda 함수가 로그 스트림을 생성하고 PutLogEvents API를 호출하여 로그를 기록할 수 있는 권한을 부여합니다.
// Add LambdaInsightsExtension Layer to your function resource
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Layers:
- !Sub "arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension:14"
// Add IAM policy to enable Lambda function to write logs to CloudWatch
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Policies:
- `CloudWatchLambdaInsightsExecutionRolePolicy`
그런 다음 CloudWatch 콘솔의 Lambda Insights에서 이러한 시스템 수준 성능 메트릭을 확인할 수 있습니다.
CloudWatch 알람 생성
CloudWatch 알람을 생성하고 메트릭이 임계값을 초과할 때 적절한 조치를 취하는 것은 Observability의 핵심 요소입니다. Amazon CloudWatch 알람은 애플리케이션 및 인프라 메트릭이 고정 또는 동적으로 설정된 임계값을 초과할 때 알림을 �보내거나 자동 복구 작업을 수행하는 데 사용됩니다.
메트릭에 알람을 설정하려면, 일련의 작업을 트리거하는 임계값을 선택합니다. 고정된 임계값은 정적 임계값이라고 합니다. 예를 들어, Lambda 함수의 Throttles 메트릭에 대해 5분 이내에 10%를 초과하면 활성화되도록 알람을 구성할 수 있습니다. 이는 Lambda 함수가 해당 계정과 리전의 최대 동시성에 도달했음을 의미할 수 있습니다.
서버리스 애플리케이션에서는 SNS(Simple Notification Service)를 사용하여 알림을 보내는 것이 일반적입니다. 이를 통해 사용자는 이메일, SMS 또는 기타 채널로 알림을 받을 수 있습니다. 또한 SNS 주제에 Lambda 함수를 구독하여 알람을 발생시킨 문제를 자동으로 복구할 수도 있습니다.
예를 들어, SQS 큐를 폴링하고 다운스트림 서비스를 호출하는 Lambda 함수 A가 있다고 가정해 보겠습니다. 다운스트림 서비스가 중단되어 응답하지 않으면 Lambda 함수는 계속 SQS에서 폴링하여 다운스트림 서비스를 호출하면서 실패를 반복합니다. 이러한 오류를 모니터링하고 SNS를 사용하여 적절한 팀에 CloudWatch 알람 알림을 보내는 것도 가능하지만, SNS 구독을 통해 다른 Lambda 함수 B를 호출하여 Lambda 함수 A의 이벤트 소스 매핑을 비활성화하고, 다운스트림 서비스가 복구될 때까지 SQS 큐 폴링을 중단할 수도 있습니다.
개별 메트릭에 알람을 설정하는 것도 좋지만, 때로는 애플리케이션의 운영 상태와 성능을 더 잘 이해하기 위해 여러 메트릭을 모니터링해야 할 수 있습니다. 이런 경우, 메트릭 수학 표현식을 사용하여 여러 메트릭 기반 알람을 설정해야 합니다.
예를 들어, AWS Lambda 오류를 모니터링하되 소수의 오류는 알람을 트리거하지 않도록 허용하고 싶다면, 오류율 표현식을 백분율 형태로 만들 수 있습니다. 즉, ErrorRate = errors / invocation * 100으로 설정한 후, 구성된 평가 기간 내에 ErrorRate가 20%를 초과하면 알림을 보내도록 알람을 생성할 수 있습니다.
트레이싱
이 Observability 모범 사례 가이드의 이번 섹션에서는 다음 주제를 심층적으로 다룹니다:
- 분산 트레이싱과 AWS X-Ray 소개
- 적절한 샘플링 규칙 적용
- X-Ray SDK를 사용한 다른 서비스와의 상호작용 트레이싱
- X-Ray SDK를 사용한 통합 서비스 트레이싱 코드 예제
분산 트레이싱과 AWS X-Ray 소개
대부분의 서버리스 애플리케이션은 여러 마이크로서비스로 구성되며, 각 마이크로서비스는 여러 AWS 서비스를 사용합니다. 서버리스 아키텍처의 특성상 분산 트레이싱을 갖추는 것이 매우 중요합니다. 효과적인 성능 모니터링과 오류 추적을 위해서는 소스 호출자부터 모든 다운스트림 서비스까지 전체 애플리케이션 흐름에 걸쳐 트랜잭션을 트레이싱하는 것이 중요합니다. 개별 서비스의 로그를 사용하여 이를 달성할 수도 있지만, AWS X-Ray와 같은 트레이싱 도구를 사용하는 것이 �더 빠르고 효율적입니다. 자세한 내용은 AWS X-Ray로 애플리케이션 계측하기를 참고하세요.
AWS X-Ray를 사용하면 관련된 마이크로서비스를 거치는 요청을 트레이싱할 수 있습니다. X-Ray 서비스 맵을 통해 다양한 통합 지점을 이해하고 애플리케이션의 성능 저하를 식별할 수 있습니다. 몇 번의 클릭만으로 오류, 스로틀링, 지연 문제를 일으키는 컴포넌트를 빠르게 격리할 수 있습니다. 서비스 그래프에서 개별 트레이스를 확인하여 각 마이크로서비스가 소요한 정확한 시간도 파악할 수 있습니다.
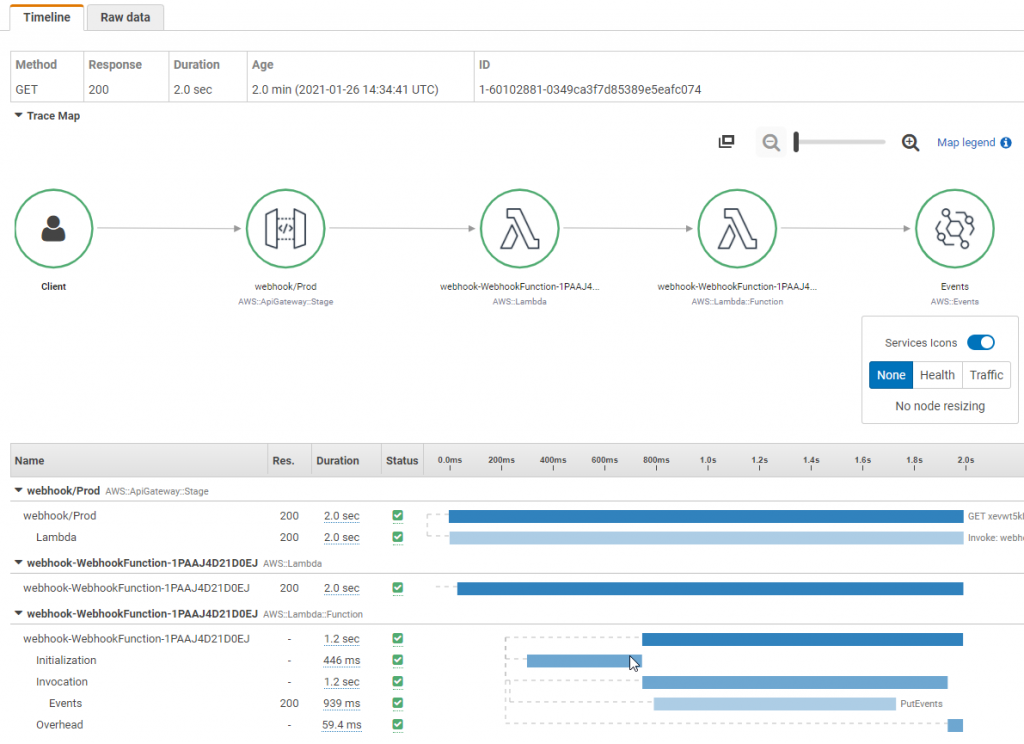
모범 사례로서, 다운스트림 호출이나 모니터링이 필요한 특정 기능에 대해 코드에 커스텀 하위 세그먼트를 생성하세요. 예를 들어, 외부 HTTP API 호출이나 SQL 데이터베이스 쿼리를 모니터링하기 위한 하위 세그먼트를 생성할 수 있습니다.
예를 들어, 다운스트림 서비스를 호출하는 함수에 커스텀 하위 세그먼트를 생성하려면 captureAsyncFunc 함수(node.js)를 사용합니다:
var AWSXRay = require('aws-xray-sdk');
app.use(AWSXRay.express.openSegment('MyApp'));
app.get('/', function (req, res) {
var host = 'api.example.com';
// start of the subsegment
AWSXRay.captureAsyncFunc('send', function(subsegment) {
sendRequest(host, function() {
console.log('rendering!');
res.render('index');
// end of the subsegment
subsegment.close();
});
});
});
이 예제에서 애플리케이션은 sendRequest 함수 호출을 위해 send라는 커스텀 하위 세그먼트를 생성합니다. captureAsyncFunc는 하위 세그먼트를 전달하며, 비동기 호출이 완료되면 콜백 함수 내에서 이를 닫아야 합니다.
적절한 샘플링 규칙 적용
AWS X-Ray SDK는 기본적으로 모든 요청을 트레이싱하지 않습니다. 높은 비용을 발생시키지 않으면서 대표적인 요청 샘플을 제공하기 위해 보수적인 샘플링 규칙을 적용합니다. 그러나 특정 요구 사항에 따라 기본 샘플링 규칙을 커스터마이즈하거나 샘플링을 완전히 비활성화하고 모든 요청을 트레이싱할 수 있습니다.
AWS X-Ray는 감사 또는 규정 준수 도구로 사용하도록 설계되지 않았다는 점에 유의하세요. 애플리케이션 유형에 따라 서로 다른 샘플링 비율을 고려해야 합니다. 예를 들어, 백그라운드 폴링이나 헬스 체크와 같은 대량 읽기 전용 호출은 낮은 비율로 샘플링하면서도 잠재적 문제를 식별할 수 있는 충분한 데이터를 제공할 수 있습니다. 또한 환경별로 서로 다른 샘플링 비율을 적용할 수도 있습니다. 예를 들어, 개발 환경에서는 오류나 성능 문제를 쉽게 해결하기 위해 모든 요청을 트레이싱하고, 프로덕션 환경에서는 트레이스 수를 줄일 수 있습니다. 과도한 트레이싱은 비용 증가로 이어질 수 있다는 점도 염두에 두어야 합니다. 샘플링 규칙에 대한 자세한 내용은 X-Ray 콘솔에서 샘플링 규칙 구성을 참고하세요.
X-Ray SDK를 사용한 다른 AWS 서비스와의 상호작용 트레이싱
X-Ray 트레이싱은 AWS Lambda와 Amazon API Gateway 같은 서비스에서 몇 번의 클릭이나 IaC 도구의 몇 줄만으로 쉽게 활성화할 수 있지만, 다른 서비스는 코드를 계측하는 추가 단계가 필요합니다. X-Ray와 통합된 AWS 서비스 전체 목록을 참고하세요.
DynamoDB와 같이 X-Ray와 직접 통합되�지 않는 서비스에 대한 호출을 계측하려면, AWS SDK 호출을 AWS X-Ray SDK로 래핑하여 트레이스를 캡처할 수 있습니다. 예를 들어 node.js를 사용할 때, 아래 코드 예제를 따라 모든 AWS SDK 호출을 캡처할 수 있습니다:
X-Ray SDK를 사용한 통합 서비스 트레이싱 코드 예제
//... FROM (old code)
const AWS = require('aws-sdk');
//... TO (new code)
const AWSXRay = require('aws-xray-sdk-core');
const AWS = AWSXRay.captureAWS(require('aws-sdk'));
...
개별 클라이언트를 계측하려면 AWS SDK 클라이언트를 AWSXRay.captureAWSClient 호출로 래핑하세요. captureAWS와 captureAWSClient를 함께 사용하지 마세요. 이는 중복 트레이스를 발생시킵니다.
추가 리소스
요약
이 AWS Lambda 기반 서버리스 애플리케이션을 위한 Observability 모범 사례 가이드에서는 Amazon CloudWatch와 AWS X-Ray 같은 AWS 네이티브 서비스를 사용한 로깅, 메트릭, 트레이싱의 핵심 사항을 강조했습니다. 애플리케이션에 Observability 모범 사례를 쉽게 적용할 수 있도록 AWS Lambda Powertools 라이브러리 사용을 권장했습니다. 이러한 모범 사례를 채택함으로써 서버리스 애플리케이션에 대한 귀중한 인사이트를 확보하여 오류를 더 빠르게 감지하고 성능을 최적화할 수 있습니다.
더 깊은 학습을 위해, AWS One Observability Workshop의 AWS 네이티브 Observability 모듈을 직접 실습해 보시길 강력히 권장합니다.