AWS Lambda ベースのサーバーレスオブザーバビリティ
分散システムとサーバーレスコンピューティングの世界では、オブザーバビリティの実現がアプリケーションの信頼性とパフォーマンスを確保するための鍵となります。これは従来の監視以�上のものを含みます。Amazon CloudWatch や AWS X-Ray などの AWS オブザーバビリティツールを活用することで、サーバーレスアプリケーションに関する洞察を得て、問題をトラブルシューティングし、アプリケーションのパフォーマンスを最適化できます。このガイドでは、Lambda ベースのサーバーレスアプリケーションのオブザーバビリティを実装するための重要な概念、ツール、ベストプラクティスを学びます。
インフラストラクチャまたはアプリケーションのオブザーバビリティを実装する前の最初のステップは、主要な目標を決定することです。それは、ユーザーエクスペリエンスの向上、開発者の生産性の向上、サービスレベル目標 (SLO) の達成、ビジネス収益の増加、またはアプリケーションの種類に応じたその他の特定の目標である可能性があります。そのため、これらの主要な目標を明確に定義し、それらをどのように測定するかを確立してください。次に、そこから逆算してオブザーバビリティ戦略を設計します。詳細については、「重要なものを監視する」を参照してください。
オブザーバビリティの柱
オブザーバビリティには 3 つの主要な柱があります。
- ログ: アプリケーションまたはシステム内で発生した個別のイベントのタイムスタンプ付き記録。障害、エラー、状態変換など
- メトリクス: さまざまな時間間隔で測定された数値データ (時系列データ)。SLI (リクエストレート、エラーレート、期間、CPU% など)
- トレース: トレースは、複数のアプリケーションとシステム (通常はマイクロサービス) にわたる単一ユーザーのジャーニーを表します
AWS は、AWS Lambda アプリケーションの実用的なインサイトを取得するために、ログ記録、メトリクスの監視、トレースを容易にするネイティブツールとオープンソースツールの両方を提供しています。
ログ
このオブザーバビリティのベストプラクティスガイドのセクションでは、以下のトピックについて詳しく説明します。
- 非構造化ログと構造化ログ
- CloudWatch Logs Insights
- ログの相関 ID
- Lambda Powertools を使用したコードサンプル
- CloudWatch Dashboards を使用したログの可視化
- CloudWatch Logs の保持期間
ログは、アプリケーション内で発生した個別のイベントです。これには、障害、エラー、実行パス、その他のイベントが含まれます。ログは、非構造化、半構造化、または構造化形式で記録できます。
非構造化ログと構造化ログ
開発者がアプリケーション内でシ�ンプルなログメッセージから始めることがよくあります。 print または console.log ステートメント。これらはプログラムで大規模に解析および分析することが困難です。特に、異なるロググループにわたって多くの行のログメッセージを生成する可能性がある AWS Lambda ベースのアプリケーションでは顕著です。その結果、これらのログを CloudWatch に統合することが困難になり、分析が難しくなります。ログ内の関連情報を見つけるには、テキストマッチや正規表現を使用する必要があります。以下は、非構造化ログがどのように見えるかの例です。
[2023-07-19T19:59:07Z] INFO Request started
[2023-07-19T19:59:07Z] INFO AccessDenied: Could not access resource
[2023-07-19T19:59:08Z] INFO Request finished
ご覧のとおり、ログメッセージには一貫した構造がなく、有用なインサイトを得ることが困難です。また、コンテキスト情報を追加することも難しくなっています。
一方、構造化ログは、一貫した形式 (多くの場合 JSON) で情報をログに記録する方法であり、ログをテキストではなくデータとして扱うことができるため、クエリとフィルタリングが簡単になります。これにより、開発者はプログラムでログを効率的に保存、取得、分析できるようになります。また、デバッグの改善にも役立ちます。構造化ログは、ログレベルを通じて異なる環境間でログの詳細度を変更するためのよりシンプルな方法を提供します。ログレベルに注意してください。 ログを記録しすぎると、コストが増加し、アプリケーションのスループットが低下します。ログに記録する前に、個人を特定できる情報が編集されていることを確認してください。構造化ログの例を次に示します。
{
"correlationId": "9ac54d82-75e0-4f0d-ae3c-e84ca400b3bd",
"requestId": "58d9c96e-ae9f-43db-a353-c48e7a70bfa8",
"level": "INFO",
"message": "AccessDenied",
"function-name": "demo-observability-function",
"cold-start": true
}
**Prefer structured and centralized logging into CloudWatch logsトランザクションに関する運用情報、異なるコンポーネント間の相関識別子、およびアプリケーションからのビジネス成果を出力します。
CloudWatch Logs Insights
CloudWatch Logs Insights を使用します。これは JSON 形式のログ内のフィールドを自動的に検出できます。さらに、JSON ログを拡張して、アプリケーション固有のカ�スタムメタデータをログに記録し、ログの検索、フィルタリング、集計に使用できます。
ログ相関 ID
たとえば、API Gateway から受信する HTTP リクエストの場合、相関 ID は次の場所で設定されます requestContext.requestId パスは、Lambda powertools を使用してダウンストリームの Lambda 関数で簡単に抽出してログに記録できます。分散システムでは、多くの場合、複数のサービスとコンポーネントが連携してリクエストを処理します。そのため、相関 ID をログに記録し、ダウンストリームシステムに渡すことは、エンドツーエンドのトレースとデバッグにとって非常に重要です。相関 ID は、リクエストの最初に割り当てられる一意の識別子です。リクエストがさまざまなサービスを経由する際、相関 ID がログに含まれるため、リクエストの全体的なパスをトレースできます。AWS Lambda ログに相関 ID を手動で挿入するか、AWS Lambda powertools などのツールを使用して API Gateway から相関 ID を簡単に取得し、アプリケーションログと共にログに記録できます。たとえば、HTTP リクエストの場合、相関 ID は request-id にすることができ、API Gateway で開始してから Lambda 関数などのバックエンドサービスに渡すことができます。
Lambda Powertools を使用したコ�ードサンプル
ベストプラクティスとして、リクエストライフサイクルのできるだけ早い段階で相関 ID を生成します。できれば、API Gateway やアプリケーションロードバランサーなど、サーバーレスアプリケーションのエントリポイントで生成することをお勧めします。UUID、リクエスト ID、または分散システム全体でリクエストを追跡するために使用できるその他の一意の属性を使用します。カスタムヘッダー、ボディ、またはメタデータの一部として、各リクエストとともに相関 ID を渡します。ダウンストリームサービスのすべてのログエントリとトレースに相関 ID が含まれていることを確認してください。
Lambda 関数ログの一部として相関 ID を手動でキャプチャして含めるか、AWS Lambda Powertools のようなツールを使用できます。Lambda Powertools を使用すると、サポートされているアップストリームサービスの事前定義されたリクエストパスマッピングから相関 ID を簡単に取得し、アプリケーションログと一緒に自動的に追加できます。また、障害が発生した場合に簡単にデバッグして根本原因を特定し、元のリクエストに結び付けられるように、すべてのエラーメッセージに相関 ID が追加されていることを確認してください。
以下のサーバーレスアーキテクチャにおいて、相関 ID を使用した構造化ログと CloudWatch での表示を実演するコードサンプルを見てみましょう。

// Initializing Logger
Logger log = LogManager.getLogger();
// Uses @Logger annotation from Lambda Powertools, which takes optional parameter correlationIdPath to extract correlation Id from the API Gateway header and inserts correlation_id to the Lambda function logs in a structured format.
@Logging(correlationIdPath = "/headers/path-to-correlation-id")
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
...
// The log statement below will also have additional correlation_id
log.info("Success")
...
}
この例では、Java ベースの Lambda 関数が Lambda Powertools ライブラリを使用してログを記録しています correlation_id API Gateway リクエストから送信されます。
コードサンプルの CloudWatch ログのサンプル:
{
"level": "INFO",
"message": "Success",
"function-name": "demo-observability-function",
"cold-start": true,
"lambda_request_id": "52fdfc07-2182-154f-163f-5f0f9a621d72",
"correlation_id": "<correlation_id_value>"
}_
CloudWatch Dashboards を使用したログの可視化
データを構造化された JSON 形式でログに記録すると、CloudWatch Logs Insights は JSON 出力内の値を自動的��に検出し、メッセージをフィールドとして解析します。CloudWatch Logs Insights は、複数のログストリームを検索およびフィルタリングするための専用の SQL ライクなクエリ言語を提供します。glob や正規表現パターンマッチングを使用して、複数のログループに対してクエリを実行できます。さらに、カスタムクエリを作成して保存し、毎回再作成することなく再実行することもできます。
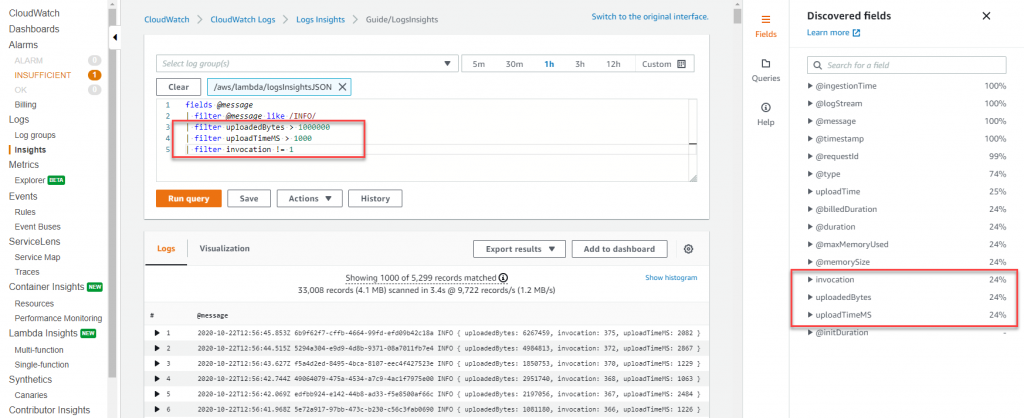 CloudWatch Logs Insights では、1 つ以上の集計関数を使用したクエリから、折れ線グラフ、棒グラフ、積み上げ面グラフなどの視覚化を生成できます。これらの視覚化を CloudWatch ダッシュボードに簡単に追加できます。以下のサンプルダッシュボードは、Lambda 関数の実行時間のパーセンタイルレポートを示しています。このようなダッシュボードを使用すると、アプリケーションのパフォーマンス向上に注力すべき箇所をすばやく把握できます。平均レイテンシーは確認すべき優れたメトリクスですが、
CloudWatch Logs Insights では、1 つ以上の集計関数を使用したクエリから、折れ線グラフ、棒グラフ、積み上げ面グラフなどの視覚化を生成できます。これらの視覚化を CloudWatch ダッシュボードに簡単に追加できます。以下のサンプルダッシュボードは、Lambda 関数の実行時間のパーセンタイルレポートを示しています。このようなダッシュボードを使用すると、アプリケーションのパフォーマンス向上に注力すべき箇所をすばやく把握できます。平均レイテンシーは確認すべき優れたメトリクスですが、you should aim to optimize for p99 and not the average latency.
 CloudWatch 以外の場所に (プラットフォーム、関数、拡張機能の) ログを送信するには、Lambda Extensions で Lambda Telemetry API を使用できます。多数のパートナーソリューションが Lambda Telemetry API を使用する Lambda レイヤーを提供しており、それらのシステムとの統合を容易にします。
CloudWatch 以外の場所に (プラットフォーム、関数、拡張機能の) ログを送信するには、Lambda Extensions で Lambda Telemetry API を使用できます。多数のパートナーソリューションが Lambda Telemetry API を使用する Lambda レイヤーを提供しており、それらのシステムとの統合を容易にします。
CloudWatch Logs Insights を最大限に活用するには、構造化ログの形式でログに取り込む必要があるデータについて検討してください。これにより、アプリケーションの健全性をより適切に監視できるようになります。
CloudWatch Logs 保持期間
デフォルトでは、Lambda 関数で stdout に書き込まれるすべてのメッセージが Amazon CloudWatch ログストリームに保存されます。Lambda 関数の実行ロールには、CloudWatch ログストリームを作成し、ストリームにログイベントを書き込む権限が必要です。CloudWatch はデータの取り込み量と使用されるストレージによって課金されることに注意することが重要です。そのため、ログ記録の量を減らすことで、関連するコストを最小限に抑えることができます。By default CloudWatch logs are kept indefinitely and never expire. It is recommended to configure log retention policy to reduce log-storage costs**、すべてのロググループに適用します。環境ごとに異なる保持ポリシーが必要になる場合があります。ログ保持は AWS コンソールで手動で設定できますが、一貫性とベストプラクティスを確�保するために、Infrastructure as Code (IaC) デプロイの一部として設定する必要があります。以下は、Lambda 関数のログ保持を設定する方法を示す CloudFormation テンプレートのサンプルです。
Resources:
Function:
Type: AWS::Serverless::Function
Properties:
CodeUri: .
Runtime: python3.8
Handler: main.handler
Tracing: Active
# Explicit log group that refers to the Lambda function
LogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub "/aws/lambda/${Function}"
# Explicit retention time
RetentionInDays: 7
この例では、Lambda 関数と対応するロググループを作成しました。**RetentionInDaysプロパティは 7 日間に設定されています。つまり、このロググループ内のログは 7 日間保持された後、自動的に削除されます。これにより、ログストレージのコストを管理できます。
メトリクス
このオブザーバビリティのベストプラクティスガイドのセクションでは、以下のトピックについて詳しく説明します。
- すぐに使えるメトリクスを監視してアラートを設定
- カスタムメトリクスを発行
- embedded-metrics を使用してログから自動的にメトリクスを生成
- CloudWatch Lambda Insights を使用してシステムレベルのメトリクスを監視
- CloudWatch アラームの作成
すぐに使えるメトリクスの監視とアラート
メトリクスは、さまざまな時間間隔で測定される数値データ (時系列データ) およびサービスレベルインジケーター (リクエストレート、エラーレート、期間、CPU など) です。AWS サービスは、アプリケーションの運用状態の監視に役立つ、すぐに使用できる標準メトリクスを多数提供しています。アプリケーションに適用可能な主要なメトリクスを確立し、それらを使用してアプリケーションのパフォーマンスを監視します。主要なメトリクスの例には、関数エラー、キューの深さ、失敗したステートマシンの実行、API レスポンス時間などがあります。
すぐに使えるメトリクスの課題の 1 つは、CloudWatch ダッシュボードでそれらを分析する方法を知ることです。たとえば、Concurrency を見る場合、最大値、平均値、またはパーセンタイルのどれを見るべきでしょうか。また、監視すべき適切な統計情報は、メトリクスごとに異なります。
ベストプラクティスとして、Lambda 関数の ConcurrentExecutions メトリクスは Count 統計を確認して、アカウントおよびリージョンの制限に近づいているか、または該当する場合は Lambda の予約済み�同時実行数の制限に近づいているかを確認します。
次の場合 Duration イベントの処理に関数がかかる時間を示すメトリクスを確認します。 Average または Max 統計。API のレイテンシーを測定するには、 Percentile API Gateway の統計 Latency メトリクス。P50、P90、P99 は、平均よりもレイテンシーを監視するはるかに優れた方法です。
監視するメトリクスを決定したら、これらの主要なメトリクスにアラートを設定して、アプリケーションのコンポーネントが正常でない場合に通知を受け取れるようにします。例えば
- AWS Lambda の場合、Duration、Errors、Throttling、ConcurrentExecutions についてアラートを設定します。ストリームベースの呼び出しの場合は IteratorAge についてアラートを設定します。非同期呼び出しの場合は DeadLetterErrors についてアラートを設定します。
- Amazon API Gateway の場合、IntegrationLatency、Latency、5XXError、4XXError についてアラートを設定します。
- Amazon SQS の場合、ApproximateAgeOfOldestMessage、ApproximateNumberOfMessageVisible についてアラートを設定します。
- AWS Step Functions の場合、ExecutionThrottled、ExecutionsFailed、ExecutionsTimedOut についてアラートを設定します。
カスタムメトリクスの発行
アプリケーションの望ましいビジネス成果と顧客成果に基づいて、主要業績評価指標 (KPI) を特定します。KPI を評価して、アプリケーションの成功と運用の健全性を判断します。主要なメトリクスはアプリケーションの種類によって異なる場合がありますが、例としては、サイト訪問数、注文数、購入されたフライト数、ページ読み込み時間、ユニークビジター数などがあります。
AWS CloudWatch にカスタムメトリクスを発行する方法の 1 つは、CloudWatch メトリクス SDK を呼び出すことです。 putMetricData API。ただし、 putMetricData API 呼び出しは同期的です。Lambda 関数の実行時間が長くなり、アプリケーション内の他の API 呼び出しをブロックする可能性があり、パフォーマンスのボトルネックにつながります。また、Lambda 関数の実行時間が長くなると、コストが高くなります。さらに、CloudWatch に送信されるカスタムメトリクスの数と、実行される API 呼び出しの数 (つまり PutMetricData API 呼び出し) の両方に対して課金されます。
A more efficient and cost-effective way to publish custom metrics is with CloudWatch Embedded Metrics Format (EMF)。CloudWatch Embedded Metric Format を使用すると、カスタムメトリクスを生成できます asynchronously CloudWatch Logs に書き込まれるログとして送信されるため、アプリケーションのパフォーマンスが向上し、コストも削減されます。EMF を使用すると、詳細なログイベントデータと共にカスタムメトリクスを埋め込むことができ、CloudWatch はこれらのカスタムメトリクスを自動的に抽出するため、標準メトリクスと同様に可視化やアラーム設定が可能になります。埋め込みメトリクス形式でログを送信することで、CloudWatch Logs Insights を使用してクエリを実行でき、メトリクスのコストではなくクエリのコストのみを支払うことになります。
これを実現するには、EMF 仕様を使用してログを生成し、CloudWatch に送信します。 PutLogEvents API。プロセスを簡素化するために、EMF 形式でのメトリクスの作成をサポートする 2 つのクライアントライブラリがあります。
- 低レベルクライアントライブラリ (aws-embedded-metrics)
- Lambda Powertools Metrics
CloudWatch Lambda Insights を使用してシステムレベルのメトリクスを監視する
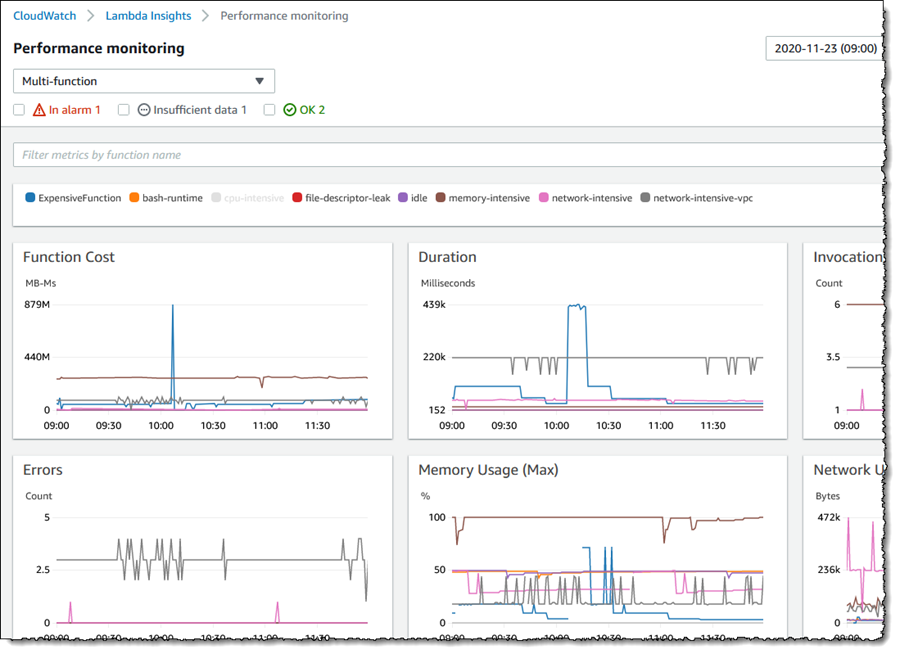
CloudWatch Lambda Insights を使用してシステムレベルのメトリクスを監視する
CloudWatch Lambda Insights は、CPU 時間、メモリ使用量、ディスク使用率、ネットワークパフォーマンスなどのシステムレベルのメトリクスを提供します。
また、コールドスタート や Lambda ワーカーのシャットダウンなどの診断情報を収集、集約、要約します。
Lambda Insights は、Lambda レイヤーとしてパッケージ化された CloudWatch Lambda 拡張機能を活用します。
有効化すると、システムレベルのメトリクスを収集し、Lambda 関数の呼び出しごとに 1 つのパフォーマンスログイベントを組み込みメトリクス形式で CloudWatch Logs に出力します。
CloudWatch Lambda Insights はデフォルトでは有効になっておらず、Lambda 関数ごとに有効にする必要があります。
AWS コンソールまたは Infrastructure as Code (IaC) を使用して有効にできます。AWS サーバーレスアプリケーションモデル (SAM) を使用して有効にする方法の例を次に示します。次を追加します LambdaInsightsExtension extension Layer を Lambda 関数に追加し、マネージド IAM ポリシーも追加します CloudWatchLambdaInsightsExecutionRolePolicyLambda 関数にログストリームを作成して呼び出す権限を付与します PutLogEvents API を使用してログを書き込むことができます。
// Add LambdaInsightsExtension Layer to your function resource
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Layers:
- !Sub "arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension:14"
// Add IAM policy to enable Lambda function to write logs to CloudWatch
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Policies:
- `CloudWatchLambdaInsightsExecutionRolePolicy`
CloudWatch コンソールを使用して、Lambda Insights でこれらのシステムレベルのパフォーマンスメトリクスを表示できます。
CloudWatch アラームの作成
CloudWatch アラームを作成し、メトリクスが異常値を示したときに必要なアクションを実行することは、オブザーバビリティの重要な部分です。Amazon CloudWatch アラームは、アプリケーションとインフラストラクチャのメトリクスが静的または動的に設定されたしきい値を超えたときに、アラートを送信したり、自動的に修復アクションを実行したりするために使用されます。
メトリクスのアラームを設定するには、一連のアクションをトリガーするしきい値を選択します。固定されたしきい値は、静的しきい値として知られています。たとえば、次のようなアラームを設定できます。 Throttles Lambda 関数からのメトリクスが 5 分間の期間内で 10% を超えた場合にアクティブ化します。これは、Lambda 関数がアカウントとリージョンの最大同時実行数に達した可能性があることを意味します。
サーバーレスアプリケーションでは、SNS (Simple Notification Service) を使用してアラートを送信することが一般的です。これにより、ユーザーは電子メール、SMS、またはその他のチャネルを介してアラートを受信できます。さらに、SNS トピックに Lambda 関数をサブスクライブすることで、ア�ラームをトリガーした問題を自動修復できるようになります。
たとえば、SQS キューをポーリングしてダウンストリームサービスを呼び出す Lambda 関数 A があるとします。ダウンストリームサービスがダウンして応答しない場合、Lambda 関数は SQS からのポーリングを続け、失敗しながらもダウンストリームサービスの呼び出しを試行します。これらのエラーを監視し、SNS を使用して CloudWatch アラームを生成して適切なチームに通知することもできますが、別の Lambda 関数 B を(SNS サブスクリプション経由で)呼び出すこともできます。この関数は Lambda 関数 A のイベントソースマッピングを無効化し、ダウンストリームサービスが復旧して稼働するまで SQS キューからのポーリングを停止させることができます。
個々のメトリクスにアラームを設定することは良いことですが、アプリケーションの運用状態とパフォーマンスをより深く理解するために、複数のメトリクスを監視する必要がある場合があります。このようなシナリオでは、メトリクス計算式を使用して、複数のメトリクスに基づいてアラームを設定する必要があります。
たとえば、AWS Lambda のエラーを監視したいが、アラームをトリガーせずに少数のエラーを許容したい場合、パーセンテージの形式でエラー率の式を作成できます。つまり、ErrorRate = errors / invocation * 100 とし、設定された評価期間内に ErrorRate が 20% を超えた場合にアラートを送信するアラームを作成します。
トレーシング
このオブザーバビリティのベストプラクティスガイドのセクションでは、以下のトピックについて詳しく説明します。
- 分散トレーシングと AWS X-Ray の概要
- 適切なサンプリングルールの適用
- X-Ray SDK を使用した他のサービスとのインタラクションのトレース
- X-Ray SDK を使用した統合サービスのトレースのコードサンプル
分散トレーシングと AWS X-Ray の概要
ほとんどのサーバーレスアプリケーションは、複数のマイクロサービスで構成されており、それぞれが複数の AWS サービスを使用しています。サーバーレスアーキテクチャの性質上、分散トレーシングが不可欠です。効果的なパフォーマンス監視とエラー追跡のためには、ソース呼び出し元からすべてのダウンストリームサービスまで、アプリケーションフロー全体にわたってトランザクションをトレースすることが重要です。個々のサービスのログを使用してこれを実現することは可能ですが、AWS X-Ray のようなトレーシングツールを使用する方が高速で効率的です。詳細については、AWS X-Ray によるアプリケーションのイ�ンストルメント化を参照してください。
AWS X-Ray を使用すると、関連するマイクロサービスを通過するリクエストをトレースできます。X-Ray サービスマップを使用すると、さまざまな統合ポイントを理解し、アプリケーションのパフォーマンス低下を特定できます。わずか数回のクリックで、アプリケーションのどのコンポーネントがエラー、スロットリング、またはレイテンシーの問題を引き起こしているかを迅速に分離できます。サービスグラフの下で、個々のトレースを確認して、各マイクロサービスが要した正確な期間を特定することもできます。
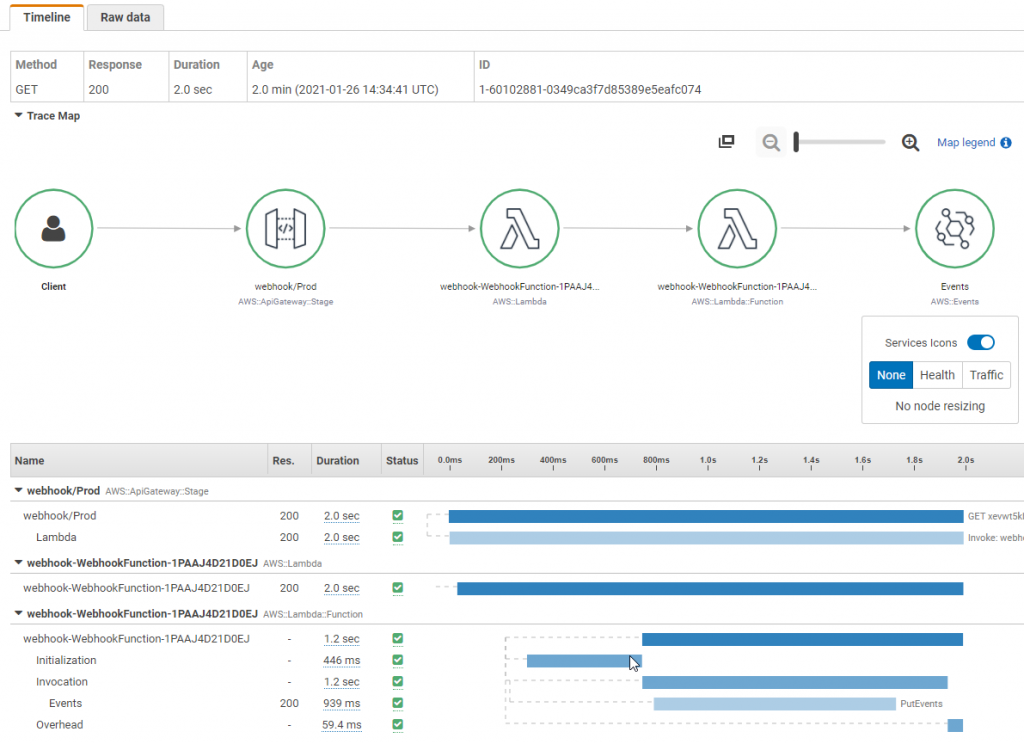
As a best practice, create custom subsegments in your code for downstream calls または監視が必要な特定の機能に対して使用できます。たとえば、外部 HTTP API への呼び出しや SQL データベースクエリを監視するためのサブセグメントを作成できます。
たとえば、ダウンストリームサービスへの呼び出しを行う関数のカスタムサブセグメントを作成するには、 captureAsyncFunc 関数 (node.js 内)
var AWSXRay = require('aws-xray-sdk');
app.use(AWSXRay.express.openSegment('MyApp'));
app.get('/', function (req, res) {
var host = 'api.example.com';
// start of the subsegment
AWSXRay.captureAsyncFunc('send', function(subsegment) {
sendRequest(host, function() {
console.log('rendering!');
res.render('index');
// end of the subsegment
subsegment.close();
});
});
});
この例では、アプリケーションは次の名前のカスタムサブセグメントを作成します send への呼び出しに対して sendRequest 関数。 captureAsyncFunc 非同期呼び出しが完了したときに、コールバック関数内で閉じる必要があるサブセグメントを渡します。
適切なサンプリングルールを適用する
AWS X-Ray SDK は、デフォルトではすべてのリクエストをトレースしません。高コストを発生させることなく、リクエストの代表的なサンプルを提供するために、控えめなサンプリングルールを適用します。ただし、特定の要件に基づいて、デフォルトのサンプリングルールをカスタマイズしたり、サンプリングを完全に無効にしてすべてのリクエストのトレ��ースを開始したりできます。
AWS X-Ray は監査やコンプライアンスツールとして使用することを意図していないことに注意することが重要です。different sampling rate for different type of application。たとえば、バックグラウンドポーリングやヘルスチェックなどの大量の読み取り専用呼び出しは、低いレートでサンプリングしても、発生する可能性のある潜在的な問題を特定するのに十分なデータを提供できます。また、次のようにすることもできます。**different sampling rate per environmentたとえば、開発環境では、エラーやパフォーマンスの問題を簡単にトラブルシューティングするために、すべてのリクエストをトレースすることが望ましい場合がありますが、本番環境ではトレース数を少なくすることができます。You should also keep in mind that extensive tracing can result in increased costサンプリングルールの詳細については、X-Ray コンソールでのサンプリングルールの設定を参照してください。
X-Ray SDK を使用して他の AWS サービスとのインタラクションをトレースする
X-Ray トレーシングは、AWS Lambda や Amazon API Gateway などのサービスでは、数回のクリックまたは IaC ツールでの数行の記述で簡単に有効化できますが、他のサービスではコードをインストルメント化するための追加手順が必要です。X-Ray と統合された AWS サービスの完全なリストはこちらです。
DynamoDB など、X-Ray と統合されていないサービスへの呼び出しをインストルメント化するには、AWS SDK 呼び出しを AWS X-Ray SDK でラップすることでトレースをキャプチャできます。たとえば、node.js を使用する場合、以下のコード例に従ってすべての AWS SDK 呼び出しをキャプチャできます。
X-Ray SDK を使用した統合サービスのトレースのコードサンプル
//... FROM (old code)
const AWS = require('aws-sdk');
//... TO (new code)
const AWSXRay = require('aws-xray-sdk-core');
const AWS = AWSXRay.captureAWS(require('aws-sdk'));
...
個々のクライアントをインストルメント化するには、AWS SDK クライアントを呼び出しでラップします。 AWSXRay.captureAWSClient. 両方を使用しないでください captureAWS および captureAWSClient 一緒に使用すると、トレースが重複します。
その他のリソース
まとめ
この AWS Lambda ベースのサーバーレスアプリケーション向けのオブザーバビリティベストプラクティスガイドでは、Amazon CloudWatch や AWS X-Ray などのネイティブ AWS サービスを使用したロギング、メトリクス、トレーシングなどの重要な側面を取り上げました。AWS Lambda Powertools ライブラリを使用して、アプリケーションにオブザーバビリティのベストプラクティスを簡単に追加することを推奨しました。これらのベストプラクティスを採用することで、サーバーレスアプリケーシ��ョンに関する貴重な洞察を得ることができ、エラー検出の高速化とパフォーマンスの最適化が可能になります。
さらに深く学習するには、AWS One Observability Workshop の AWS Native Observability モジュールを実践することを強くお勧めします。