AWS オブザーバビリティ成熟度モデル
はじめに
オブザーバビリティの本質は、システムの外部出力を分析することで、システムの��内部状態を理解し、洞察を得る能力です。 この概念は、事前に定義されたメトリクスやイベントに焦点を当てた従来の監視アプローチから、環境内のさまざまなコンポーネントが生成するデータの収集、分析、可視化を包括する、より総合的なアプローチへと進化してきました。 システムは観察されなければ、制御も最適化もできません。 効果的なオブザーバビリティ戦略により、チームは問題を素早く特定して解決し、リソースの使用を最適化し、システム全体の健全性に関する洞察を得ることができます。 オブザーバビリティは、問題を効率的に検出、調査、修復する能力を提供し、ワークロードの全体的な運用可用性と健全性を向上させることができます。

モニタリングとオブザーバビリティの違いは、モニタリングがシステムが機能しているかどうかを示すのに対し、オブザーバビリティはシステムが機能していない理由を示すことです。 モニタリングは通常、事後対応的な手段ですが、オブザーバビリティの目標は、主要業績評価指標 (KPI) を事前対応的に改善できるようにすることです。 継続的なモニタリングとオブザーバビリティは、クラウド環境におけるアジリティの向上、カスタマーエクスペリエンスの改善、リスクの低減を実現します。
オブザーバビリティ成熟度モデル
オブザーバビリティ成熟度モデルは、ワークロードのオブザーバビリティと管理プロセスの最適化を目指す組織にとって、重要なフレームワークとして機能します。
このモデルは、企業が現在の能力を評価し、改善が必要な領域を特定し、最適なオブザーバビリティを実現するために適切なツールとプロセスに戦略的に投資するための包括的なロードマップを提供します。
クラウドコンピューティング、マイクロサービス、エフェメラルおよび分散システムの時代において、オブザーバビリティはデジタルサービスの信頼性とパフォーマンスを確保する重要な要素となっています。
このモデルはオブザーバビリティを改善するための構造化されたアプローチを提供することで、組織がシステムをより深く理解し制御することを可能にし、より回復力があり、効率的で、高性能なビジネスへの道を開きます。
オブザーバビリティ成熟度モデルのステージ
組織がワークロードを拡大するにつれて、オブザーバビリティ成熟度モデルも成熟することが期待されます。 しかし、オブザーバビリティの成熟度は必ずしもワークロードと共に成長するわけではありません。 目的は、組織の能力が拡大・成長するにつれて、必要な成熟度レベルを達成できるよう支援することです。
-
オブザーバビリティ成熟度モデルの最初のステージでは、通常、組織の現状を把握するためのベースラインを確立します。 これには、既存のモニタリングツールとプロセスの評価、および可視性や機能性のギャップの特定が含まれます。 このステージでは、組織は現在の能力を把握し、エンジニアリングサイクルの初期段階から現実的な改善目標を設定することができます。
-
次のステージでは、組織はより高度なオブザーバビリティ戦略とサービスを採用することで、より洗練されたアプローチに移行します。 これには、プロアクティブなアラート、異なるシステム間の相互作用を把握するための分散トレーシングの実装が含まれ、これにより組織は可視性の向上、認知負荷の軽減、より効率的なトラブルシューティングの利点を享受し始めることができます。
-
オブザーバビリティ成熟度モデルの第 3 段階では、自動修復、人工知能、機械学習技術を活用して、異常検出とルート原因分析を自動化することができます。 これらの高度な機能により、組織は問題を検出するだけでなく、エンドユーザーに影響を与えたり、業務を中断したりする前に是正措置を講じることができます。 オブザーバビリティツールをインシデント管理プラットフォームなどの重要なシステムと統合することで、組織はインシデント対応プロセスを効率化し、問題解決にかかる時間を最小限に抑えることができます。
-
オブザーバビリティ成熟��度モデルの最終段階では、モニタリングとオブザーバビリティツールによって生成された豊富なデータを活用して、継続的な改善を推進します。 これには、高度な分析を使用してワークロードのパフォーマンスのパターンやトレンドを特定し、この情報をエンジニアリングと運用プロセスにフィードバックして、リソースの割り当て、アーキテクチャ、デプロイメント戦略を最適化することが含まれます。
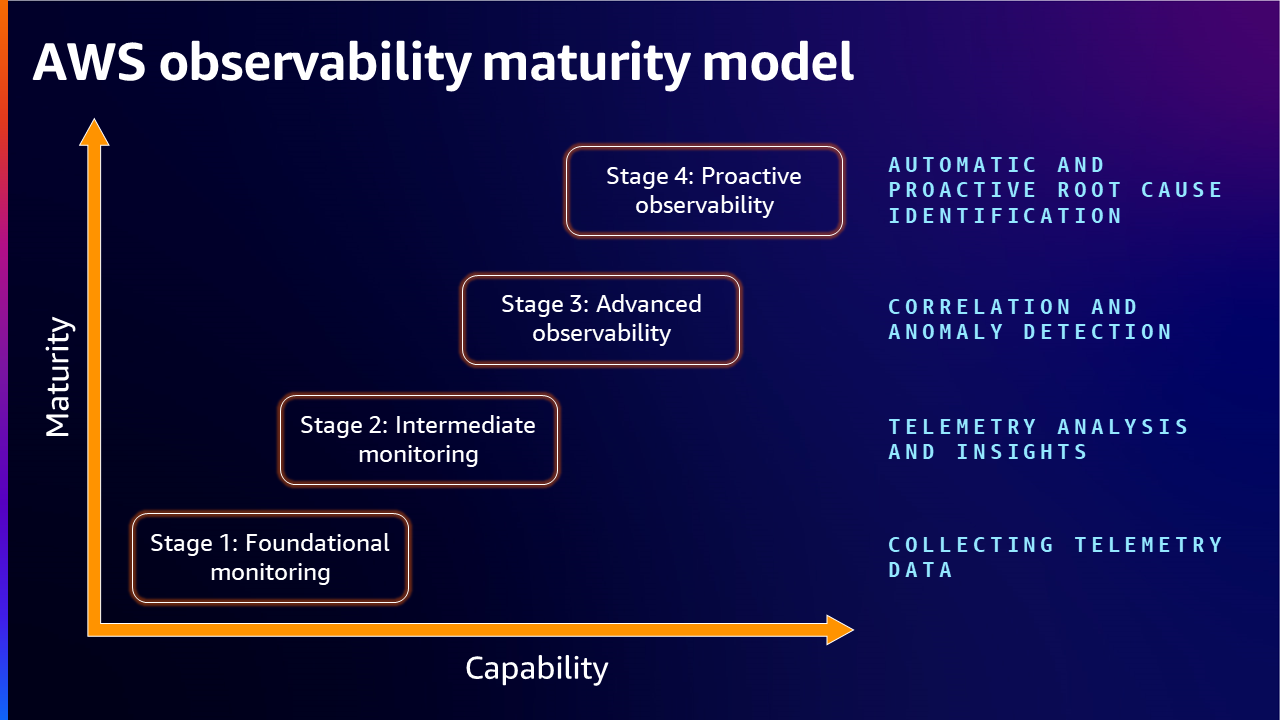
ステージ 1: 基礎的なモニタリング - テレメトリーデータの収集
最低限必要なものとして採用され、サイロ化して運用される基礎的なモニタリングでは、組織内のシステムやワークロード全体を監視するために必要な明確な戦略が定義されていません。 多くの場合、アプリケーション所有者、ネットワークオペレーションセンター (NOC)、CloudOps、DevOps などの異なるチームが、それぞれのモニタリングニーズに応じて異なるツールを使用するため、環境全体のデバッグや最適化の観点からはあまり価値がありません。
通常、このステージのお客様は、ワークロードの監視に異なるソリューションを使用しています。 異なるチームは、他のチームとの連携が限られているか、まったくないため、同じデータを異なる方法で収集することが多くなります。 チームは、自分たちが取得したデータを使用して必要なものを最適化する傾向があります。 また、他のチームから取得したデータが異なる形式である可能性があるため、チーム間でデータを共有することができません。 重要なワークロードを特定するための計画を作成し、オブザーバビリティの統一されたソリューションを目指し、メトリクスとログを定義することが、このレベルでの重要な側面となります。 ワークロードの内部状態とワークロードの健全性を理解するためには、ワークロードが提供する重要なテレメトリーを取得できるように設計することが必要です。
成熟度レベルを向上させるための基盤を構築するために、メトリクス、ログ、トレースの収集を通じてワークロードを計測し、適切なモニタリングとオブザーバビリティツールを使用して意味のある洞察を得ることで、お客様は環境を制御および最適化することができます。 計測とは、ワークロードの動作とパフォーマンスを観察するために使用できる重要なデータを環境から測定、追跡、取得することを指します。 例としては、エラー、成功または失敗したトランザクションなどのアプリケーションメトリクス、CPU やディスクリソースの使用率などのインフラストラクチャメトリクスがあります。
ステージ 2:中級モニタリング - テレメトリー分析とインサイト
このステージでは、オンプレミスやクラウドなど、様々な環境からのシグナル収集に関して、組織の理解が深まっています。 オブザーバビリティの基本構造となるメトリクス、ログ、トレースをワークロードから収集する仕組みを考案し、可視化、アラート戦略を作成し、明確な基準に基づいて問題の優先順位付けを行う能力も備えています。 推測による対応的な対処ではなく、必要なアクションを呼び出すワークフローを持ち、関連チームが収集された情報と過去の知見に基づいて分析とトラブルシューティングを行うことができます。 このレベルの顧客は、従来型であれ最新型であれ、高度にスケーラブルで分散化された、アジャイルでマイクロサービスアーキテクチャの環境に対するオブザーバビリティのプラクティスの達成に向けて取り組んでいます。
ほとんどの場合、モニタリングは上手く機能しているように見えますが、組織は問題のデバッグにより多くの時間を費やす傾向があり、その結果、全体的な平均解決時間 (MTTR) は一定期間にわたって一貫性がなく、意味のある改善も見られません。 また、問題のデバッグに予想以上の認知的な時間と労力がかかるため、インシデント対応が長引きます。 さらに、運用を圧迫するデータ過負荷の状況も発生しがちです。 多くの企業は、次のステップが見えないまま、このステージで足踏みしている状態にあります。 組織を次のレベルに進めるために取れる具体的なアクションは以下の通りです:1) システムのアーキテクチャ設計を定期的にレビューし、影響とダウンタイムを減らしアラートを少なくするためのポリシーとプラクティスを導入する。2) アクション可能な KPI を定義し、アラートの発見事項に価値のあるコンテキストを追加し、重要度/緊急度で分類し、異なるツールやチームに送信することで、エンジニアが問題をより迅速に解決できるようにしてアラート疲れを防ぐ。
これらのアラートを定期的に分析し、頻繁に発生する一般的なアラートに対する修復を自動化します。 アラートの発見事項を関連チームと共有・伝達し、運用とプロセスの改善に関するフィードバックを提供します。
異なるエンティティを相関付け、システムの異なる部分間の依存関係を理解するのに役立つナレッジグラフを段階的に構築する計画を立てます。 これにより、顧客はシステムへの変更の影響�を可視化し、潜在的な問題を予測して軽減することができます。
ステージ 3:高度なオブザーバビリティ - 相関関係と異常検知
このステージでは、組織は多くの時間をトラブルシューティングに費やすことなく、問題の根本原因を明確に理解できるようになります。
問題が発生した場合、アラートは Network Operations Center (NOC)、CloudOps、DevOps チームなどの関連チームに十分なコンテキスト情報を提供します。
モニタリングチームは、アラートを確認し、メトリクス、ログ、トレースなどのシグナルの相関関係を通じて、問題の根本原因をすぐに特定できます。
トレースは、アプリケーションからリクエストに関して収集されたデータで、問題の特定や最適化の機会を見つけるために、ツールを使用して表示、フィルタリング、洞察を得ることができます。
アプリケーションのトレースリクエストは、リクエストとレスポンスに関する詳細情報だけでなく、アプリケーションが下流の AWS リソース、マイクロサービス、データベース、Web API に対して行う呼び出しに関する情報も提供します。
トレースを確認し、トレースがキャプチャされた対応するログイベントを見つけ、インフラストラクチャとアプリケーショ�ンからのメトリクスを確認することで、状況の 360° ビューを得ることができます。
適切なチームは、問題を解決する修正を提供することですぐに是正措置を取ることができます。
このシナリオでは、MTTR は非常に小さく、Service Level Objectives (SLO) は緑色で、エラーバジェットの消費率は許容範囲内です。
通常、このレベルのお客様は、モダンで俊敏性が高く、高度にスケーラブルなマイクロサービス環境のオブザーバビリティに関するプラクティスを達成しています。
多くの組織が、オブザーバビリティ環境においてこのレベルの洗練度と成熟度を達成しています。
このステージでは、組織は複雑なインフラストラクチャをサポートし、高可用性でシステムを運用し、アプリケーションに対してより高い Service Level Availability (SLA) を提供し、信頼性の高いインフラストラクチャを提供することでビジネスイノベーションを達成する能力を既に持っています。
お客様は、通常のパターンに一致しない異常値や外れ値を監視し、ほぼリアルタイムのアラート機能を持つ異常検知も使用しています。
しかし、このような組織のチームは常に可能性の限界を超えようとしています。
チームは、繰り返し発生する問題を理解し、将来発生する可能性のある問題を予測するためのシナリオに対してモデル化できる知識ベースを作成したいと考えています。
これが、お客様が成熟度モデルの次のステージに移行する時期であり、未知の領域への洞察を得ることができます。
そこに到達するためには、新しいツールが必要であり、また、データの保存と活用に関する新しいスキル�と技術を特定する必要があります。
過去に収集したデータを使用して学習したモデルに基づいて、シグナルを自動的に相関付け、根本原因を特定し、解決計画を作成するシステムを構築するために、IT 運用のための人工知能 (AIOps) を活用することができます。
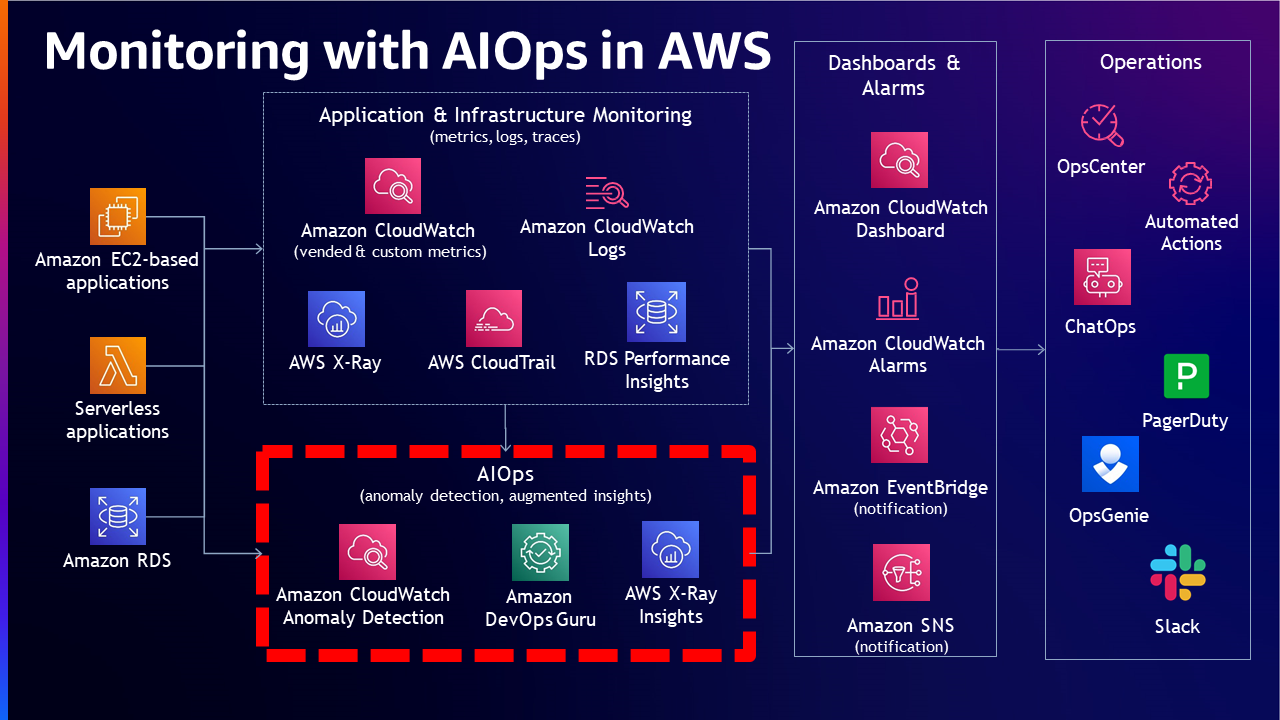
ステージ 4:プロアクティブなオブザーバビリティ - 自動的かつ事前の根本原因特定
ここでは、オブザーバビリティのデータは問題が発生した「後」だけでなく、問題が発生する「前」にリアルタイムでデータを活用します。 十分に学習されたモデルを使用することで、問題を事前に特定し、より簡単に解決することができます。 収集されたシグナルを分析することで、モニタリングシステムは問題に関する洞察を自動的に提供し、解決のためのオプションを提示することができます。
オブザーバビリティソフトウェアベンダーは、この分野での機能を継続的に拡大しており、生成 AI の普及によってさらに加速し��ています。 そのため、このような成熟度レベルを目指す組織は容易に達成することができます。 このステージが成熟し形を整えると、オブザーバビリティサービスが自動的に動的なダッシュボードを作成できるようになります。 ダッシュボードには、当面の問題に関連する情報のみを含めることができます。 これにより、実際には重要でないデータのクエリと可視化にかかる時間とコストを節約できます。 生成 AI (GenAI) と機械学習を実行するためのコンピューティングが日々民主化されることで、将来的にはプロアクティブなモニタリング機能が現在よりも一般的になる可能性があります。
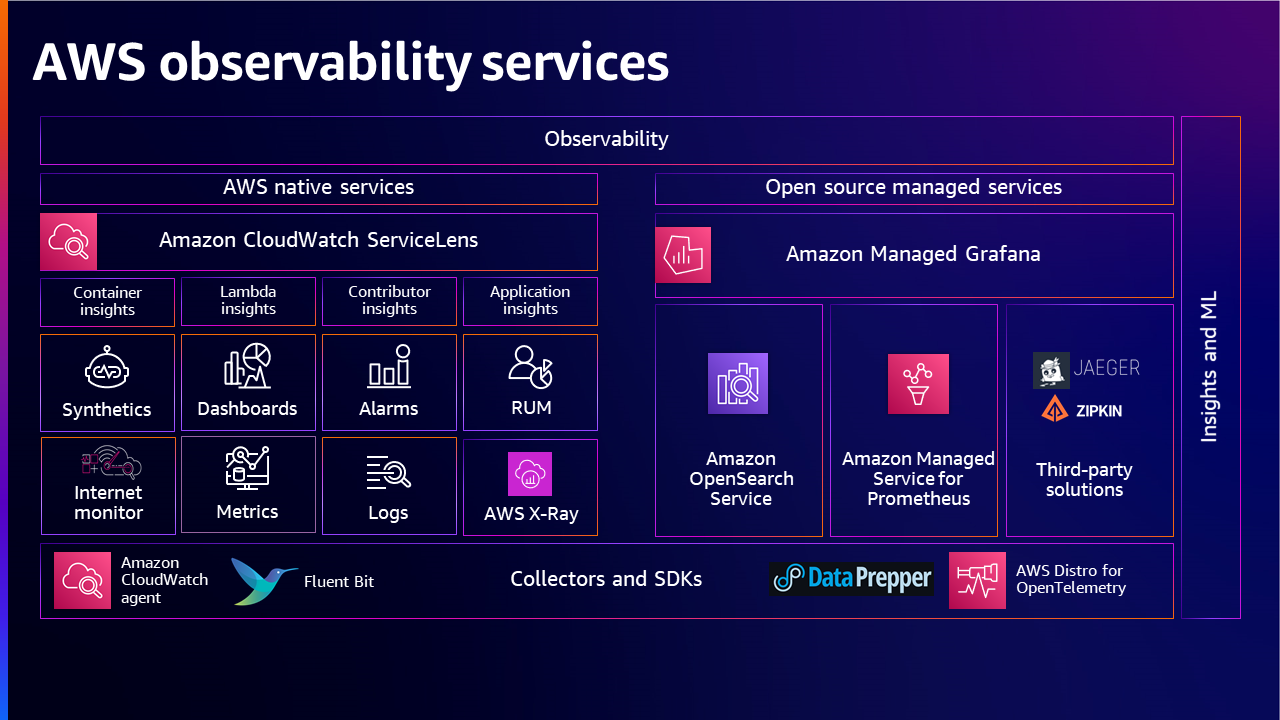
AWS ネイティブおよびオープンソースのソリューションによるデータ収集、データ処理、データの洞察と分析のための包括的なオブザーバビリティポートフォリオの概要を示します。 これにより、お客様は自身のエンドツーエンドのオブザーバビリティニーズに適したソリューションを選択することができます。
オブザーバビリティのための AWS Well-Architected と Cloud Adoption Framework
組織は AWS Well-Architected と Cloud Adoption Framework を活用して、オブザーバビリティ機能を強化し、クラウド環境を効果的に監視およびトラブルシューティングすることができます。
オブザーバビリティのための AWS Well-Architected と Cloud Adoption Framework は、ワークロードの設計、デプロイ、運用のための構造化されたアプローチを提供し、ベストプラクティスの遵守を確実にします。 これにより、可用性、システムパフォーマンス、スケーラビリティ、信頼性が向上します。 また、これらのフレームワークは、組織に標準化された一連のプラクティスと規範的なガイダンスを提供し、組織全体でのコラボレーション、知識の共有、一貫したソリューションの実装を容易にします。
効果的に活用するために、組織は AWS Well-Architected フレームワークの主要なコンポーネントである柱(オペレーショナルエクセレンス、セキュリティ、信頼性、パフォーマンス効率、コスト最適化、持続可能性)を理解する必要があります。 これらの柱は、クラウド環境の設計と運用のための包括的なアプローチを提供します。 一方、Cloud Adoption Framework は、ビジネス、人材、ガバナンス、プラットフォームなどの領域に焦点を当てた、クラウド導入のための構造化されたアプローチを提供します。 これらのコンポーネントをオブザーバビリティの要件と整合させることで、組織は堅牢でスケーラブルなワークロードを構築できます。
オブザーバビリティのための AWS Well-Architected と Cloud Adoption Framework の実装には、いくつかのステップが必要です。 まず、組織は現状を評価し、改善が必要な領域を特定する必要があります。 これは、ワークロードをこれらのフレームワークに照らして評価するオブザーバビリティ成熟度モデル評価を実施することで可能です。 レビュー結果に基づいて、組織はオブザーバビリティの取り組みの優先順位付けと計画を行うことができます。 これには、監視とロギングの要件の定義、適切な AWS サービスの選択、必要なインフラストラクチャとツールの実装が含まれます。 最後に、組織は継続的な有効性を確保するために、オブザーバビリティソリューションを継続的に監視し最適化する必要があります。
また、お客様は AWS のサービスである AWS Well-Architected Tool を使用して、AWS Well-Architected Framework のベストプラクティスを使用してワークロードを文書化し測定することができます。 このツールは、AWS Well-Architected Framework の柱を通じてワークロードを測定するための一貫したプロセスを提供し、お客様が行う決定の文書化を支援し、ワ�ークロードを改善するための推奨事項を提供し、ワークロードをより信頼性が高く、安全で、効率的で、コスト効果の高いものにするためのガイダンスを提供します。
アセスメント
オブザーバビリティ成熟度モデルのアセスメントは、現在のオブザーバビリティの状態を評価し、改善が必要な領域を特定するために使用できます。 各段階のアセスメントでは、異なるチーム間での既存の監視・管理プラクティスを評価し、ギャップと改善領域を特定し、次の段階への全体的な準備状況を判断することが不可欠です。 成熟度アセスメントは、ビジネスプロセスの概要、ワークロードのインベントリとツールの発見、現在の課題の特定、組織の優先事項と目標の理解から始まります。
このアセスメントは、既存のレイアウトのさらなる開発と最適化の基礎となる、対象となるメトリクスと KPI の特定に役立ちます。 オブザーバビリティ成熟度モデルのアセスメントは、ビジネスが現代のシステムの複雑で動的な性質に対処する準備ができていることを確認する上で重要な役割を果たします。 システム障害やパフォーマンスの問題につながる可能性のあるブラインドスポットや弱点の領域を特定するのに役立ちます。
さらに、定期的なアセスメントにより、ビジネスの俊敏性と適応性が維持されます。 進化するテクノロジーと方法論に遅れを取らないようにし、システムが常に最高の効率性と信頼性を維持できるよう�にします。
このアセスメントは、AWS のベストプラクティスに照らしてオブザーバビリティ戦略の状態を確認し、改善の機会を特定し、時間の経過とともに進捗を追跡するのに役立つように設計されています。 以下の質問は、現在のオブザーバビリティ成熟度レベルを評価するのに役立ちます。 無料で「AWS オブザーバビリティ成熟度モデルアセスメント」ツールを使用したアセスメントを実施するには、AWS アカウントチームにお問い合わせください。
ログ
- ログをどのように収集していますか?
- ログをどのように使用していますか?
- ログにどのようにアクセスしていますか?
- セキュリティと規制コンプライアンスのためのログ保持ポリシーはどのようなものですか?
- 現在、ML/AI 機能を使用していますか?
メトリクス
- どのような種類のメトリクスを収集していますか?
- メトリクスをどのように使用していますか?
- メトリクスにどのようにアクセスしていますか?
トレース
- トレースをどのように収集していますか?
- トレースをどのように使用していますか?
ダッシュボードとアラート
- アラームをどのように使用していますか?
- ダッシュボードをどのように使用していますか?
組織
- エンタープライズオブザーバビリティ戦略はありますか?
- SLO をどのように使用し��ていますか?
オブザーバビリティ戦略の構築
組織がオブザーバビリティの段階を特定したら、現在のプロセスとツールを最適化するための戦略を構築し、成熟度向上に向けて取り組み始める必要があります。 組織は顧客に優れた体験を提供することを望んでいるため、まずそれらの顧客要件から始めて、そこから Working Backwards を行います。 そして、これらの要件を深く理解しているステークホルダーと協力します。
オブザーバビリティ戦略を目指すにあたり、組織はまず全体的なビジネス目標に沿ったオブザーバビリティの目標を定義する必要があります。 この目標は、戦略を通じて組織が達成しようとすることを明確に示し、オブザーバビリティ計画の構築と実装のためのロードマップを提供する必要があります。
次に、組織はシステムパフォーマンスの洞察を提供する重要なメトリクス (KPI) を特定する必要があります。 これらは、レイテンシーやエラー率から、リソース使用率やトランザクション量まで多岐にわたります。 メトリクスの選択は、ビジネスの性質と特定のニーズに大きく依存することに注意することが重要です。
重要なメトリクスを特定したら、組織はデータ収集に必要なツールとテクノロジーを決定できます。 ツールの選択は、組織の目標との整合性、既存システムとの統合の容易さ、コストの最適化、スケーラビリティの実現、顧客ニーズの充足、全体的な顧客体験の向上に基づいて行う必要があります。
最後に、組織はオブザーバビリティを重視する文化も促進する必要があります。 これには、チームメンバーにオブザーバビリティの重要性についてトレーニングを行い、システムパフォーマンスを積極的に監視するよう促し、継続的な学習と改善の文化を育むことが含まれます。 この戦略は、最高の顧客体験を実現するための収集、アクション、改善の継続的なプロセスの好循環を生み出します。
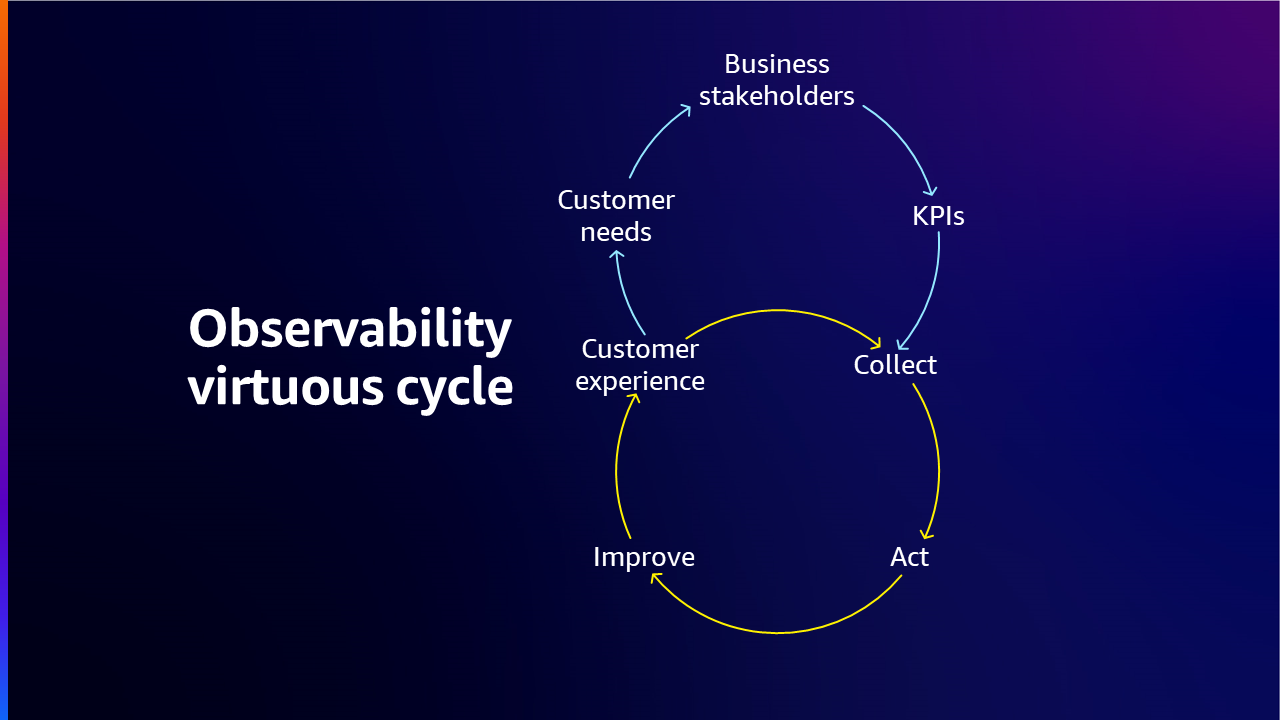
まとめると、オブザーバビリティ戦略を構築するには、以下の 3 つの主要な側面を考慮する必要があります:1) 何を収集する必要があるか 2) 観察が必要なすべてのシステムとワークロードは何か 3) 問題が発生した場合にどのように対応し、それらを修正するためにどのようなメカニズムを用意すべきか。
まとめ
オブザーバビリティ成熟度モデルは、組織が現状を評価し、ワークロードとインフラストラクチャの動作を理解、分析、対応する能力を向上させる方法を探るためのロードマップとして機能します。
現在の能力を評価し、高度な監視手法を採用し、データ駆動型のインサイトを活用するための体系的なアプローチに従うことで、企業はより高度なオ��ブザーバビリティを実現し、ワークロードとインフラストラクチャについてより適切な意思決定を行うことができます。
このモデルは、組織が異なる成熟度レベルを進み、最終的にプロアクティブなオブザーバビリティのメリットを十分に活用できる状態に到達するために必要な主要な機能と実践方法を概説しています。
参考リソース
- 効果的なオブザーバビリティ戦略の構築 - AWS re:Invent 2023
- AWS オブザーバビリティのベストプラクティス
- オブザーバビリティとは何か、なぜ重要なのか?
- オブザーバビリティ戦略の開発方法
- AWS における深いアプリケーションオブザーバビリティのガイダンス
- Discovery が AWS オブザーバビリティで運用効率を向上させた方法 - AWS re:Invent 2022
- オブザーバビリティ戦略の開発 - AWS re:Invent 2022
- AWS でクラウドネイティブなオブザーバビリティを探る - AWS Virtual Workshop
- AWS オブザーバビリティソリューションで可用性を向上 - AWS re:Invent 2020
- Amazon におけるオブザーバビリティのベストプラクティス - AWS re:Invent 2022
- オブザーバビリティ:モダンアプリケーションのベストプラクティス - AWS re:Invent 2022
- オープンソースによるオブザーバビリティ - AWS re:Invent 2022
- AIOps でオブザーバビリティ戦略を強化
- Let's Architect! 大規模な本番システムのモニタリング
- AWS による完全なスタックのオブザーバビリティとアプリケーションモニタリング - AWS Summit SF 2022