Amazon RDS と Aurora データベースのモニタリング
モニタリングは、Amazon RDS と Aurora データベースクラスターの信頼性、可用性、パフォーマンスを維持するための重要な要素です。 AWS は、Amazon RDS と Aurora データベースリソースの健全性を監視し、問題が重大化する前に検出し、一貫したユーザーエクスペリエンスのためにパフォーマンスを最適化するための複数のツールを提供しています。 このガイドでは、データベースが円滑に稼働することを確実にするためのオブザーバビリティのベストプラクティスを提供します。
パフォーマンスのガイドライン
ベストプラクティスとして、まずワークロードのベースラインパフォーマンスを確立することから始めます。 DB インスタンスをセットアップし、一般的なワークロードで実行する際、すべてのパフォーマンスメトリクスの平均値、最大値、最小値を収集します。 これを様々な間隔(例:1 時間、24 時間、1 週間、2 週間)で行います。 これにより、何が通常の状態なのかを把握することができます。 ピーク時と非ピーク時の運用時間の比較を得るのに役立ちます。 この情報を使用して、パフォーマンスが標準レベルを下回っているタイミングを特定できます。
モニ��タリングのオプション
Amazon CloudWatch メトリクス
Amazon CloudWatch は、RDS と Aurora データベースを監視および管理するための重要なツールです。 データベースのパフォーマンスに関する貴重な洞察を提供し、問題を素早く特定して解決するのに役立ちます。 Amazon RDS と Aurora データベースは、アクティブなデータベースインスタンスごとに 1 分間隔でメトリクスを CloudWatch に送信します。 監視はデフォルトで有効になっており、メトリクスは 15 日間利用可能です。 RDS と Aurora は、インスタンスレベルのメトリクスを AWS/RDS 名前空間の Amazon CloudWatch に公開します。
CloudWatch メトリクスを使用することで、データベースのパフォーマンスの傾向やパターンを特定し、この情報を使用して設定を最適化し、アプリケーションのパフォーマンスを改善できます。 監視すべき主要なメトリクスは以下の通りです:
- CPU 使用率 - 使用されているコンピュータ処理能力の割合。
- DB 接続数 - DB インスタンスに接続されているクライアントセッションの数。インスタンスのパフォーマンスとレスポンスタイムの低下と共にユーザー接続数が多いことが確認された場合は、データベース接続数を制限することを検討してください。DB インスタンスに最適なユーザー接続数は、インスタンスクラスと実行される操作の複雑さによって異なります。データベース接続数を決定するには、DB インスタンスをパラメータグループに関連付けます。
- 解放可能なメモリ - DB インスタンスで利用可能な RAM の量(メガバイト単位)。モニタリングタブのメトリクスでは、CPU、メモリ、ストレージメトリクスの赤線が 75% でマークされています。インスタンスのメモリ消費がこのラインを頻繁に超える場合は、ワークロードを確認するかインスタンスをアップグレードする必要があることを示しています。
- ネットワークスループット - DB インスタンスとの間のネットワークトラフィックの速度(バイト/秒)。
- 読み取り/書き込みレイテンシー - 読み取りまたは書き込み操作の平均時間(ミリ秒単位)。
- 読み取り/書き込み IOPS - 1 秒あたりの平均ディスク読み取りまたは書き込み操作数。
- 空きストレージスペース - DB インスタンスで現在使用されていないディスク容量(メガバイト単位)。使用済みスペースが総ディスク容量の 85% 以上で一貫している場合は、ディスク容量の消費を調査してください。インス��タンスからデータを削除するか、別のシステムにデータをアーカイブしてスペースを解放できるかどうかを確認してください。
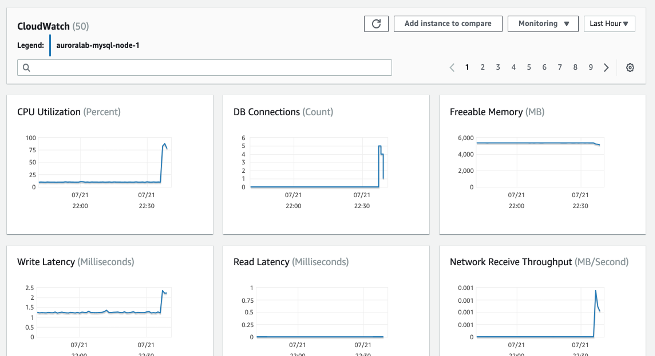
パフォーマンス関連の問題のトラブルシューティングでは、最初のステップとして、最も使用頻度が高く、コストのかかるクエリをチューニングします。 システムリソースへの負荷を軽減できるかどうかを確認するために、これらのクエリをチューニングしてください。 詳細については、クエリのチューニングを参照してください。
クエリがチューニングされても問題が解決しない場合は、データベースインスタンスクラスのアップグレードを検討してください。 より多くのリソース(CPU、RAM、ディスク容量、ネットワーク帯域幅、I/O 容量)を持つインスタンスにアップグレードできます。
その後、これらのメトリクスが重要なしきい値に達したときにアラートを設定し、問題を可能な限り迅速に解決するための対策を講じることができます。
CloudWatch メトリクスの詳細については、Amazon RDS の Amazon CloudWatch メトリクスとCloudWatch コンソールと AWS CLI での DB インスタンスメト�リクスの表示を参照してください。
CloudWatch Logs Insights
CloudWatch Logs Insights を使用すると、Amazon CloudWatch Logs のログデータをインタラクティブに検索および分析できます。 クエリを実行することで、運用上の問題により効率的かつ効果的に対応できます。 問題が発生した場合、CloudWatch Logs Insights を使用して潜在的な原因を特定し、デプロイされた修正を検証できます。
RDS または Aurora データベースクラスターからのログを CloudWatch に公開する方法については、RDS または Aurora for MySQL インスタンスのログを CloudWatch に公開する を参照してください。
CloudWatch を使用した RDS または Aurora ログのモニタリングの詳細については、Amazon RDS ログファイルのモニタリング を参照してください。
CloudWatch アラーム
データベースクラスターのパフォーマンス低下を特定するために、主�要なパフォーマンスメトリクスを定期的に監視し、アラートを設定する必要があります。 Amazon CloudWatch アラーム を使用すると、指定した期間にわたって単一のメトリクスを監視できます。 メトリクスが指定したしきい値を超えると、Amazon SNS トピックまたは AWS Auto Scaling ポリシーに通知が送信されます。 CloudWatch アラームは、特定の状態にあるだけでは、アクションを実行しません。 状態が変更され、指定された期間数にわたって維持されている必要があります。 アラームは、アラームの状態が変更された場合にのみアクションを実行します。 アラーム状態にあるだけでは不十分です。
CloudWatch アラームを設定するには:
- AWS マネジメントコンソールに移動し、https://console.aws.amazon.com/rds/ で Amazon RDS コンソールを開きます。
- ナビゲーションペインで「データベース」を選択し、DB インスタンスを選択します。
- 「ログとイベント」を選択します。
CloudWatch アラームセクションで、「アラームの作成」を選択します。
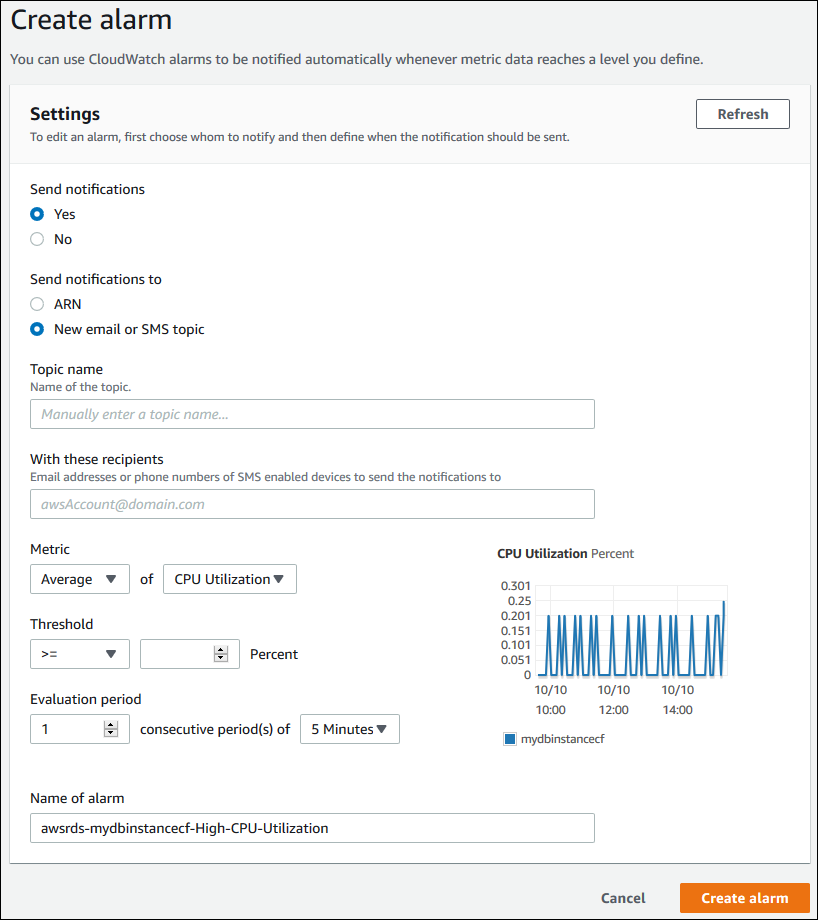
- 「通知の送信」で「はい」を選択し、「通知の送信先」で「新しいメールまたは SMS トピック」を選択します。
- 「トピック名」に通知の名前を入力し、「受信者」�にメールアドレスと電話番号をカンマ区切りで入力します。
- 「メトリクス」で、設定するアラームの統計とメトリクスを選択します。
- 「しきい値」で、メトリクスがしきい値より大きいか、小さいか、等しいかを指定し、しきい値を設定します。
- 「評価期間」でアラームの評価期間を選択します。「連続する期間」で、アラームをトリガーするためにしきい値に達している必要がある期間を選択します。
- 「アラーム名」にアラームの名前を入力します。
- 「アラームの作成」を選択します。
アラームが CloudWatch アラームセクションに表示されます。
マルチ AZ DB クラスターのレプリカラグに対する Amazon CloudWatch アラームを作成する例をご覧ください。
データベース監査ログ
データベース監査ログは、RDS と Aurora データベースで実行されたすべてのアクションの詳細な記録を提供し、不正アクセス、データ変更、その他の潜在的に有害なアクティビティを監視することができます。 以下は、データベース監査ログを使用する際のベストプラクティスです:
- すべての RDS と Aurora インスタンスでデータベース監査ログを有効にし、関連するすべてのデータを取得するよ��うに設定します。
- Amazon CloudWatch Logs や Amazon Kinesis Data Streams などの一元化されたログ管理ソリューションを使用して、データベース監査ログを収集・分析します。
- データベース監査ログを定期的に監視して不審なアクティビティを確認し、問題を迅速に調査・解決するための対策を講じます。
データベース監査ログの設定方法の詳細については、Amazon RDS と Aurora のデータベースアクティビティを取得するための監査ログの設定 を参照してください。
データベースのスロークエリとエラーログ
スロークエリログは、データベース内の実行速度が遅いクエリを見つけるのに役立ちます。これにより、遅延の原因を調査し、必要に応じてクエリをチューニングすることができます。エラーログは、クエリのエラーを見つけるのに役立ち、それらのエラーによるアプリケーションの変更を特定するのに役立ちます。
Amazon CloudWatch Logs Insights (CloudWatch Logs のログデータをインタラクティブに検索および分析できる機能) を使用して CloudWatch ダッシュボードを作成することで、スロークエリログとエラーログを��監視できます。
Amazon RDS のエラーログ、スロークエリログ、一般ログを有効化して監視するには、RDS MySQL のスロークエリログと一般ログの管理 を参照してください。Aurora PostgreSQL のスロークエリログを有効にするには、PostgreSQL のスロークエリログの有効化 を参照してください。
Performance Insights とオペレーティングシステムのメトリクス
拡張モニタリング
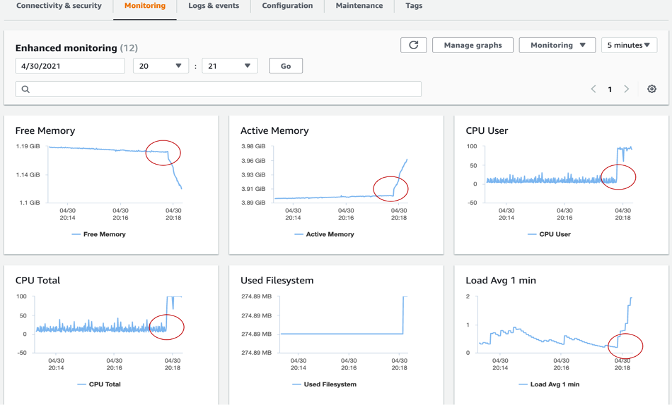
拡張モニタリング を使用すると、DB インスタンスが実行されているオペレーティングシステム (OS) のきめ細かなメトリクスをリアルタイムで取得できます。
RDS は、拡張モニタリングのメトリクスを Amazon CloudWatch Logs アカウントに配信します。デフォルトでは、これらのメトリクスは 30 日間保存され、Amazon CloudWatch の RDSOSMetrics ロググループに格納されます。1 秒から 60 秒の間で粒度を選択できます。CloudWatch Logs からカスタムメトリクスフィルターを作成し、CloudWatch ダッシュボードにグラフを表示できます。
拡張モニタリングには、OS レベルのプロセスリストも含まれています。現在、拡張モニタリングは以下のデータベースエンジンで利用可能です:
- MariaDB
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
CloudWatch と拡張モニタリングの違い CloudWatch は、DB インスタンスのハイパーバイザーから CPU 使用率のメトリクスを収集します。一方、拡張モニタリングは DB インスタンス上のエージェントからメトリクスを収集します。ハイパーバイザーは仮想マシン (VM) を作成して実行します。ハイパーバイザーを使用することで、インスタンスはメモリと CPU を仮想的に共有して複数のゲスト VM をサポートできます。ハイパーバイザーレイヤーが少量の作業を実行するため、CloudWatch と拡張モニタリングの測定値に違いが生じる場合があります。DB インスタンスがより小さなインスタンスクラスを使用している場合、この違いはより大きくなる可能性があります。このシナリオでは、1 つの物理インスタンス上でハイパーバイザーレイヤーがより多くの仮想マシン (VM) を��管理している可能性があります。
拡張モニタリングで利用可能なすべてのメトリクスについては、拡張モニタリングの OS メトリクス を参照してください。
Performance Insights
Amazon RDS Performance Insights は、データベースのパフォーマンスチューニングとモニタリングの機能で、データベースの負荷を素早く評価し、いつどこで対策を講じるべきかを判断するのに役立ちます。 Performance Insights ダッシュボードでは、DB クラスターの負荷を可視化し、待機状態、SQL ステートメント、ホスト、またはユーザーで負荷をフィルタリングできます。 症状を追いかけるのではなく、根本原因を特定することができます。 Performance Insights は、アプリケーションのパフォーマンスに影響を与えない軽量なデータ収集方法を使用し、どの SQL ステートメントが負荷を引き起こしているのか、そしてその理由を簡単に確認することができます。
Performance Insights は 7 日間の無料パフォーマンス履歴保持を提供し、有料で最大 2 年まで延長できます。 RDS �マネジメントコンソールまたは AWS CLI から Performance Insights を有効にできます。 Performance Insights は公開 API も提供しており、お客様やサードパーティが Performance Insights を独自のカスタムツールと統合できるようになっています。
現在、RDS Performance Insights は、Aurora (PostgreSQL および MySQL 互換エディション)、Amazon RDS for PostgreSQL、MySQL、MariaDB、SQL Server、Oracle でのみ利用可能です。
DBLoad は、データベースのアクティブセッションの平均数を表す重要なメトリクスです。 Performance Insights では、このデータは db.load.avg メトリクスとして照会されます。
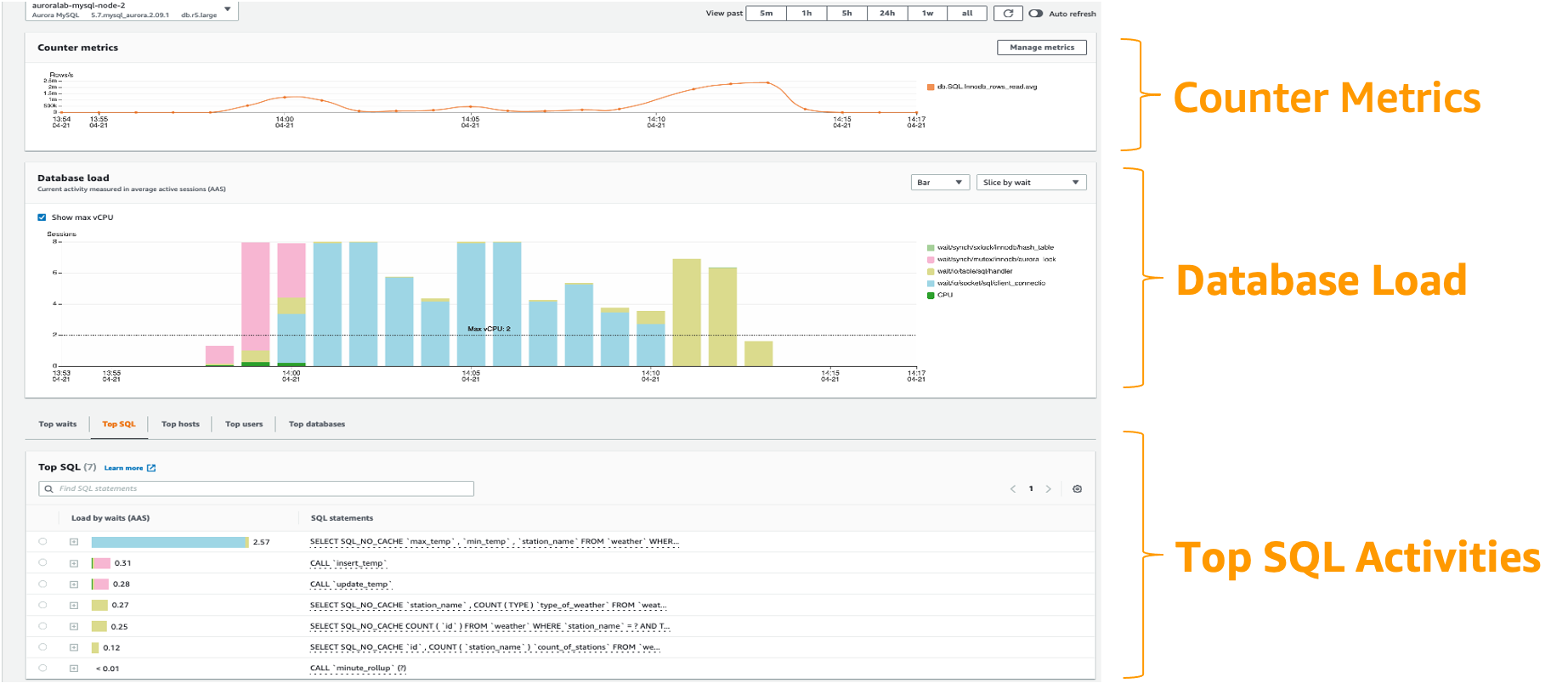
Aurora での Performance Insights の使用に関する詳細については、Amazon Aurora での Performance Insights を使用した DB 負荷のモニタリング を参照してください。
オープンソースのオブザーバビリティツール
Amazon Managed Grafana
Amazon Managed Grafana は、RDS および Aurora データベースのデータを簡単に可視化および分析できるフルマネージドサービスです。
Amazon CloudWatch の AWS/RDS 名前空間 には、Amazon RDS および Amazon Aurora で実行されているデータベースエンティティに適用される主要なメトリクスが含まれています。Amazon Managed Grafana で RDS/Aurora データベースの健全性と潜在的なパフォーマンスの問題を可視化および追跡するために、CloudWatch データソースを活用できます。
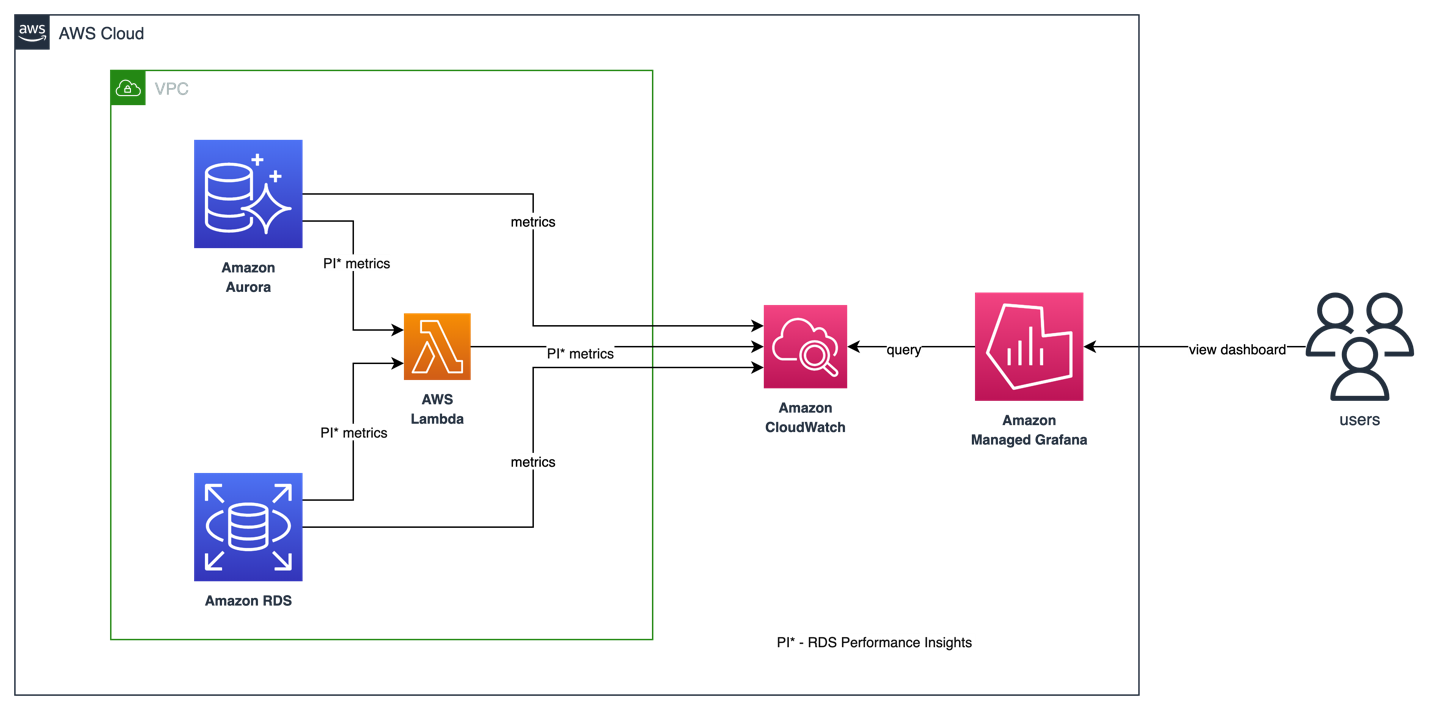
現在のところ、CloudWatch で利用できるのは基本的な Performance Insights メトリクスのみであり、データベースのパフォーマンスを分析し、ボトルネック��を特定するには十分ではありません。Amazon Managed Grafana で RDS Performance Insights メトリクスを可視化し、単一のビューで可視性を確保するために、カスタム Lambda 関数を使用して RDS Performance Insights のすべてのメトリクスを収集し、カスタム CloudWatch メトリクス名前空間に公開できます。これらのメトリクスが Amazon CloudWatch で利用可能になると、Amazon Managed Grafana で可視化できます。
RDS Performance Insights メトリクスを収集するカスタム Lambda 関数をデプロイするには、以下の GitHub リポジトリをクローンし、install.sh スクリプトを実行します。
$ git clone https://github.com/aws-observability/observability-best-practices.git
$ cd sandbox/monitor-aurora-with-grafana
$ chmod +x install.sh
$ ./install.sh
上記のスクリプトは AWS CloudFormation を使用して、カスタム Lambda 関数と IAM ロールをデプロイします。Lambda 関数は 10 分ごとに自動的にトリガーされ、RDS Performance Insights API を呼び出して、カスタムメトリクスを Amazon CloudWatch の /AuroraMonitoringGrafana/PerformanceInsights カスタム名前空間に公開します。
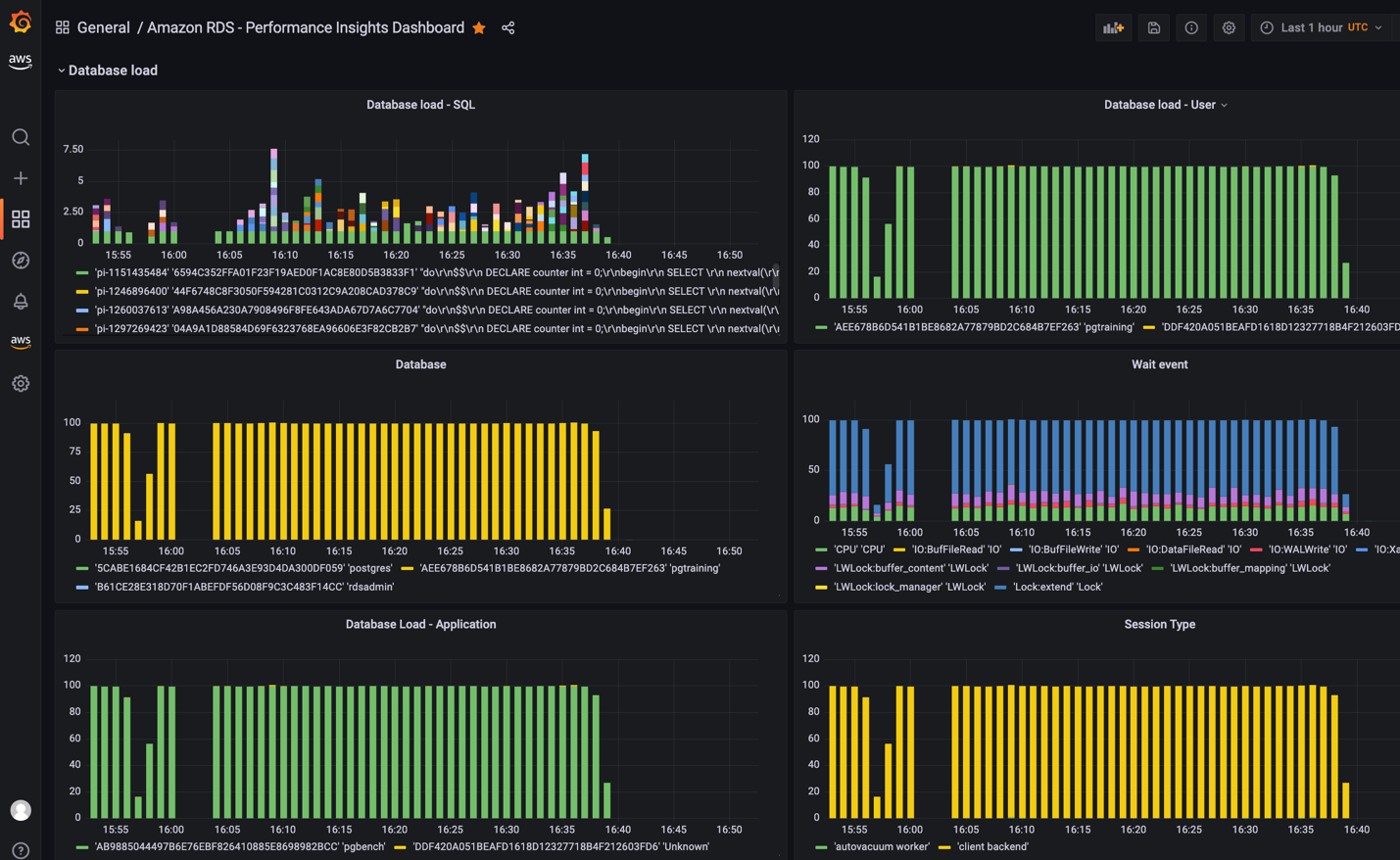
カスタム Lambda 関数のデプロイと Grafana ダッシュボードに関する詳細な手順については、Performance Insights in Amazon Managed Grafana を参照してください。
データベースの意図しない変更を素早く特定し、アラートで通知することで、障害を最小限に抑えるためのアクションを取ることができます。Amazon Managed Grafana は、SNS、Slack、PagerDuty などの複数の通知チャネルをサポートしており、アラート通知を送信できます。Amazon Managed Grafana でアラートを設定する方法の詳細については、Grafana Alerting を参照してください。
AIOps - 機械学習ベースのパフォーマンスボトルネック検出
Amazon DevOps Guru for RDS
Amazon DevOps Guru for RDS を使用すると、データベースのパフォーマンスのボトルネックや運用上の問題を監視できます。 Performance Insights のメトリクスを使用し、機械学習 (ML) を用いてパフォーマンスの問題に関するデータベース固有の分析を行い、是正措置を推奨します。 DevOps Guru for RDS は、ホストリソースの過剰使用、データベースのボトルネック、SQL クエリの異常動作など、さまざまなパフォーマンス関連のデータベースの問題を特定し分析できます。 問題や異常な動作が検出されると、DevOps Guru for RDS は DevOps Guru コンソールに結果を表示し、Amazon EventBridge または Amazon Simple Notification Service (SNS) を使用して通知を送信します。これにより、DevOps チームや SRE チームは、顧客に影響を与える障害が発生する前に、パフォーマンスや運用上の問題にリアルタイムで対応できます。
DevOps Guru for RDS は、データベースのメトリクスのベースラインを確立します。 ベースライン化には、一定期間にわたってデータベースのパフォーマンスメト��リクスを分析し、正常な動作を確立することが含まれます。 その後、Amazon DevOps Guru for RDS は ML を使用して、確立されたベースラインに対する異常を検出します。 ワークロードパターンが変更された場合、DevOps Guru for RDS は新しい正常値に対して異常を検出するために使用する新しいベースラインを確立します。
新しいデータベースインスタンスの場合、Amazon DevOps Guru for RDS は、データベースの使用パターンを分析し、正常な動作とみなされるものを確立する必要があるため、初期ベースラインの確立に最大 2 日かかります。
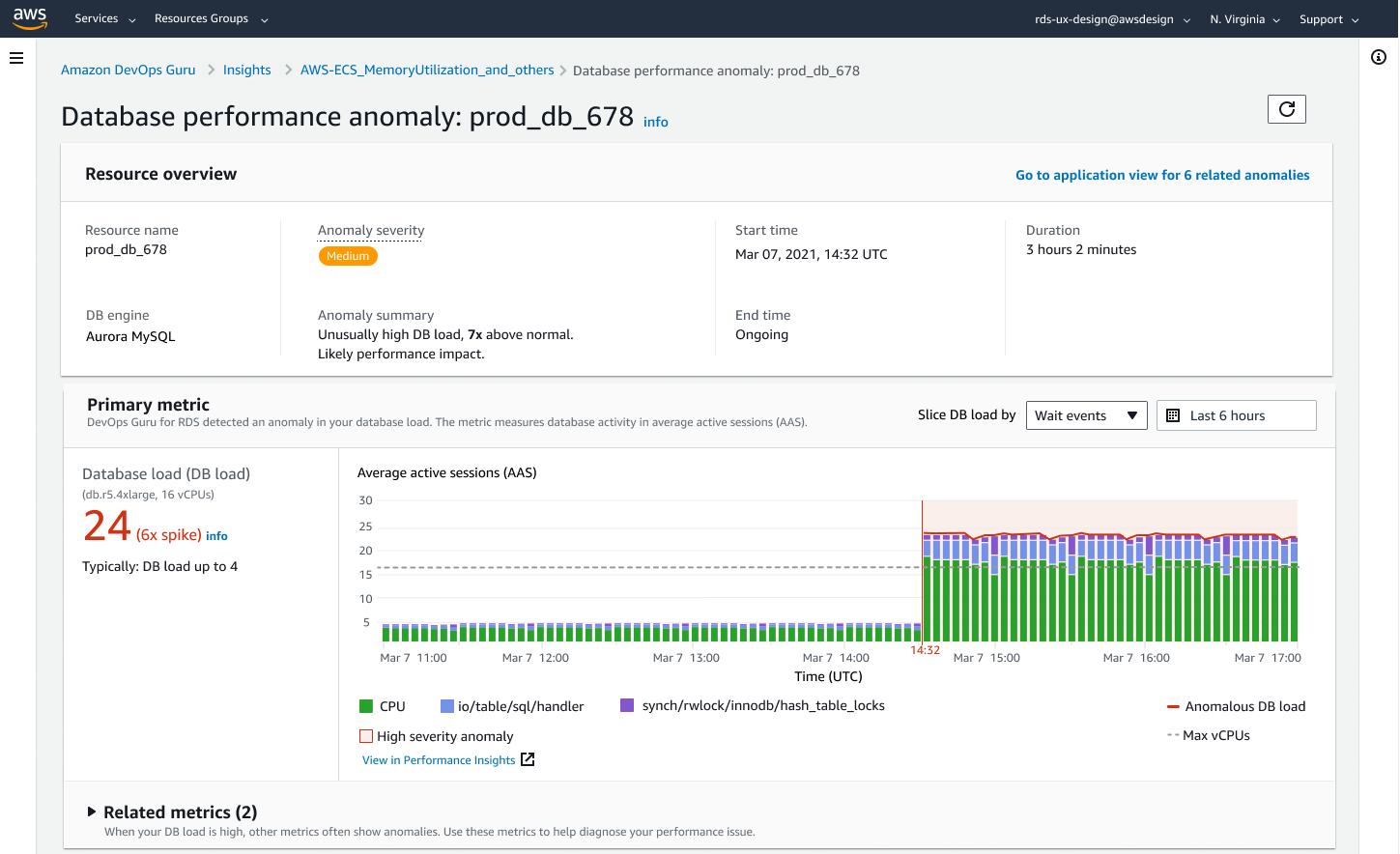
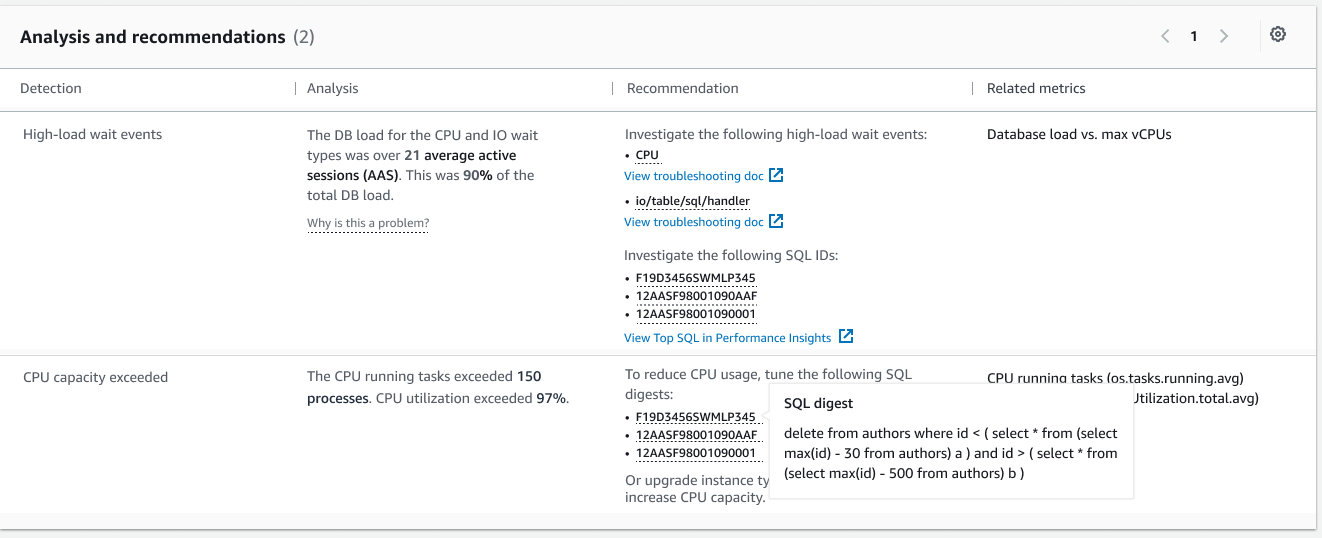
開始方法の詳細については、Amazon DevOps Guru for RDS to Detect, Diagnose, and Resolve Amazon Aurora-Related Issues using ML をご覧ください。
監査とガバナンス
AWS CloudTrail ログ
AWS CloudTrail は、ユーザー、ロール、または AWS サービスによって RDS で実行されたアクションの記録を提供します。 CloudTrail は、コンソールからの呼び出しや RDS API オペレーションへのコード呼び出しを含む、RDS のすべての API 呼び出しをイベントとしてキャプチャします。 CloudTrail によって収集された情報を使用して、RDS に対して行われたリクエスト、リクエストの送信元 IP アドレス、リクエストの実行者、実行時期、およびその他の詳細を確認できます。 詳細については、AWS CloudTrail での Amazon RDS API コールのモニタリングを参照してください。
詳細については、AWS CloudTrail での Amazon RDS API コールのモニタリングを参照してください。
詳細情報の参考資料
ブログ - Amazon Managed Grafana を使用した RDS と Aurora データベースのモニタリング
動画 - Amazon Managed Grafana を使用した RDS と Aurora データベースのモニタリング
ブログ - Amazon CloudWatch を使用した RDS と Aurora データベースのモニタリング
ブログ - Amazon CloudWatch Logs、AWS Lambda、Amazon SNS を使用した Amazon RDS のプロアクティブなデータベースモニタリングの構築