Kubecost の使用
Kubecost は、Kubernetes 環境におけるコストとリソース効率の可視化を提供します。 概要として、Amazon EKS のコストモニタリングは、オープンソースのモニタリングシステムおよび時系列データベースである Prometheus を含む Kubecost によってデプロイされます。 Kubecost は Prometheus からメトリクスを読み取り、コスト配分の計算を実行し、その結果を Prometheus に書き戻します。 最後に、Kubecost フロントエンドが Prometheus からメトリクスを読み取り、Kubecost ユーザーインターフェース (UI) に表示します。 アーキテクチャは以下の図のとおりです:
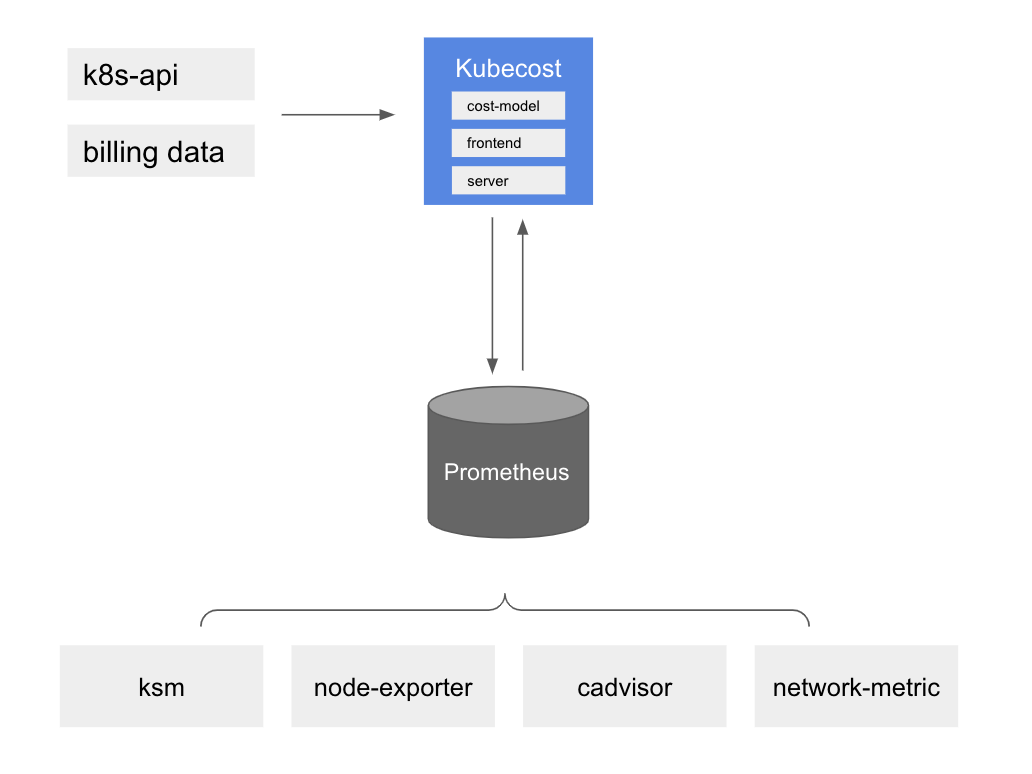
Kubecost を使用する理由
お客様がアプリケーションをモダナイズし、Amazon EKS を使用してワークロードをデプロイする際、アプリケーションの実行に必要なコンピューティングリソースを統合することで効率性を獲得できます。 しかし、この利用効率の向上は、アプリケーションコストの測定が難しくなるというトレードオフを伴います。 現在、テナントごとのコスト配分には以下のいずれかの方法を使用できます:
- ハードマルチテナンシー — 専用の AWS アカウントで個別の EKS クラスターを実行します。
- ソフトマルチテナンシー — 共有 EKS クラスター内で複数のノードグループを実行します。
- 消費ベースの課金 — 共有 EKS クラスター内のリソース消費量に基づいてコストを計算します。
ハードマルチテナンシーでは、ワークロードは個別の EKS クラスターにデプロイされ、各テナントの支出を判断するためのレポートを実行することなく、クラスターとその依存関係のコストを特定できます。 ソフトマルチテナンシーでは、Node Selectors や Node Affinity などの Kubernetes の機能を使用して、Kubernetes Scheduler にテナントのワークロードを専用のノードグループで実行するよう指示できます。 ノードグループ内の EC2 インスタンスに識別子(製品名やチーム名など)でタグを付け、タグ を使用してコストを配分できます。 上記 2 つのアプローチの欠点は、未使用のキャパシティが発生する可能性があり、密にパックされたクラスターを実行した場合のコスト削減効果を十分に活用できない可能性があることです。 また、Elastic Load Balancing やネットワーク転送料金などの共有リソースのコストを配分する方法も必要です。
マルチテナント Kubernetes クラスターでコストを追跡する最も効率的な方法は、ワークロードが消費したリソースの量に基づいて発生したコストを配分することです。 このパターンでは、異なるワークロードがノードを共有できるため、ノード上の Pod 密度を高めることができ、EC2 インスタンスの使用率を最大化できます。 しかし、ワークロードや名前空間ごとのコストを計算することは困難な作業です。 ワークロードのコスト責任を理解するには、一定期間に消費または予約されたすべてのリソースを集計し、リソースのコストと使用期間に基づいて料金を評価する必要があります。 これが Kubecost が取り組んでいる課題です。
Kubecost のハンズオン体験をするには、One Observability Workshop をご覧ください。
推奨事項
コスト配分
Kubecost のコスト配分ダッシュボードでは、名前空間、k8s ラベル、サービスなど、すべてのネイティブな Kubernetes の概念に対する配分された支出と最適化の機会を素早く確認できます。 また、チーム、製品/プロジェクト、部門、環境などの組織の概念にコストを配分することもできます。 日付範囲やフィルターを変更して、特定のワークロードに関するインサイトを導き出し、レポートを保存することができます。 Kubernetes のコストを最適化するには、効率性とクラスターのアイドルコストに注意を払う必要があります。

効率性
Pod のリソース効率は、一定の時�間枠におけるリソースの使用量とリソースのリクエスト量の比率として定義されます。
これはコストで重み付けされ、以下のように表現できます:
(((CPU Usage / CPU Requested) * CPU Cost) + ((RAM Usage / RAM Requested) * RAM Cost)) / (RAM Cost + CPU Cost)
ここで、CPU Usage = 時間枠における rate(container_cpu_usage_seconds_total)、RAM Usage = 時間枠における avg(container_memory_working_set_bytes) です。
AWS では明示的な RAM、CPU、GPU の価格は提供されていないため、Kubecost モデルは提供された CPU、GPU、RAM の基本価格の比率を使用します。
これらのパラメータのデフォルト値はクラウドプロバイダーの限界リソースレートに基づいていますが、Kubecost 内でカスタマイズすることができます。
これらの基本リソース(RAM/CPU/GPU)の価格は、プロバイダーの課金レートに基づいて、各コンポーネントの合計がプロビジョニングされたノードの総価格と等しくなるように正規化されます。
最大効率を目指し、ワークロードを微調整してゴールを達成することは、各サービスチームの責任です。
アイドルコスト
�クラスターのアイドルコストは、割り当てられたリソースのコストと、それらが実行されているハードウェアのコストの差として定義されます。 割り当ては、使用量とリクエストの最大値として定義されます。 これは以下のように表現することもできます:
idle_cost = sum(node_cost) - (cpu_allocation_cost + ram_allocation_cost + gpu_allocation_cost)
ここで、allocation = max(request, usage) となります。
つまり、アイドルコストは、既存のワークロードを中断することなく Kubernetes スケジューラが Pod をスケジュールできるスペースのコストと考えることができますが、現在は使用されていません。 設定方法に応じて、ワークロードやクラスター、ノードごとに分配することができます。
ネットワークコスト
Kubecost は、ワークロードが生成するネットワーク転送コストを、ベストエフォートで割り当てます。ネットワークコストを正確に判断するには、AWS Cloud Integration と Network costs daemonset を組み合わせて使用します。
クラスターの潜在能力を最大限に活用するためには、効率性スコアとアイドルコストを考慮してワークロードを微調整する必要があります。これは、次のトピックであるクラスターのライトサイジングにつながります。
ワークロードのライトサイジング
Kubecost は、Kubernetes ネイティブのメトリクスに基づいてワークロードのライトサイジングに関する推奨事項を提供します。 Kubecost UI のセービングパネルは、その確認を始めるのに最適な場所です。
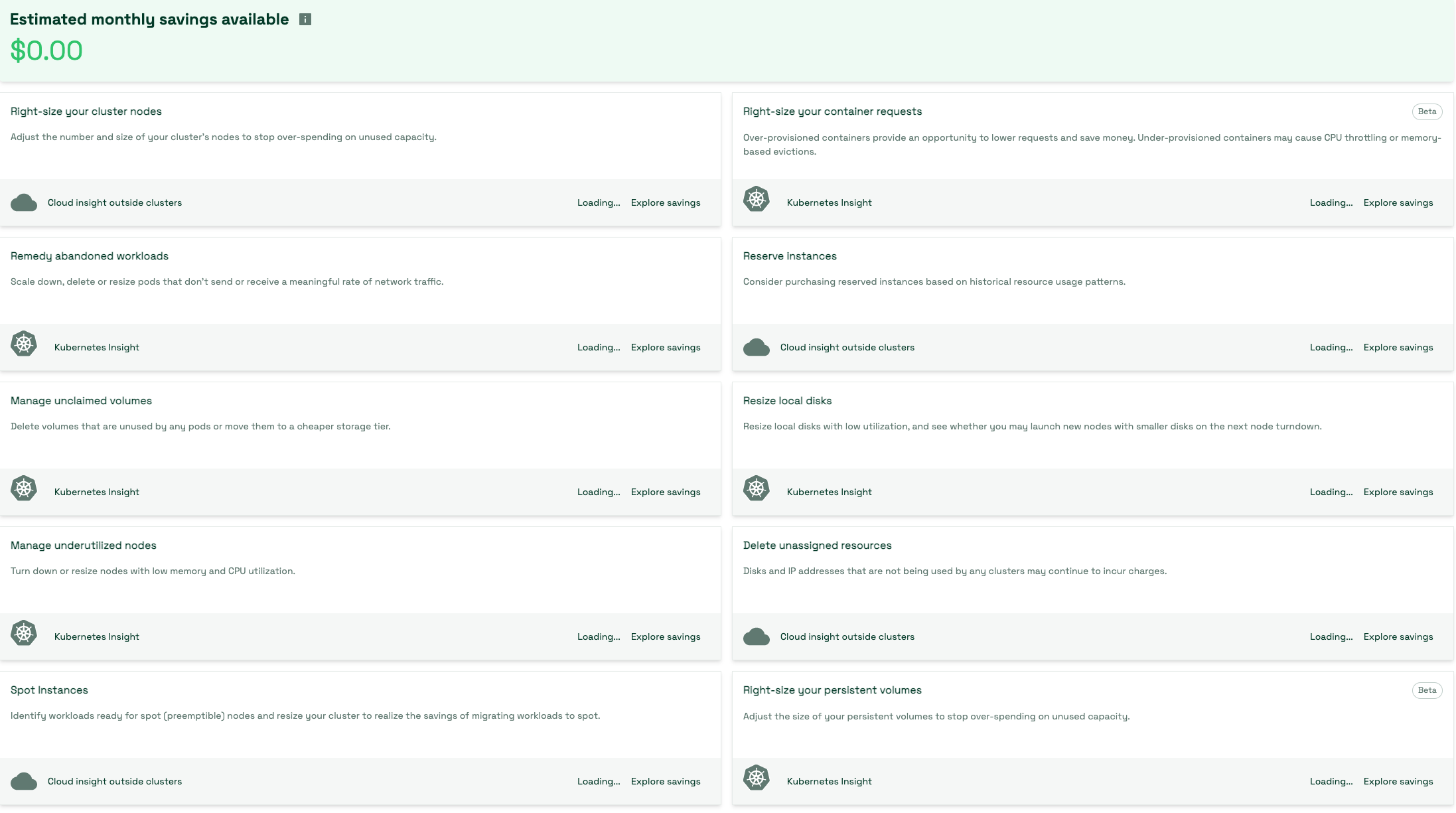
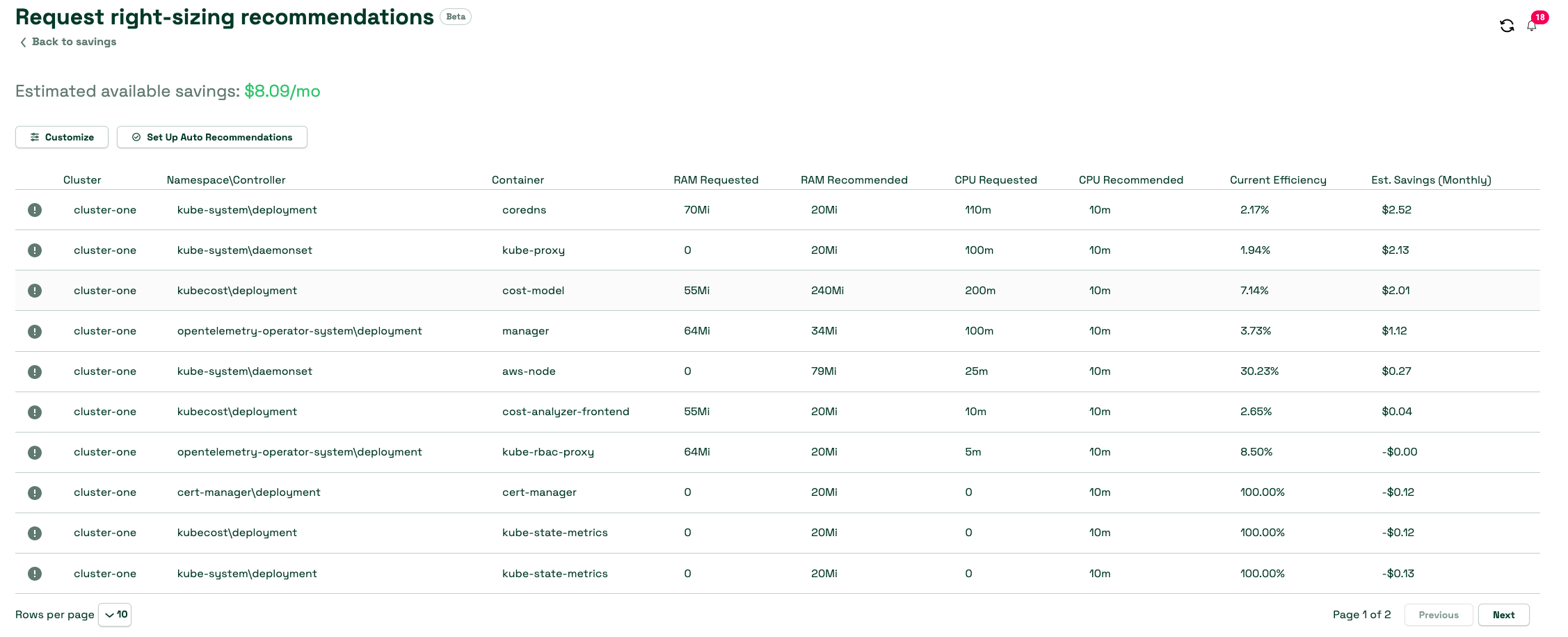
Kubecost は以下の推奨事項を提供できます:
- オーバープロビジョニングとアンダープロビジョニングの両方を考慮したコンテナリクエストのライトサイジング
- 未使用のキャパシティに対する過剰な支出を抑制するためのクラスターノードの数とサイズの調整
- 有意な量のトラフィックの送受信がないポッドのスケールダウン、削除、リサイズ
- スポットノードに適したワークロードの特定
- ポッドによって使用されていないボリュームの特定
また、Kubecost には、Cluster Controller コンポーネントが有効な場合、コンテナリソースリクエストに関する推奨事項を自動的に実装できるプレリリース機能があります。 自動リクエストライトサイジングを使用することで、複雑な YAML やややこしい kubectl コマンドをテストすることなく、クラスター全体のリソース割り当てを即座に最適化できます。 クラスター内のリソースの過剰な割り当てを簡単に排除でき、クラスターのライトサイジングやその他の最適化による大幅なコスト削減への道が開かれます。
Kubecost と Amazon Managed Service for Prometheus の統合
Kubecost は、時系列データベースとしてオープンソースの Prometheus プロジェクトを活用し、Prometheus のデータを後処理してコスト配分の計算を実行します。クラスターのサイズとワークロードの規模によっては、Prometheus サーバーがメトリクスをスクレイピングして保存するのが負担になる場合があります。このような場合、マネージド型の Prometheus 互換モニタリングサービスである Amazon Managed Service for Prometheus を使用して、メトリクスを確実に保存し、Kubernetes のコストを大規模に簡単にモニタリングすることができます。
Kubecost サービスアカウント用の IAM ロール をセットアップする必要があります。クラスターの OIDC プロバイダーを使用して、クラスターのサービスアカウントに IAM 権限を付与します。kubecost-cost-analyzer と kubecost-prometheus-server のサービスアカウントに適切な権限を付与する必要があります。これらは、ワークスペースとの間でメトリクスの送受信に使用されます。コマンドラインで以下のコマンドを実行してください:
eksctl create iamserviceaccount \
--name kubecost-cost-analyzer \
--namespace kubecost \
--cluster <CLUSTER_NAME> \
--region <REGION> \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusQueryAccess \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusRemoteWriteAccess \
--override-existing-serviceaccounts \
--approve
eksctl create iamserviceaccount \
--name kubecost-prometheus-server \
--namespace kubecost \
--cluster <CLUSTER_NAME> --region <REGION> \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusQueryAccess \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusRemoteWriteAccess \
--override-existing-serviceaccounts \
--approve
CLUSTER_NAME は Kubecost をインストールしたい Amazon EKS クラスターの名前で、「REGION」は Amazon EKS クラスターのリージョンです。
完了したら、以下のように Kubecost helm チャートをアップグレードする必要があります:
helm upgrade -i kubecost \
oci://public.ecr.aws/kubecost/cost-analyzer --version <$VERSION> \
--namespace kubecost --create-namespace \
-f https://tinyurl.com/kubecost-amazon-eks \
-f https://tinyurl.com/kubecost-amp \
--set global.amp.prometheusServerEndpoint=${QUERYURL} \
--set global.amp.remoteWriteService=${REMOTEWRITEURL}
Kubecost UI へのアクセス
Kubecost は、kubectl port-forward、Ingress、またはロードバランサーを通じてアクセスできる Web ダッシュボードを提供しています。 Kubecost のエンタープライズバージョンでは、SSO/SAML を使用してダッシュボードへのアクセスを制限し、様々なレベルのアクセス権を提供することもで��きます。 例えば、チームの表示を担当する製品のみに制限することができます。
AWS 環境では、AWS Load Balancer Controller を使用して Kubecost を公開し、認証、認可、ユーザー管理に Amazon Cognito を使用することを検討してください。 詳細については、How to use Application Load Balancer and Amazon Cognito to authenticate users for your Kubernetes web apps をご覧ください。
マルチクラスタービュー
FinOps チームは、ビジネスオーナーに推奨事項を共有するために EKS クラスターをレビューする必要があります。 大規模な運用では、推奨事項を確認するために各クラスターにログインすることが、チームにとって課題となります。 マルチクラスターを使用すると、グローバルに集約されたクラスターのコストを単一の画面で確認できます。 複数のクラスターを持つ環境向けに、Kubecost は Kubecost Free、Kubecost Business、Kubecost Enterprise の 3 つのオプションをサポートしています。 Free と Business モードでは、クラウドの課金調整は各クラスターレベルで実行されます。 Enterprise モードでは、クラウドの課金調整は、Kubecost UI を提供し、メトリクスが保存される共有バケットを使用するプライマリクラスターで実行されます。 Enterprise モードを使用する場合のみ、メトリクスの保持期間が無制限になることに注意してください。