AWS Lambda ベースのサーバーレスオブザーバビリティ
分散システムとサーバーレスコンピューティングの世界では、アプリケーションの信頼性とパフォーマンスを確保するためにオブザーバビリティが重要です。 これは従来のモニタリング以上のものを含んでいます。 Amazon CloudWatch や AWS X-Ray などの AWS オブザーバビリティツールを活用することで、サーバーレスアプリケーションの洞察を得て、問題のトラブルシューティングを行い、アプリケーションのパフォーマンスを最適化できます。 このガイドでは、Lambda ベースのサーバーレスアプリケーションのオブザーバビリティを実装するための重要な概念、ツール、ベストプラクティスについて学びます。
インフラストラクチャやアプリケーションのオブザーバビリティを実装する前の最初のステップは、主要な目標を決定することです。 それは、ユーザーエクスペリエンスの向上、開発者の生産性の向上、Service Level Objective (SLO) の達成、ビジネス収益の増加、またはアプリケーションの種類に応じた他の特定の目標かもしれません。 そのため、これらの主要な目標を明確に定義し、それらをどのように測定するかを確��立してください。 そこから Working Backwards してオブザーバビリティ戦略を設計します。 詳細については、「Monitor what matters」を参照してください。
オブザーバビリティの柱
オブザーバビリティには 3 つの主要な柱があります:
- ログ:アプリケーションやシステム内で発生した障害、エラー、状態変更などの個別のイベントを記録したタイムスタンプ付きの記録
- メトリクス:様々な時間間隔で測定された数値データ(時系列データ)、SLI(リクエストレート、エラーレート、所要時間、CPU 使用率など)
- トレース:複数のアプリケーションやシステム(通常はマイクロサービス)にまたがる単一のユーザーの行動を表すもの
AWS は、AWS Lambda アプリケーションの実用的なインサイトを得るために、ネイティブおよびオープンソースのツールを提供し、ログ記録、メトリクスのモニタリング、トレースを可能にします。
ログ
オブザーバビリティのベストプラクティスガイドのこのセクションでは、以下のトピックについて詳しく説明します:
- 非構造化ログと構造化ログの比較
- CloudWatch Logs Insights
- ログの相関 ID
- Lambda Powertools を使用したコードサンプル
- CloudWatch Dashboards を使用したログの可視化
- CloudWatch Logs の保持期間
ログは、アプリケーション内で発生した個別のイベントです。 これには、障害、エラー、実行パス、その他のイベントが含まれます。 ログは、非構造化、半構造化、または構造化された形式で記録できます。
非構造化ログと構造化ログ
開発者は、アプリケーション内で print や console.log ステートメントを使用した単純なログメッセージから始めることがよくあります。
これらは、プログラムによる解析が難しく、特に異なるロググループにわたって多くのログメッセージを生成する AWS Lambda ベースのアプリケーションでは、スケールに応じた解析が困難です。
その結果、CloudWatch でこれらのログを統合することは困難で、分析が難しくなります。
ログ内の関連情報を見つけるには、テキストマッチや正規表現を使用する必要があります。
以下は、非構造化ログの例です:
[2023-07-19T19:59:07Z] INFO Request started
[2023-07-19T19:59:07Z] INFO AccessDenied: Could not access resource
[2023-07-19T19:59:08Z] INFO Request finished
ご覧のように、ログメッセージには一貫した構造がなく、有用な洞察を得ることが困難です。 また、コンテキスト情報を追加することも難しくなっています。
一方、構造化ログは、情報を一貫したフォーマット(多くの場合 JSON)でログに記録する方法です。 これにより、ログをテキストではなくデータとして扱うことができ、クエリとフィルタリングが簡単になります。 開発者はプログラムによってログを効率的に保存、取得、分析することができます。 また、デバッグも容易になります。 構造化ログは、ログレベルを通じて異なる環境でのログの詳細度を簡単に変更する方法を提供します。 ログレベルに注意を払ってください。 過度なログ出力はコストを増加させ、アプリケーションのスループットを低下させます。 ログを記録する前に、個人を特定できる情報が編集されていることを確認してください。 以下は、構造化ログの例です:
{
"correlationId": "9ac54d82-75e0-4f0d-ae3c-e84ca400b3bd",
"requestId": "58d9c96e-ae9f-43db-a353-c48e7a70bfa8",
"level": "INFO",
"message": "AccessDenied",
"function-name": "demo-observability-function",
"cold-start": true
}
トランザクション、異なるコンポーネント間の相関識別子、アプリケーションのビジネス結果に関する運用情報を出力するには、CloudWatch logs への構造化された一元的なログ記録を推奨します。
CloudWatch Logs Insights
CloudWatch Logs Insights を使用すると、JSON 形式のログのフィールドを自動的に検出できます。 さらに、JSON ログを拡張して、アプリケーション固有のカスタムメタデータをログに記録することができ、これを使用してログの検索、フィルタリング、集計が可能です。
ログの相関 ID
たとえば、API Gateway から受信した HTTP リクエストの場合、相関 ID は requestContext.requestId パスに設定されており、Lambda Powertools を使用してダウンストリームの Lambda 関数で簡単に抽出してログに記録できます。
分散システムでは、多くの場合、複数のサービスやコンポーネントが連携してリクエストを処理します。 そのため、相関 ID をログに記録し、それをダウンストリームシステムに渡すことは、エンドツーエンドのトレースとデバッグに重要です。
相関 ID は、リクエストの最初の段階で割り当てられる一意の識別子です。 リクエストが異なるサービスを通過する際、相関 ID がログに含まれることで、リクエストの全体的な経路をトレースできます。
AWS Lambda のログに相関 ID を手動で挿入するか、AWS Lambda Powertools のようなツールを使用して、API Gateway から相関 ID を簡単に取得し、アプリケーションログと共に記録することができます。 たとえば、HTTP リクエストの相関 ID は、API Gateway で開始され、Lambda 関数などのバックエンドサービスに渡されるリクエスト ID とすることができます。
Lambda Powertools を使用したコードサンプル
ベストプラクティスとして、リクエストのライフサイクルの早い段階、できれば API Gateway やアプリケーションロードバランサーなどのサーバーレスアプリケーションのエントリーポイントで、相関 ID を生成します。 分散システム全体でリクエストを追跡するために、UUID やリクエスト ID、その他の一意の属性を使用します。 相関 ID をカスタムヘッダー、ボディ、またはメタデータの一部として、各リクエストと共に渡します。 ダウンストリームサービスのすべてのログエントリとトレースに相関 ID が含まれていることを確認します。
Lambda 関数のログの一部として相関 ID を手動でキャプチャして含めるか、AWS Lambda Powertools のようなツールを使用することができます。 Lambda Powertools を使用すると、サポートされているアップストリームサービスの事前定義されたリクエストパスマッピングから相関 ID を簡単に取得し、アプリケーションログと共に自動的に追加できます。 また、障害が発生した場合に簡単にデバッグし、根本原因を特定して元のリクエストに関連付けられるように、すべてのエラーメッセージに相関 ID が追加されていることを確認してください。
以下のサーバーレスアーキテ��クチャにおける、相関 ID を使用した構造化ログと CloudWatch での表示方法を示すコードサンプルを見てみましょう:

// Initializing Logger
Logger log = LogManager.getLogger();
// Uses @Logger annotation from Lambda Powertools, which takes optional parameter correlationIdPath to extract correlation Id from the API Gateway header and inserts correlation_id to the Lambda function logs in a structured format.
@Logging(correlationIdPath = "/headers/path-to-correlation-id")
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
...
// The log statement below will also have additional correlation_id
log.info("Success")
...
}
この例では、Java ベースの Lambda 関数が Lambda Powertools ライブラリを使用して、API Gateway リクエストから送られてくる correlation_id をログに記録しています。
コードサンプルの CloudWatch ログの例:
{
"level": "INFO",
"message": "Success",
"function-name": "demo-observability-function",
"cold-start": true,
"lambda_request_id": "52fdfc07-2182-154f-163f-5f0f9a621d72",
"correlation_id": "<correlation_id_value>"
}_
CloudWatch Dashboards を使用したログの可視化
構造化された JSON 形式でデータをログに記録すると、CloudWatch Logs Insights は JSON 出力の値を自動的に検出し、メッセージをフィールドとして解析します。
CloudWatch Logs Insights は、ログストリームを検索およびフィルタリングするための専用の SQL ライクなクエリ 言語を提供します。
glob や正規表現のパターンマッチングを使用して、複数のロググループに対してクエリを実行できます。
また、カスタムクエリを作成して保存し、毎回作り直すことなく再実行することもできます。
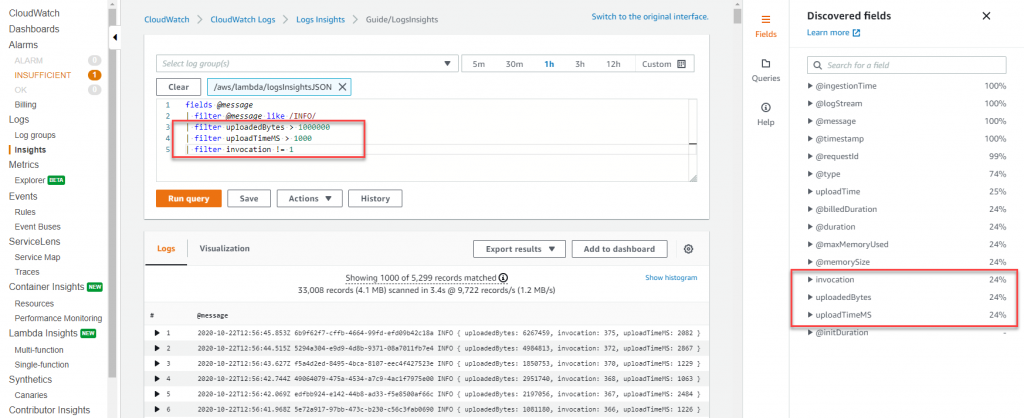
CloudWatch Logs Insights では、1 つ以上の集計関数を使用してクエリから折れ線グラフ、棒グラフ、積み上げ面グラフなどの可視化を生成できます。
これらの可視化を CloudWatch Dashboards に簡単に追加できます。
以下のサンプルダッシュボードは、Lambda 関数の実行時間のパーセンタイルレポートを示しています。
このようなダッシュボードにより、アプリケーションのパフォーマンス改善に注力すべき箇所を素早く把握できます。
平均レイテンシーは重要なメトリクスですが、平均レイテンシーではなく p99 の最適化を目指すべきです。

CloudWatch 以外の場所に(プラットフォーム、関数、拡張機能の)ログを送信するには、Lambda Extensions と Lambda Telemetry API を使用できます。
多くの パートナーソリューション が、Lambda Telemetry API を使用し、システムとの統合を容易にする Lambda レイヤーを提供しています。
CloudWatch Logs Insights を最大限活用するには、構造化ログの形式でどのようなデータをログに取り込むべきかを考え、それによってアプリケーションの健全性をより適切に監視できるようにすることが重要です。
CloudWatch Logs のリテンション
デフォルトでは、Lambda 関数の標準出力に書き込まれたすべてのメッセージが Amazon CloudWatch のログストリー��ムに保存されます。
Lambda 関数の実行ロールには、CloudWatch ログストリームを作成し、ストリームにログイベントを書き込む権限が必要です。
CloudWatch は取り込まれたデータ量とストレージ使用量に基づいて課金されることを認識しておくことが重要です。
そのため、ログの量を減らすことでコストを最小限に抑えることができます。
デフォルトでは CloudWatch ログは無期限に保持され、有効期限が切れることはありません。ログストレージのコストを削減するために、ログ保持ポリシーを設定することをお勧めします。このポリシーをすべてのロググループに適用してください。
環境ごとに異なる保持ポリシーを設定することもできます。
ログの保持期間は AWS コンソールで手動で設定できますが、一貫性とベストプラクティスを確保するために、Infrastructure as Code (IaC) デプロイメントの一部として設定する必要があります。
以下は、Lambda 関数のログ保持期間を設定する方法を示す CloudFormation テンプレートのサンプルです:
Resources:
Function:
Type: AWS::Serverless::Function
Properties:
CodeUri: .
Runtime: python3.8
Handler: main.handler
Tracing: Active
# Explicit log group that refers to the Lambda function
LogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub "/aws/lambda/${Function}"
# Explicit retention time
RetentionInDays: 7
この例では、Lambda 関数と対応するロググループを作成しています。
RetentionInDays プロパティは 7 日間 に設定されており、このロググループ内のログは 7 日間保持された後、自動的に削除されます。
これにより、ログストレージのコストを管理することができます。
メトリクス
オブザーバビリティのベストプラクティスガイドのこのセクションでは、以下のトピックについて詳しく説明します:
- すぐに使えるメトリクスの監視とアラート設定
- カスタムメトリクスの発行
- 埋め込みメトリクスを使用してログからメトリクスを自動生成
- CloudWatch Lambda Insights を使用してシステムレベルのメトリクスを監視
- CloudWatch アラームの作成
標準メトリクスのモニタリングとアラート設定
メトリクスは、様々な時間間隔で測定される数値データ(時系列データ)とサービスレベルの指標(リクエストレート、エラーレート、処理時間、CPU など)です。 AWS サービスは、アプリケーションの運用状態を監視するために、多くの標準メトリクスを提供しています。 アプリケーションに適用可能な重要なメトリクスを設定し、それらを使用してアプリケーションのパフォーマンスを監視します。 重要なメトリクスの例として、関数のエラー、キューの深さ、ステートマシンの実行失敗、API レスポンスタイムなどがあります。
標準メトリクスの課題の 1 つは、CloudWatch ダッシュボードでの分析方法を知ることです�。 例えば、同時実行数を見る場合、最大値、平均値、またはパーセンタイルのどれを見るべきでしょうか? また、監視すべき適切な統計値は、メトリクスごとに異なります。
ベストプラクティスとして、Lambda 関数の ConcurrentExecutions メトリクスでは、アカウントおよびリージョンの制限、または該当する場合は Lambda の予約同時実行数の制限に近づいているかを確認するために、Count 統計を確認します。
イベントの処理にかかる時間を示す Duration メトリクスでは、Average または Max 統計を確認します。
API のレイテンシーを測定する場合は、API Gateway の Latency メトリクスの Percentile 統計を確認します。
P50、P90、P99 は、平均値よりもレイテンシーを監視するためのより優れた方法です。
監視すべきメトリクスを把握したら、アプリケーションのコンポーネントが異常な状態になった時に通知するように、これらの重要なメトリクスにアラートを設定します。 例えば:
- AWS Lambda の場合、Duration、Errors、Throttling、ConcurrentExecutions にアラートを設定します。ストリームベースの呼び出しの場合は IteratorAge に、非同期呼び出しの場合は DeadLetterErrors にアラートを設定します。
- Amazon API Gateway の場合、IntegrationLatency、Latency、5XXError、4XXError にアラートを設定します。
- Amazon SQS の場合、ApproximateAgeOfOldestMessage、ApproximateNumberOfMessageVisible にアラートを設定します。
- AWS Step Functions の場合、ExecutionThrottled、ExecutionsFailed、ExecutionsTimedOut にアラートを設定します。
カスタムメトリクスの発行
アプリケーションのビジネスと顧客の成果に基づいて、重要業績評価指標(KPI)を特定します。 アプリケーションの成功と運用の健全性を評価するために KPI を評価します。 主要なメトリクスはアプリケーションの種類によって異なりますが、サイト訪問数、注文数、航空券購入数、ページ読み込み時間、ユニークビジター数などが例として挙げられます。
AWS CloudWatch にカスタムメトリクスを発行する方法の 1 つは、CloudWatch メトリクス SDK の putMetricData API を呼び出すことです。
しかし、putMetricData API 呼び出しは同期的です。
これにより Lambda 関数の実行時間が長くなり、アプリケーション内の他の API 呼び出しをブロックする可能性があり、パフォーマンスのボトルネックにつながる可能性があります。
また、Lambda 関数の実行時間が長くなると、コストが高くなります。
さらに、CloudWatch に送信されるカスタムメトリクスの数と、実行される API 呼び出し(PutMetricData API 呼び出し)の数の両方に対して課金されます。
カスタムメトリクスを発行するより効率的でコスト効果の高い方法は CloudWatch Embedded Metrics Format(EMF)を使用することです。
CloudWatch Embedded Metrics フォーマットを使用す�ると、CloudWatch ログに書き込まれたログとして 非同期に カスタムメトリクスを生成でき、より低コストでアプリケーションのパフォーマンスを向上させることができます。
EMF を使用すると、詳細なログイベントデータと共にカスタムメトリクスを埋め込むことができ、CloudWatch は自動的にこれらのカスタムメトリクスを抽出して、標準のメトリクスと同様に可視化やアラームの設定を行うことができます。
埋め込みメトリクスフォーマットでログを送信することで、CloudWatch Logs Insights を使用してクエリを実行でき、メトリクスのコストではなくクエリのコストのみを支払うことになります。
これを実現するには、EMF 仕様 を使用してログを生成し、PutLogEvents API を使用して CloudWatch に送信します。
このプロセスを簡素化するために、EMF フォーマットでメトリクスを作成をサポートする 2 つのクライアントライブラリ があります。
- 低レベルクライアントライブラリ(aws-embedded-metrics)
- Lambda Powertools Metrics
CloudWatch Lambda Insights を使用してシステムレベルのメトリクスを監視する
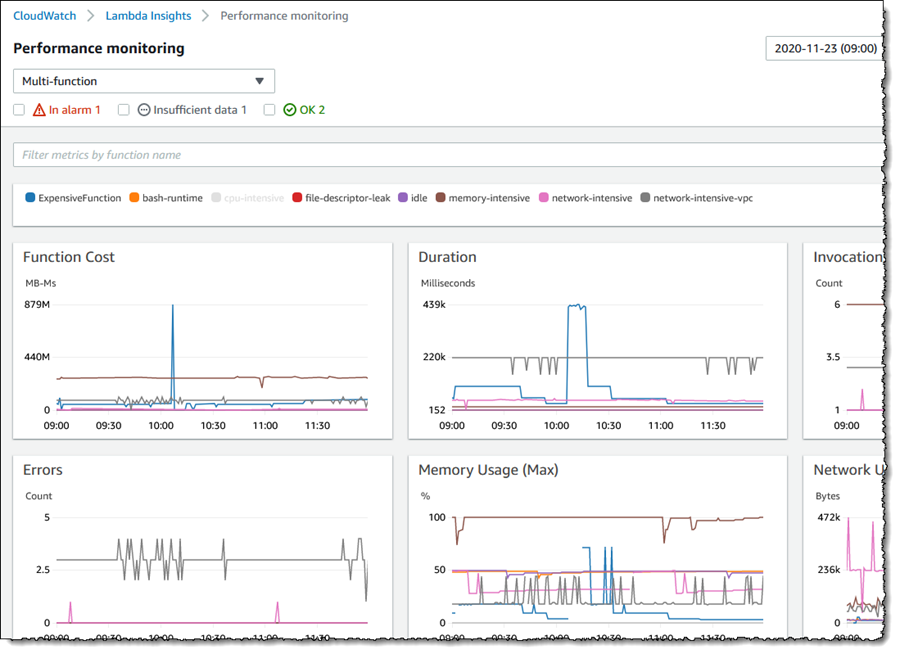
CloudWatch Lambda Insights は、CPU 時間、メモリ使用量、ディスク使用率、ネットワークパフォーマンスなどのシステムレベルのメトリクスを提供します。
また、コールドスタート や Lambda ワーカーのシャットダウンなどの診断情報を収集、集約、要約します。
Lambda Insights は、Lambda レイヤーとしてパッケージ化された CloudWatch Lambda 拡張機能を活用します。
有効化すると、システムレベルのメトリクスを収集し、Lambda 関数の呼び出しごとに 1 つのパフォーマンスログイベントを組み込みメトリクス形式で CloudWatch Logs に出力します。
CloudWatch Lambda Insights はデフォルトでは有効になっておらず、Lambda 関数ごとに有効にする必要があります。
AWS コンソールまたは Infrastructure as Code (IaC) を使用して有効化できます。
以下は、AWS Serverless Application Model (SAM) を使用して有効にする例です。
Lambda 関数に LambdaInsightsExtension 拡張レイヤーを追加し、マネージド IAM ポリシー CloudWatchLambdaInsightsExecutionRolePolicy も追加します。
これにより、Lambda 関数にログストリームを作成し、PutLogEvents API を呼び出してログを書き込むための権限が付与されます。
// Add LambdaInsightsExtension Layer to your function resource
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Layers:
- !Sub "arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension:14"
// Add IAM policy to enable Lambda function to write logs to CloudWatch
Resources:
MyFunction:
Type: AWS::Serverless::Function
Properties:
Policies:
- `CloudWatchLambdaInsightsExecutionRolePolicy`
その後、CloudWatch コンソールの Lambda Insights でこれらのシステムレベルのパフォーマンスメトリクスを表示できます。
CloudWatch アラームの作成
CloudWatch アラームを作成し、メトリクスが閾値を超えた際に必要なアクションを実行することは、オブザーバビリティの重要な部分です。Amazon CloudWatch アラーム は、アプリケーションやインフラストラクチャのメトリクスが静的または動的に設定された閾値を超えた場合に、通知や自動修復アクションを実行するために使用されます。
メトリクスのアラームを設定するには、一連のアクションをトリガーする閾値を選択します。固定の閾値は静的閾値として知られています。例えば、Lambda 関数の Throttles メトリクスに対して、5 分間で 10% を超えた場合にアラームを発生するように設定できます。これは、Lambda 関数がアカウントとリージョンの最大同時実行数に達した可能性があることを示しています。
サーバーレスアプリケーションでは、SNS (Simple Notification Service) を使用してアラートを送信するのが一般的です。これにより、ユーザーはメール、SMS、その他のチャネルを通じてアラートを受信できます。さらに、SNS トピックに Lambda 関数をサブスクライブすることで、アラームを発生させた問題を自動的に修復することができます。
例えば、Lambda 関数 A が SQS キューをポーリングし、下流のサービスを呼び出しているとします。下流のサービスがダウンして応答しない場合、Lambda 関数は SQS からのポーリングを続け、失敗しながら下流のサービスを呼び出し続けます。これらのエラーを監視し、SNS を使用して CloudWatch アラームで適切なチームに通知することもできますが、別の Lambda 関数 B (SNS サブスクリプション経由) を呼び出して、下流のサービスが復旧するまで Lambda 関数 A のイベントソースマッピングを無効にし、SQS キューのポーリングを停止することもできます。
個別のメトリクスにアラームを設定することは良いですが、アプリケーションの運用状態とパフォーマンスをより良く理解するために、複数のメトリクスを監視する必要がある場合があります。このようなシナリオでは、Metric Math 式を使用して複数のメトリクスに基づくアラームを設定する必要があります。
例えば、AWS Lambda のエラーを監視する際に、少数のエラーではアラームを発生させたくない場合、パーセンテージ形式でエラー率の式を作成できます。つまり、ErrorRate = errors / invocation * 100 という式を作成し、設定された評価期間内に ErrorRate が 20% を超えた場合にアラートを送信するアラームを作成できます。
トレーシング
オブザーバビリティのベストプラクティスガイドのこのセクションでは、以下のトピックについて詳しく説明します:
- 分散トレーシングと AWS X-Ray の概要
- 適切なサンプリングルールの適用
- X-Ray SDK を使用した他のサービスとの相互作用のトレース
- X-Ray SDK を使用した統合サービスのトレーシングのコードサンプル
分散トレー��シングと AWS X-Ray の概要
ほとんどのサーバーレスアプリケーションは、複数の AWS サービスを使用する複数のマイクロサービスで構成されています。 サーバーレスアーキテクチャの性質上、分散トレーシングが非常に重要です。 効果的なパフォーマンスモニタリングとエラー追跡のためには、ソース呼び出し元からすべてのダウンストリームサービスまで、アプリケーションフロー全体でトランザクションをトレースすることが重要です。 個々のサービスのログを使用してこれを実現することは可能ですが、AWS X-Ray のようなトレーシングツールを使用する方が迅速で効率的です。 詳細については、Instrumenting your application with AWS X-Ray をご覧ください。
AWS X-Ray を使用すると、マイクロサービスを通過するリクエストをトレースできます。 X-Ray サービスマップを使用すると、異なる統合ポイントを理解し、アプリケーションのパフォーマンス低下を特定できます。 数回のクリックで、アプリケーションのどのコンポーネントがエラー、スロットリング、レイテンシーの問題を引き起こしているかを素早く特定できます。 サービスグラフの下で、個々のトレースを確認して、各マイクロサービスが要した正確な所要時間を特定することもできます。
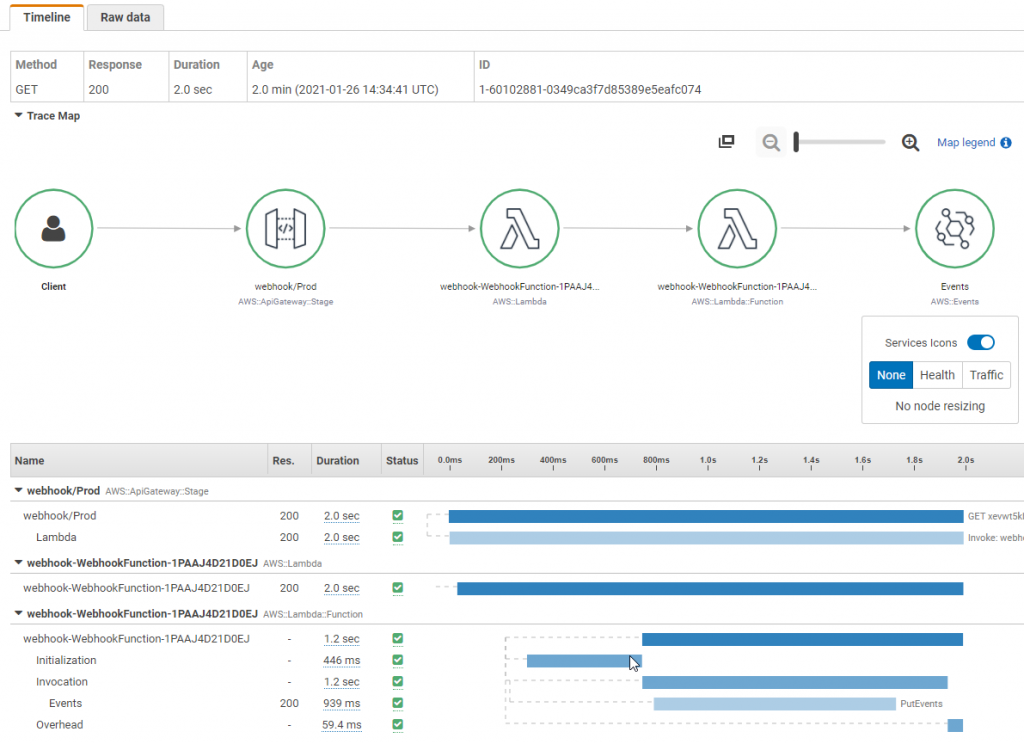
ベストプラクティスとして、ダウンストリームの呼び出しやモニタリングが必要な特定の機能に対して、コードにカスタムサブセグメントを作成します。
例えば、外部の HTTP API への呼び出しや、SQL データベースクエリのためにサブセグメントを作成できます。
例えば、ダウンストリームサービスを呼び出す関数のカスタムサブセグメントを作成するには、captureAsyncFunc 関数 (node.js の場合) を使用します。
var AWSXRay = require('aws-xray-sdk');
app.use(AWSXRay.express.openSegment('MyApp'));
app.get('/', function (req, res) {
var host = 'api.example.com';
// start of the subsegment
AWSXRay.captureAsyncFunc('send', function(subsegment) {
sendRequest(host, function() {
console.log('rendering!');
res.render('index');
// end of the subsegment
subsegment.close();
});
});
});
この例では、アプリケーションは sendRequest 関数の呼び出しのために send という名前のカスタムサブセグメントを作成します。
captureAsyncFunc は、非同期呼び出しが完了したときにコールバック関数内でクローズする必要があるサブセグメントを渡します。
適切なサンプリングルールを適用する
AWS X-Ray SDK は、デフォルトではすべてのリクエストをトレースしません。 高コストを発生させることなく、リクエストの代表的なサンプルを提供するために、控えめなサンプリングルールを適用します。 ただし、特定の要件に基づいて、デフォルトのサンプリングルールをカスタマイズしたり、サンプリングを完全に無効にしてすべてのリクエストのトレースを開始したりすることができます。
AWS X-Ray は監査やコンプライアンスツールとして使用することを意図していないことに注意することが重要です。
アプリケーションのタイプごとに異なるサンプリングレート を設定することを検討する必要があります。
たとえば、バックグラウンドポーリングやヘルスチェックなどの大量の読み取り専用呼び出しは、発生する可能性のある問題を特定するのに十分なデータを提供しながら、より低いレートでサンプリングすることができます。
また、環境ごとに異なるサンプリングレート を設定することもできます。
たとえば、開発環境では、エラーやパフォーマンスの問題を簡単にトラブルシューティングできるように、すべてのリクエストをトレースすることができます。
一方、本番環境ではトレース数を少なくすることができます。
広範なトレースはコストの増加につながる可能性があることにも注意 する必要があります。
サンプリングルールの詳細については、X-Ray コンソールでのサンプリングルールの設定を参照してください。
X-Ray SDK を使用して他の AWS サービスとの連携をトレースする
X-Ray トレースは、AWS Lambda や Amazon API Gateway などのサービスでは、数回のクリックまたは IaC ツールでの数行のコードで簡単に有効化できます。 しかし、他のサービスではコードを計装するために追加の手順が必要です。 X-Ray と統合されている AWS サービスの完全なリストはこちらをご覧ください。
DynamoDB のような X-Ray と統合されていないサービスへの呼び出しを計装するには、AWS SDK の呼び出しを AWS X-Ray SDK でラップしてトレースを取得できます。 例えば、node.js を使用する場合、以下のコード例に従って AWS SDK の呼び出しをすべてキャプチャできます:
X-Ray SDK を使用したトレース統合サービスのコードサンプル
//... FROM (old code)
const AWS = require('aws-sdk');
//... TO (new code)
const AWSXRay = require('aws-xray-sdk-core');
const AWS = AWSXRay.captureAWS(require('aws-sdk'));
...
個別のクライアントを計測するには、AWS SDK クライアントを AWSXRay.captureAWSClient の呼び出しでラップします。captureAWS と captureAWSClient を一緒に使用しないでください。これにより重複したトレースが発生します。
追加リソース
まとめ
AWS Lambda ベースのサーバーレスアプリケーションに関するこのオブザーバビリティのベストプラクティスガイドでは、Amazon CloudWatch や AWS X-Ray などのネイティブ AWS サービスを使用したロギング、メトリクス、トレーシングの重要な側面を強調しました。 アプリケーションにオブザーバビリティの��ベストプラクティスを簡単に追加するために、AWS Lambda Powertools ライブラリの使用を推奨しています。 これらのベストプラクティスを採用することで、サーバーレスアプリケーションに関する貴重な洞察を得ることができ、エラーの迅速な検出とパフォーマンスの最適化が可能になります。
さらに詳しく学ぶには、AWS One Observability Workshop の AWS Native Observability モジュールの実践をお勧めします。