AWS における Databricks のモニタリングとオブザーバビリティのベストプラクティス
Databricks は、データ分析と AI/ML ワークロードを管理するためのプラットフォームです。このガイドは、AWS のネイティブなオブザーバビリティサービスやマネージド型オープンソースサービスを使用して、AWS 上の Databricks でワークロードを実行しているお客様のモニタリングをサポートすることを目的としています。
Databricks をモニタリングする理由
Databricks クラスターを管理する運用チームは、統合されたカスタマイズ可能なダッシュボードを活用することで、以下のような恩恵を受けることができます:
- ワークロードのステータス、エラー、パフォーマンスのボトルネックの追跡
- 時間経過に伴う総リソース使用量やエラー率など、望ましくない動作に対するアラート設定
- ルート原因分析やカスタマイズされたメトリクスの抽出のための一元化されたログ管理
監視すべき項目
Databricks は、クラスターインスタンスで Apache Spark を実行しており、メトリクスを公開するネイティブ機能を備えています。 これらのメトリクスは、ドライバー、ワーカー、およびクラスターで実行されているワークロードに関する情報を提供します。
Spark を実行しているインスタンスには、ストレージ、CPU、メモリ、ネットワークに関する追加の有用な情報があります。 Databricks クラスターのパフォーマンスにどのような外部要因が影響を与える可能性があるかを理解することが重要です。 多数のインスタンスを持つクラスターの場合、ボトルネックと全体的な健全性を理解することも同様に重要です。
モニタリング方法
コレクターとその依存関係をインストールするには、Databricks の初期化スクリプトが必要です。これらのスクリプトは、Databricks クラスターの各インスタンスで起動時に実行されます。
また、Databricks クラスターには、インスタンスプロファイルを使用してメトリクスとログを送信するための権限が必要です。
最後に、Databricks クラスターの Spark 設定でメトリクス名前空間を設定することがベストプラクティスです。testApp をクラスターの適切な参照に置き換えてください。
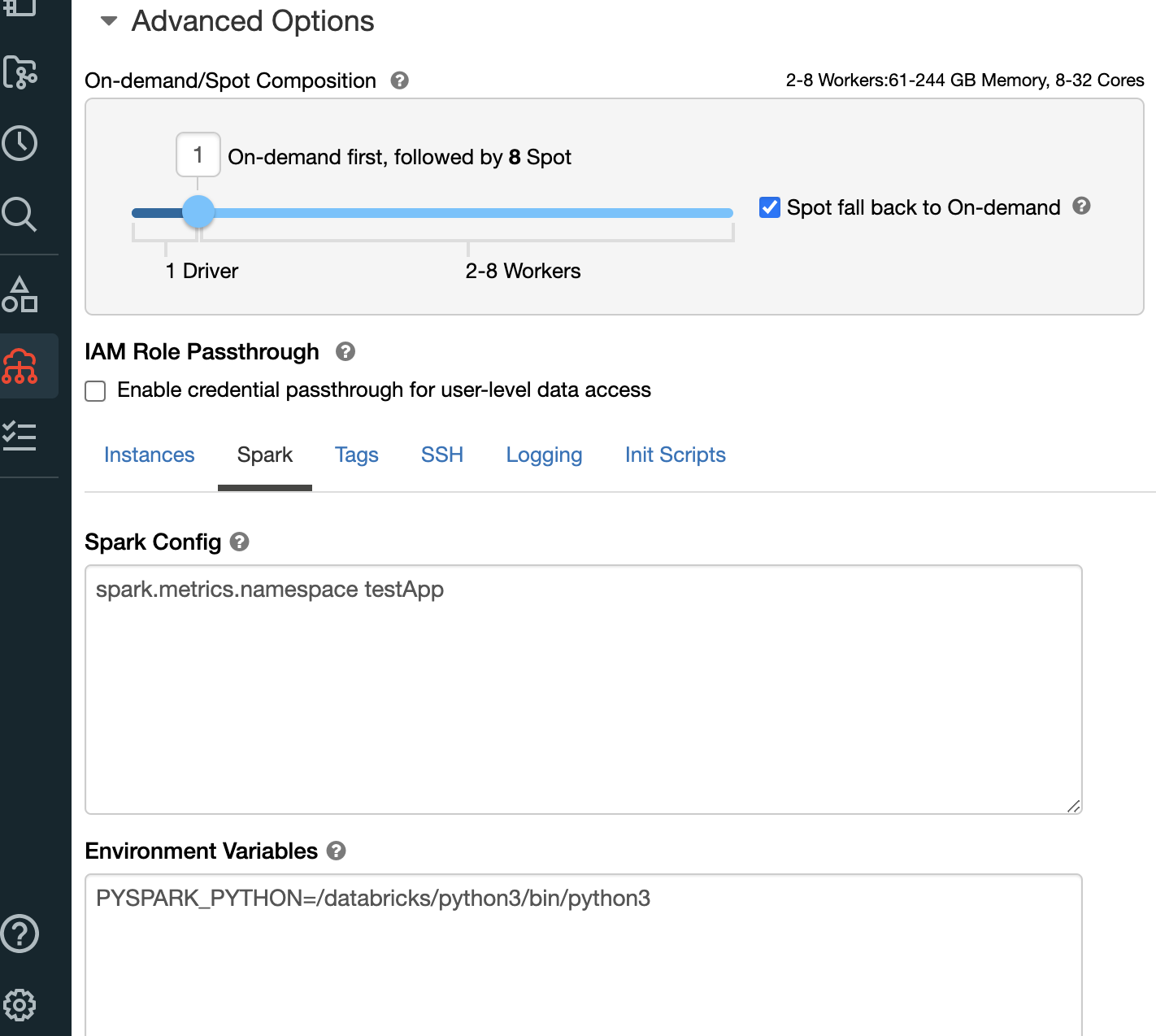 図 1: メトリクス名前空間の Spark 設定例
図 1: メトリクス名前空間の Spark 設定例
DataBricks における優れたオブザーバビリティソリューションの主要な要素
1) メトリクス: メトリクスは、一定期間にわたって測定されたアクティビティや特定のプロセスを表す数値です。Databricks には以下のような種類のメトリクスがあります:
CPU、メモリ、ディスク、ネットワークなどのシステムリソースレベルのメトリクス。 カスタムメトリクスソース、StreamingQueryListener、QueryExecutionListener を使用したアプリケーションメトリクス。 MetricsSystem によって公開される Spark メトリクス。
2) ログ: ログは発生した一連のイベントを表現し、それらについて線形的なストーリーを語ります。Databricks には以下のような種類のログがあります:
- イベントログ
- 監査ログ
- ドライバーログ:stdout、stderr、log4j カスタムログ(構造化ログを有効化)
- エグゼキュターログ:stdout、stderr、log4j カスタムログ(構造化ログを有効化)
3) トレース: スタックトレースはエンドツーエンドの可視性を提供し、ステージ全体を通したフローを表示します。これは、エラーやパフォーマンスの問題を引き起こすステージやコードを特定するためのデバッグ時に役立ちます。
4) ダッシュボード: ダッシュボードは、アプリケーションやサービスのゴールデンメトリクスの優れた概要ビューを提供します。
5) アラート: アラートは、対応が必要な状況についてエンジニアに通知します。
AWS ネイティブのオブザーバビリティオプション
Ganglia UI や Log Delivery などのネイティブソリューションは、システムメトリクスの収集や Apache Spark™ メトリクスのクエリに優れたソリューションです。しかし、以下のような改善の余地がある領域があります:
- Ganglia はアラートをサポートしていません。
- Ganglia はログから派生したメトリクス(例:ERROR ログの増加率)の作成をサポートしていません。
- データの正確性、データの鮮度、エンドツーエンドのレイテンシーに関連する SLO (Service Level Objectives) や SLI (Service Level Indicators) を追跡するカスタムダッシュボードを使用して、Ganglia で可視化することができません。
Amazon CloudWatch は、AWS 上の Databricks クラスターを監視・管理するための重要なツールです。クラスターのパフォーマンスに関する貴重な洞察を提供し、問題の迅速な特定と解決を支援します。Databricks と CloudWatch の統合および構造化ログの有効化により、これらの領域を改善することができます。CloudWatch Application Insights はログに含まれるフィールドを自動的に検出し、CloudWatch Logs Insights は目的に特化したクエリ言語を提供してデバッグと分析を迅速化します。
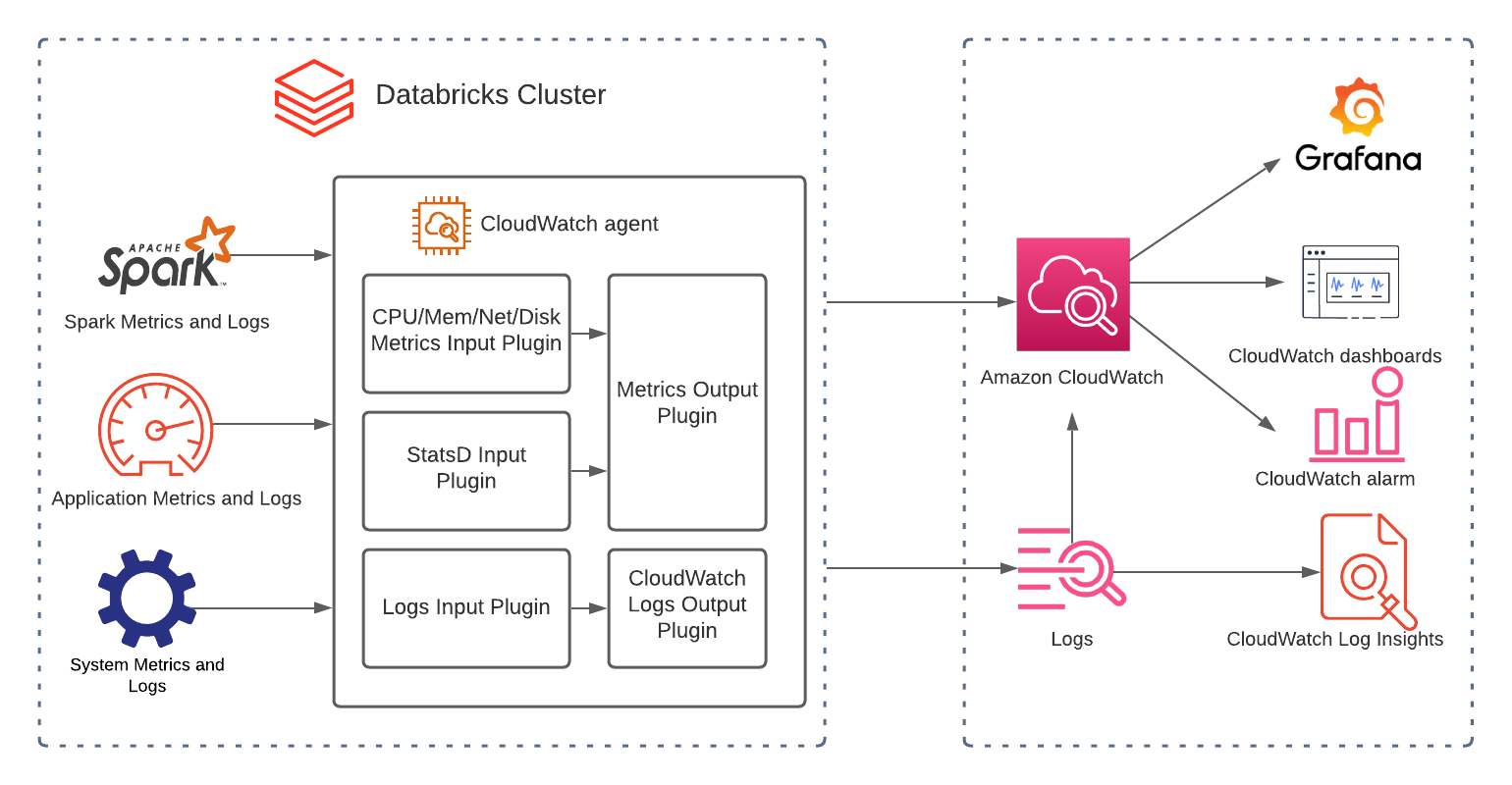 図 2:Databricks CloudWatch アーキテクチャ
図 2:Databricks CloudWatch アーキテクチャ
CloudWatch を使用して Databricks を監視する方法の詳細については、以下を参照してください: How to Monitor Databricks with Amazon CloudWatch
オープンソースソフトウェアのオブザーバビリティオプション
Amazon Managed Service for Prometheus は、Prometheus 互換のモニ��タリングマネージドサービスで、サーバーレスで提供されます。メトリクスの保存と、それらのメトリクスに基づいて作成されたアラートの管理を担当します。Prometheus は人気のあるオープンソースモニタリング技術で、Kubernetes に次ぐ Cloud Native Computing Foundation の 2 番目のプロジェクトです。
Amazon Managed Grafana は、Grafana のマネージドサービスです。Grafana は時系列データの可視化のためのオープンソース技術で、オブザーバビリティによく使用されています。Grafana を使用して、Amazon Managed Service for Prometheus、Amazon CloudWatch など、さまざまなソースからのデータを可視化できます。Databricks のメトリクスとアラートの可視化に使用されます。
AWS Distro for OpenTelemetry は、AWS がサポートする OpenTelemetry プロジェクトのディストリビューションで、トレースとメトリクスを収集するためのオープンソース標準、ライブラリ、サービスを提供します。OpenTelemetry を通じて、Prometheus や StatsD などのさまざまなオブザーバビリティデータ形式を収集し、このデータを強化して、CloudWatch や Amazon Managed Service for Prometheus などの複数の送信先に送信できます。
ユースケース
AWS ネイティブサービスは Databricks クラスターを管理するために必要なオブザーバビリティを提供しますが、オープンソ��ースのマネージドサービスを使用することが最適な選択となるシナリオもあります。
Prometheus と Grafana は非常に人気のあるテクノロジーで、多くの企業ですでに使用されています。AWS のオブザーバビリティ向けオープンソースサービスを使用することで、運用チームは既存のインフラストラクチャ、同じクエリ言語、既存のダッシュボードとアラートを使用して Databricks ワークロードを監視できます。その際、これらのサービスのインフラストラクチャ、スケーラビリティ、パフォーマンスの管理に関する負担を軽減できます。
ADOT は、CloudWatch や Prometheus などの異なる送信先にメトリクスとトレースを送信する必要がある場合や、OTLP や StatsD などの異なるタイプのデータソースを扱う必要があるチームにとって、最適な選択肢です。
最後に、Amazon Managed Grafana は CloudWatch や Prometheus を含む多くの異なるデータソースをサポートし、複数のツールを使用することを決めたチームのデータ相関を支援します。また、すべての Databricks クラスターのオブザーバビリティを可能にするテンプレートの作成や、Infrastructure as Code を通じてプロビジョニングと設定を可能にする強力な API を提供します。
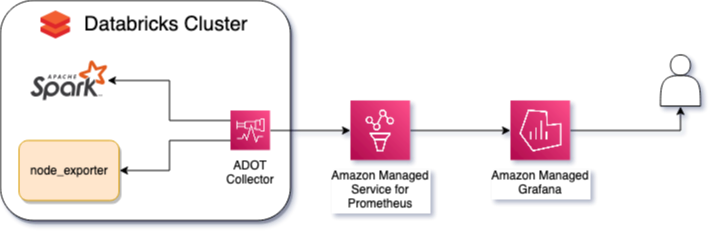 図 3: Databricks オープンソースオブザーバビリティアーキテクチャ
図 3: Databricks オープンソースオブザーバビリティアーキテクチャ
AWS のオブザーバビリティ向けマネージドオープンソースサービスを使用して Databricks クラスターからメトリクスを観測するには、メトリクスとアラートの可視化のための Amazon Managed Grafana ワークスペースと、Amazon Managed Grafana ワークスペースのデータソースとして設定された Amazon Managed Service for Prometheus ワークスペースが必要です。
収集する必要がある重要なメトリクスには、Spark メトリクスとノードメトリクスの 2 種類があります。
Spark メトリクスは、クラスター内の現在のワーカー数やエグゼキューター数、処理中にノード間でデータを交換する際のシャッフル、RAM とディスク間でデータが移動するスピルなどの情報を提供します。これらのメトリクスを公開するには、Databricks 管理コンソールで Spark ネイティブの Prometheus(バージョン 3.0 以降で利用可能)を有効にし、init_script を通じて設定する必要があります。
ディスク使用量、CPU 時間、メモリ、ストレージパフォーマンスなどのノードメトリクスを追跡するには、node_exporter を使用します。これは追加の設定なしで使用できますが、重要なメトリクスのみを公開するようにすべきです。
ADOT Collector は、クラスターの各ノードにインストールする必要があります。これは Spark と node_exporter の両方から公開されたメトリクスをスクレイピングし、メトリクスをフィルタリングし、cluster_name などのメタデータを注入して、これらのメトリクスを Prometheus ワークスペースに送信します。
ADOT Collector と node_exporter の両方を init_script を通じてインストールおよび設定する必要があります。
Databricks クラスターは、Prometheus ワークスペースにメトリクスを書き込む権限を持つ IAM ロールで設定する必要があります。
ベスト プラクティス
価値のあるメトリクスを優先する
Spark と node_exporter は、複数のメトリクスと同じメトリクスの複数のフォーマットを公開しています。 監視とインシデント対応に有用なメトリクスをフィルタリングしないと、問題検出までの平均時間が増加し、サンプルの保存コストが増加し、価値のある情報を見つけて理解することが難しくなります。 OpenTelemetry の Processors を使用することで、価値のあるメトリクスのみをフィルタリングして保持したり、意味のないメトリクスをフィルタリングで除外したり、AMP に送信する前にメトリクスを集計して計算したりすることが可能です。
アラート疲れを防ぐ
価値のあるメトリクスが AMP に取り込まれたら、アラートを設定することが重要です。 しかし、リソース使用量のすべてのバーストに対してアラートを設定すると、アラート疲れを引き起こす可能性があります�。 これは、ノイズが多すぎるとアラートの重要度への信頼性が低下し、重要なイベントが検出されなくなる状態です。 複数の関連するアラートが個別の通知を生成するような曖昧さを避けるために、AMP のアラートルールのグループ機能を使用する必要があります。 また、アラートには適切な重要度を設定し、ビジネスの優先順位を反映させる必要があります。
Amazon Managed Grafana ダッシュボードの再利用
Amazon Managed Grafana は、Grafana のネイティブなテンプレート機能を活用しています。これにより、既存および新規の Databricks クラスターすべてのダッシュボードを作成できます。 各クラスターに対して手動で可視化を作成し、維持管理する必要がなくなります。 この機能を使用するには、クラスターごとにメトリクスをグループ化するための適切なラベルが必要です。 これも OpenTelemetry プロセッサーで実現可能です。