AWS Distro for OpenTelemetry (ADOT) Collector の運用
ADOT collector は、CNCF による OpenTelemetry Collector のダウンストリームディストリビューションです。
お客様は ADOT Collector を使用して、オンプレミス、AWS、その他のクラウドプロバイダーなど、さまざまな環境からメトリクスやトレースなどのシグナルを収集できます。
実際の環境で ADOT Collector を大規模に運用するためには、オペレーターは Collector の健全性を監視し、必要に応じてスケールする必要があります。このガイドでは、本番環境で ADOT Collector を運用するために取るべきアクションについて学びます。
デプロイメントアーキテクチャ
要件に応じて、検討すべきデプロイメントオプションがいくつかあります。
- コレクターなし
- エージェント
- ゲートウェイ
これらの概念の詳細については、OpenTelemetry のドキュメントを参照してください。
コレクターなし
このオプションは、コレクターを完全に除外します。ご存知かもしれませんが、OTEL SDK から宛先サービスに直接 API 呼び出しを行い、シグナルを送信することが可能です。 例えば、ADOT Collector のようなプロセス外エージェントにスパンを送信する代わりに、アプリケーションプロセスから直接 AWS X-Ray の PutTraceSegments API を呼び出すことを考えてみてください。
このアプローチに関するガイダンスは AWS 固有の側面がないため、より詳細な情報については、アップストリームのドキュメントのセクションを参照することを強くお勧めします。
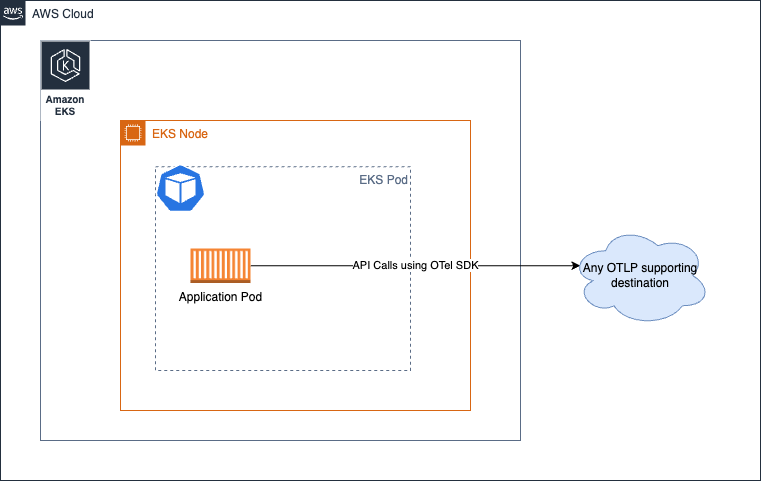
エージェント
このアプローチでは、コレクターを分散方式で実行し、シグナルを各送信先に収集します。No Collector オプションとは異なり、ここでは関心を分離し、アプリケーションがリモート API コールにリソースを使用する必要性を切り離し、代わりにローカルでアクセス可能なエージェントと通信します。
基本的に、Amazon EKS 環境では、以下のように コレクターを Kubernetes のサイドカーとして実行します:
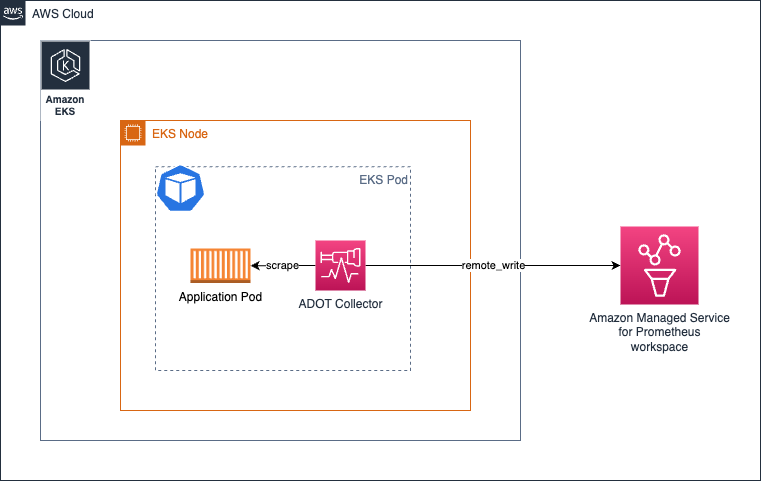
上記のアーキテクチャでは、コレクターがアプリケーションコンテナと同じ Pod で実行されているため、localhost からターゲットをスクレイピングすることになり、サービスディスカバリーメカニズムを使用する必要はありません。
同じアーキテクチャはトレースの収集にも適用されます。ここに示すように、OTEL パイプラインを作成するだけです。
メリットとデメリット
-
この設計を支持する 1 つの論点�は、ターゲットが localhost のソースに限定されているため、Collector が処理を行うために特別な量のリソース (CPU、メモリ) を割り当てる必要がないことです。
-
このアプローチを使用する際のデメリットは、Collector Pod の設定のバリエーション数が、クラスター上で実行しているアプリケーションの数に比例することです。 つまり、Pod の予想されるワークロードに応じて、CPU、メモリ、その他のリソース割り当てを Pod ごとに個別に管理する必要があります。 これを慎重に行わないと、Collector Pod に対するリソースの過剰割り当てや過少割り当てが発生し、パフォーマンスの低下や、他の Pod が使用できるはずの CPU サイクルとメモリの占有につながる可能性があります。
また、ニーズに応じて Deployments、Daemonset、Statefulset などの他のモデルで Collector をデプロイすることもできます。
Amazon EKS での Daemonset としてのコレクターの実行
コレクターの負荷(メトリクスのスクレイピングと Amazon Managed Service for Prometheus ワークスペースへの送信)を EKS ノード全体に均等に分散させたい場合は、コレクターを Daemonset として実行することができます。
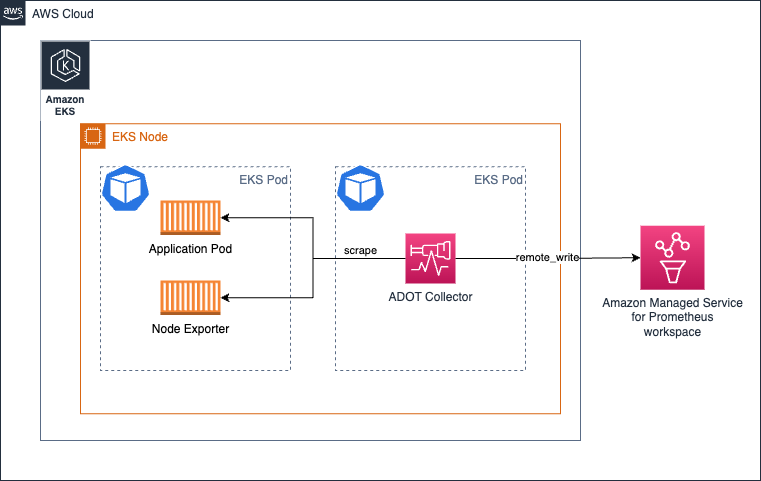
コレクターが自身のホスト/ノードからのみターゲットをスクレイプするように、keep アクションが設定されていることを確認してください。
参考として、以下にサンプルを示します。より詳細な設定についてはこちらをご覧ください。
scrape_configs:
- job_name: kubernetes-apiservers
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: $K8S_NODE_NAME
source_labels: [__meta_kubernetes_endpoint_node_name]
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
同じアーキテクチャはトレースの収集にも使用できます。この場合、コレクターが Prometheus メトリクスをスクレイプするためにエンドポイントにアクセスする代わりに、トレースのスパンはアプリケーション Pod からコレクターに送信されます。
メリットとデメリット
利点
- スケーリングの懸念が最小限
- 高可用性の設定が課題
- 使用される Collector のコピーが多すぎる
- ログのサポートが容易
欠点
- リソース使用の観点から最適ではない
- リソース割り当てが不均衡
Amazon EC2 でのコレクターの実行
EC2 でコレクターを実行する場合、サイドカーアプローチはないため、EC2 インスタンス上でエージェントとしてコレクターを実行することになります。以下のような静的なスクレイプ設定を行うことで、インスタンス内のメトリクスを収集するターゲットを検出できます。
以下の設定は、localhost 上のポート 9090 と 8081 のエンドポイントをスクレイプします。
One Observability Workshop の EC2 に焦点を当てたモジュール で、このトピックについてのハンズオンの詳細な体験ができます。
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090', 'localhost:8081']
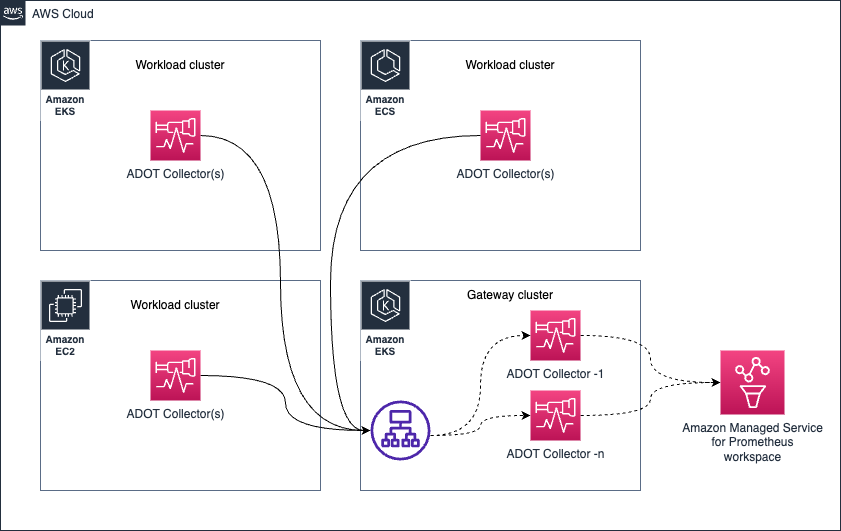
Amazon EKS でコレクターを Deployment として実行する
コレクターを Deployment として実行することは、コレクターの高可用性を確保したい場合に特に有用です。 ターゲットの数、スクレイプ可能なメトリクスなどに応じて、コレクターのリソースを適切に調整する必要があります。 これにより、コレクターのリソース不足を防ぎ、シグナル収集の問題を回避できます。
このトピックの詳細については、こちらのガイドをご覧ください。
以下のアーキテクチャは、メトリクスとトレースを収集するために、ワークロードノードとは別のノードにコレクターをデプロイする方法を示しています。
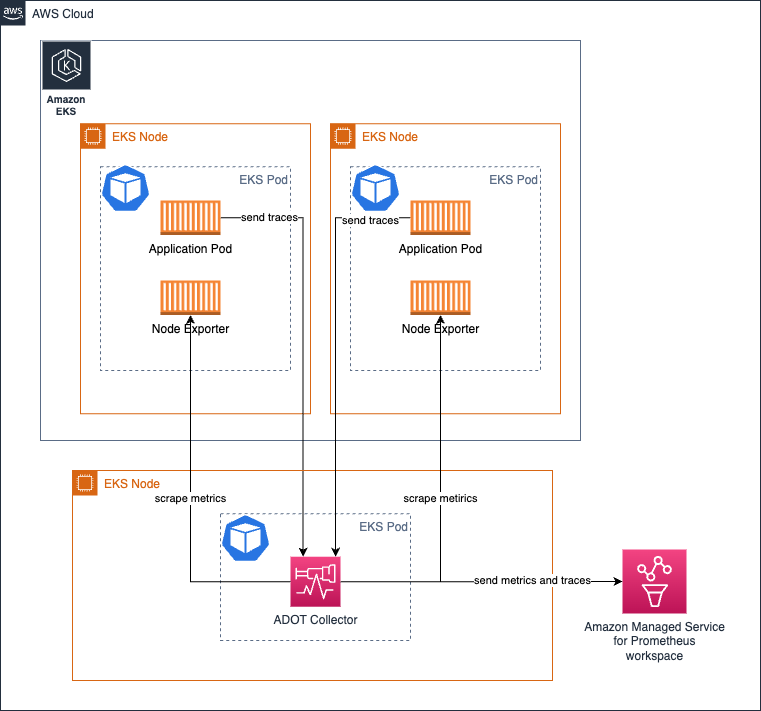
メトリクス収集の高可用性を設定するには、詳細な手順を提供するドキュメントをご覧ください
Amazon ECS でメトリクス収集のためにコレクターを中央タスクとして実行する
ECS Observer 拡張機能 を使用して、ECS クラスター内または複数のクラスター間で異なるタスクの Prometheus メトリクスを収集できます。
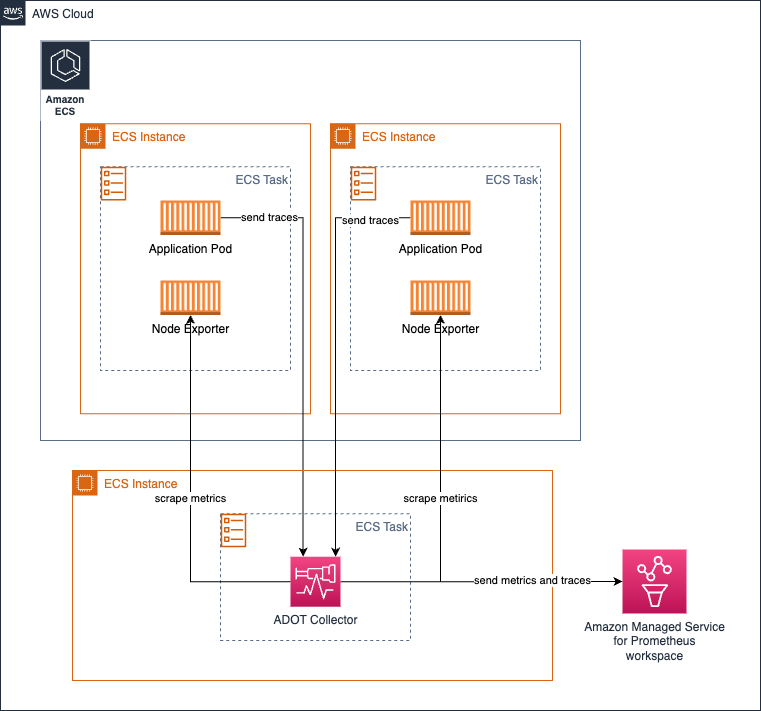
拡張機能のサンプルコレクター設定:
extensions:
ecs_observer:
refresh_interval: 60s # format is https://golang.org/pkg/time/#ParseDuration
cluster_name: 'Cluster-1' # cluster name need manual config
cluster_region: 'us-west-2' # region can be configured directly or use AWS_REGION env var
result_file: '/etc/ecs_sd_targets.yaml' # the directory for file must already exists
services:
- name_pattern: '^retail-.*$'
docker_labels:
- port_label: 'ECS_PROMETHEUS_EXPORTER_PORT'
task_definitions:
- job_name: 'task_def_1'
metrics_path: '/metrics'
metrics_ports:
- 9113
- 9090
arn_pattern: '.*:task-definition/nginx:[0-9]+'
メリッ�トとデメリット
- このモデルの利点は、自身で管理するコレクターと設定が少なくて済むことです。
- クラスターが大規模で、スクレイピング対象が数千に及ぶ場合、負荷がコレクター間で均等に分散されるようにアーキテクチャを慎重に設計する必要があります。高可用性のために同じコレクターのクローンを実行する必要があることも考慮すると、運用上の問題を避けるために慎重な検討が必要です。
Gateway
コレクターの健全性管理
OTEL コレクターは、その健全性とパフォーマンスを監視するための複数のシグナルを公開しています。以下のような是正措置を講じるために、コレクターの健全性を綿密に監視することが重要です。
- コレクターの水平スケーリング
- コレクターが期待通りに機能するための追加リソースのプロビジ�ョニング
Collector からのヘルスメトリクスの収集
OTEL Collector は、service パイプラインに telemetry セクションを追加するだけで、Prometheus Exposition Format でメトリクスを公開するように設定できます。
また、Collector は自身のログを stdout に出力することもできます。
テレメトリ設定の詳細については、OpenTelemetry のドキュメントを参照してください。
Collector のテレメトリ設定例です。
service:
telemetry:
logs:
level: debug
metrics:
level: detailed
address: 0.0.0.0:8888
設定が完了すると、Collector は http://localhost:8888/metrics で以下のようなメトリクスのエクスポートを開始します。
# HELP otelcol_exporter_enqueue_failed_spans 送信キューへの追加に失敗したスパンの数。
# TYPE otelcol_exporter_enqueue_failed_spans counter
otelcol_exporter_enqueue_failed_spans{exporter="awsxray",service_instance_id="523a2182-539d-47f6-ba3c-13867b60092a",service_name="aws-otel-collector",service_version="v0.25.0"} 0
# HELP otelcol_process_runtime_total_sys_memory_bytes OS から取得したメモリの合計バイト数 (「go doc runtime.MemStats.Sys」を参照)
# TYPE otelcol_process_runtime_total_sys_memory_bytes gauge
otelcol_process_runtime_total_sys_memory_bytes{service_instance_id="523a2182-539d-47f6-ba3c-13867b60092a",service_name="aws-otel-collector",service_version="v0.25.0"} 2.4462344e+07
# HELP otelcol_process_memory_rss 物理メモリの合計 (常駐セットサイズ)
# TYPE otelcol_process_memory_rss gauge
otelcol_process_memory_rss{service_instance_id="523a2182-539d-47f6-ba3c-13867b60092a",service_name="aws-otel-collector",service_version="v0.25.0"} 6.5675264e+07
# HELP otelcol_exporter_enqueue_failed_metric_points 送信キューへの追加に失敗したメトリクスポイントの数。
# TYPE otelcol_exporter_enqueue_failed_metric_points counter
otelcol_exporter_enqueue_failed_metric_points{exporter="awsxray",service_instance_id="d234b769-dc8a-4b20-8b2b-9c4f342466fe",service_name="aws-otel-collector",service_version="v0.25.0"} 0
otelcol_exporter_enqueue_failed_metric_points{exporter="logging",service_instance_id="d234b769-dc8a-4b20-8b2b-9c4f342466fe",service_name="aws-otel-collector",service_version="v0.25.0"} 0
上記のサンプル出力では、コレクターが otelcol_exporter_enqueue_failed_spans というメトリクスを公開しており、送信キューに追加できなかったスパンの数を示していることがわ�かります。
このメトリクスは、コレクターが設定された送信先にトレースデータを送信する際に問題が発生していないかを理解するために監視すべきものです。
この場合、使用中のトレース送信先を示す exporter ラベルの値が awsxray であることがわかります。
もう 1 つのメトリクス otelcol_process_runtime_total_sys_memory_bytes は、コレクターが使用しているメモリ量を理解するための指標です。
このメモリが otelcol_process_memory_rss メトリクスの値に近づきすぎると、コレクターがプロセスに割り当てられたメモリを使い果たしそうであることを示しています。
その場合、問題を回避するためにコレクターにより多くのメモリを割り当てるなどの対策を講じる時期かもしれません。
同様に、otelcol_exporter_enqueue_failed_metric_points という別のカウンターメトリクスがあり、リモート送信先への送信に失敗したメトリクスの数を示しています。
コレクターのヘルスチェック
コレクターは、稼働状態を確認するためのリブネスプローブを公開しています。このエンドポイントを使用して、定期的にコレクターの可用性を確認することをお勧めします。
healthcheck 拡張機能を使用して、�コレクターにエンドポイントを公開させることができます。以下に設定例を示します:
extensions:
health_check:
endpoint: 0.0.0.0:13133
完全な設定オプションについては、GitHub リポジトリ を参照してください。
❯ curl -v http://localhost:13133
* Trying 127.0.0.1:13133...
* Connected to localhost (127.0.0.1) port 13133 (#0)
> GET / HTTP/1.1
> Host: localhost:13133
> User-Agent: curl/7.79.1
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Fri, 24 Feb 2023 19:09:22 GMT
< Content-Length: 0
<
* Connection #0 to host localhost left intact
致命的な障害を防ぐための制限の設定
どの環境でもリソース(CPU、メモリ)には限りがあるため、予期せぬ状況による障害を避けるために、コレクターコンポーネントに制限を設定する必要があります。
これは特に、Prometheus メトリクスを収集するために ADOT Collector を運用する場合に重要です。 次のようなシナリオを考えてみましょう。あなたは DevOps チームに所属し、Amazon EKS クラスターでの ADOT Collector のデプロイと運用を担当しています。アプリケーションチームは、1 日のいつでも自由にアプリケーション Pod をデプロイでき、それらの Pod から公開されるメトリクスが Amazon Managed Service for Prometheus ワークスペースに収集されることを期待しています。
このパイプラインを問題なく機能させることは、あなたの責任です。この問題を解決するには、大きく分けて 2 つの方法があります:
- コレクターを無限にスケーリング(必要に応じてクラスターにノードを追加)して、この要件をサポートする
- メトリクス収集に制限を設定し、アプリケーションチームに上限を通知する
両方のアプローチにはそれぞれメリットとデメリットがあります。コストやオーバーヘッドを考慮せずに、成長し続けるビジネスニーズを完全にサポートすることを約束するのであれば、オプション 1 を選択することもできます。「クラウドは無限のスケーラビリティのためにある」という観点から、無限に成長するビジネスニーズをサポートすることは魅力的に聞こえるかもしれません。しかし、これは多くの運用上のオーバーヘッドをもたらし、無限の時間とリソース、継続的な中断のない運用を確保するための人材がない場合、より致命的な状況につ�ながる可能性があります。これは多くの場合、現実的ではありません。
より実用的で賢明なアプローチは、オプション 2 を選択することです。これは、運用の境界を明確にするために、任意の時点で上限を設定し(必要に応じて段階的に増やすことも可能)、運用の境界を明確にする方法です。
以下は、ADOT Collector で Prometheus レシーバーを使用してこれを実現する方法の例です。
Prometheus の scrape_config では、特定のスクレイプジョブに対していくつかの制限を設定できます。以下のような制限を設定できます:
- スクレイプの総ボディサイズ
- 受け入れるラベルの数を制限(この制限を超えるとスクレイプは破棄され、Collector のログで確認できます)
- スクレイプするターゲットの数を制限
- その他
利用可能なすべてのオプションは Prometheus のドキュメント で確認できます。
メモリ使用量の制限
Collector パイプラインは memorylimiterprocessor を使用するように設定�でき、プロセッサコンポーネントが使用するメモリ量を制限できます。
お客様が、大量のメモリと CPU リソースを必要とする複雑な操作を Collector に実行させたいと考えることは一般的です。
redactionprocessor、filterprocessor、spanprocessor などのプロセッサの使用は魅力的で非常に便利ですが、プロセッサは一般的にデータ変換タスクを処理し、タスクを完了するためにデータをメモリ内に保持する必要があることも覚えておく必要があります。
これにより、特定のプロセッサが Collector 全体を破壊したり、Collector が独自のヘルスメトリクスを公開するのに十分なメモリを持てなくなったりする可能性があります。
memorylimiterprocessor を使用することで、Collector が使用できるメモリ量を制限できます。
推奨される方法は、プロセッサが割り当てられたメモリをすべて使用しないように、ヘルスメトリクスの公開やその他のタスクを実行するためのバッファメモリを Collector に提供することです。
例えば、EKS Pod のメモリ制限が 10Gi の場合、memorylimitprocessor を 10Gi 未満(例えば 9Gi)に設定することで、1Gi のバッファをヘルスメトリクスの公開、レシーバー、エクスポーターのタスクなどの他の操作に使用できます。
バックプレッシャー管理
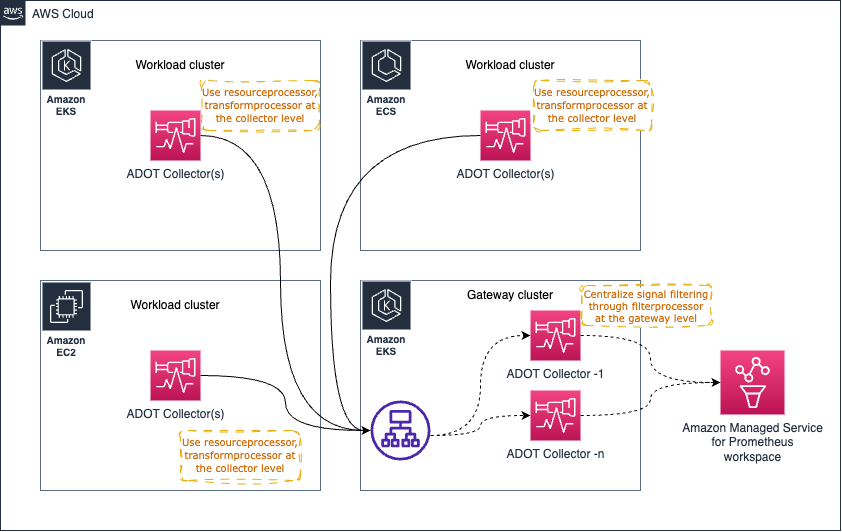
以下に示すようなアーキテクチャパターン (Gateway パターン) は、コンプライアンス要件を維持するためにシグナルデータから機密データをフィルタリングするなどの運用タスクを一元化するために使用できます。
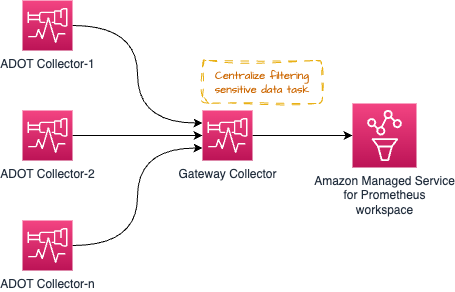
しかし、Gateway Collector に多くの 処理 タスクを集中させすぎると問題が発生する可能性があります。推奨されるアプローチは、プロセスやメモリを多く使用するタスクを個々のコレクターとゲートウェイの間で分散し、ワークロードを共有することです。
例えば、resourceprocessor を使用してリソース属性を処理し、transformprocessor を使用してシグナルの収集時に個々のコレクター内でシグナルデータを変換することができます。
その後、filterprocessor を使用してシグナルデータの特定の部分をフィルタリングし、redactionprocessor を使用してクレジットカード番号などの機密情報を編集することができます。
高レベルのアーキテクチャ図は以下のようになります:
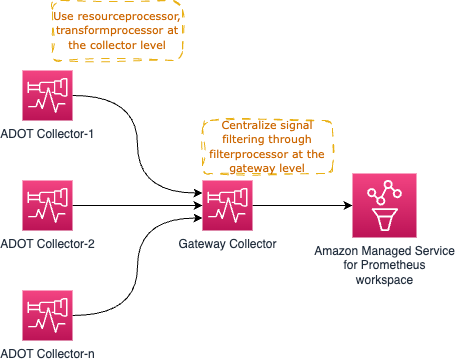
すでにお気づきかもしれませんが、Gateway Collector はすぐにシングルポイントオブフェイラーになる可能性があります。明確な選択肢の 1 つは、以下に示すように複数の Gateway Collector を起動し、AWS Application Load Balancer (ALB) などのロードバランサーを通じてリクエストをプロキシすることです。
Prometheus メトリクス収集における順序外サンプルの処理
以下のアーキテクチャにおけるシナリオを考えてみましょう:
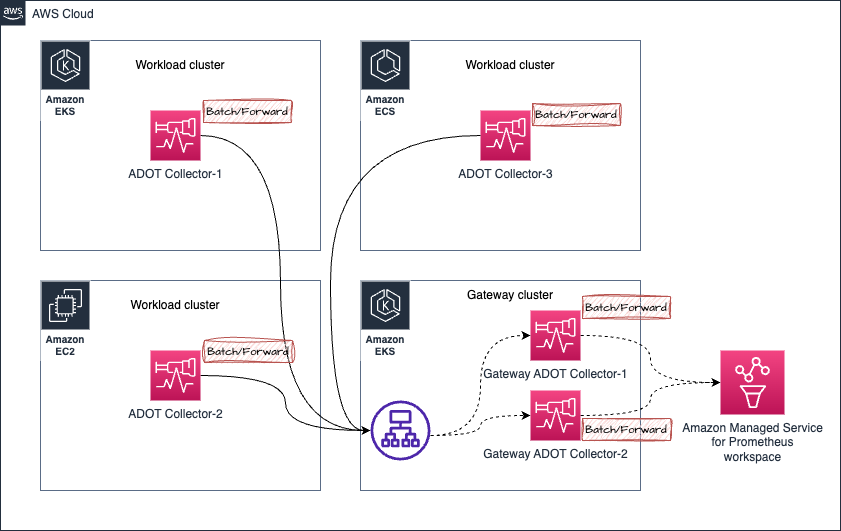
- Amazon EKS クラスター内の ADOT Collector-1 からのメトリクスが、Gateway ADOT Collector-1 に向けられているゲートウェイクラスターに送信されると仮定します。
- しばらくすると、同じ ADOT Collector-1 からのメトリクス(同じターゲットを収集しているため、同じメトリクスサンプルが扱われています)が Gateway ADOT Collector-2 に送信されます。
- ここで、Gateway ADOT Collector-2 が先に Amazon Managed Service for Prometheus ワークスペースにメトリクスを送信し、その後で同じメトリクスシリーズの古いサンプルを含む Gateway ADOT Collector-1 が送信した場合、Amazon Managed Service for Prometheus から
out of order sampleエラーが返されます。
以下にエラーの例を示します:
Error message:
2023-03-02T21:18:54.447Z error exporterhelper/queued_retry.go:394 Exporting failed. The error is not retryable. Dropping data. {"kind": "exporter", "data_type": "metrics", "name": "prometheusremotewrite", "error": "Permanent error: Permanent error: remote write returned HTTP status 400 Bad Request; err = %!w(<nil>): user=820326043460_ws-5f42c3b6-3268-4737-b215-1371b55a9ef2: err: out of order sample. timestamp=2023-03-02T21:17:59.782Z, series={__name__=\"otelcol_exporter_send_failed_metric_points\", exporter=\"logging\", http_scheme=\"http\", instance=\"10.195.158.91:28888\", ", "dropped_items": 6474}
go.opentelemetry.io/collector/exporter/exporterhelper.(*retrySender).send
go.opentelemetry.io/collector@v0.66.0/exporter/exporterhelper/queued_retry.go:394
go.opentelemetry.io/collector/exporter/exporterhelper.(*metricsSenderWithObservability).send
go.opentelemetry.io/collector@v0.66.0/exporter/exporterhelper/metrics.go:135
go.opentelemetry.io/collector/exporter/exporterhelper.(*queuedRetrySender).start.func1
go.opentelemetry.io/collector@v0.66.0/exporter/exporterhelper/queued_retry.go:205
go.opentelemetry.io/collector/exporter/exporterhelper/internal.(*boundedMemoryQueue).StartConsumers.func1
go.opentelemetry.io/collector@v0.66.0/exporter/exporterhelper/internal/bounded_memory_queue.go:61
サンプルの順序エラーの解決
この特定のセットアップでは、以下のような方法でサンプルの順序エラーを解決できます:
-
IP アドレスに基づいて、特定のソースからのリクエストを同じターゲットに転送するスティッキーロードバランサーを使用します。
詳細については、こちらのリンクを参照してください。
-
代替オプションとして、Gateway Collectors に外部ラベルを追加して、メトリクスシリーズを区別することができます。これにより、Amazon Managed Service for Prometheus はこれらのメトリクスを個別のメトリクスシリーズとして扱い、同一のものとは見なしません。
このソリューションを使用すると、Gateway Collectors の数に比例してメトリクスシリーズが増加します。これは、アクティブな時系列の制限 などの制限を超える可能性があることを意味します。
- ADOT Collector を Daemonset としてデプロイする場合:
relabel_configsを使用して、各 ADOT Collector Pod が実行されている同じノードからのサンプルのみを保持するようにしてください。詳細については、以下のリンクを参照してください。- Amazon Managed Prometheus の高度なコレクター設定 - Click to View セクションを展開し、以下のような項目を確認してください:
relabel_configs:- action: keepregex: $K8S_NODE_NAME
- ADOT Add-On の高度な設定 - ADOT Add-On for EKS の高度な設定を使用して ADOT Collector をデプロイする方法を学びます。
- ADOT Collector のデプロイ戦略 - スケールでの ADOT Collector のデプロイの異なる選択肢と、各アプローチの利点について学びます。
- Amazon Managed Prometheus の高度なコレクター設定 - Click to View セクションを展開し、以下のような項目を確認してください:
Open Agent Management Protocol (OpAMP)
OpAMP は、HTTP および WebSocket を介した通信をサポートするクライアント/サーバープロトコルです。 OpAMP は OTel Collector に実装されており、OTel Collector 自体のような OpAMP をサポートする他のエージェントを管理するためのコントロールプレーンの一部として、サーバーとして使用できます。 ここでの「管理」とは、Collector の設定の更新、ヘルスモニタリング、さらには Collector のアップグレードを行うことができることを意味します。
このプロトコルの詳細は、OpenTelemetry の公式ウェブサイトに詳しく記載されています。
水平スケーリング
ワークロードに応じて、ADOT Collector を水平方向にスケーリングする必要が生じる場合があります。 水平スケーリングの要件は、ユースケース、Collector の設定、テレメトリのスループットによって異なります。
プラットフォーム固有の水平スケーリング技術は、ステートフル、ステートレス、スクレイパーの Collector コンポーネントを意識しながら、他のアプリケーションと同様に Collector に適用できます。
ほとんどの Collector コンポーネントは stateless で、メモリ内に状態を保持せず、保持している場合でもスケーリングの目的には関係ありません。
ステートレスな Collector の追加レプリカは、アプリケーションロードバランサーの背後でスケーリングできます。
Stateful な Collector コンポーネントは、そのコンポーネントの動作に重要なメモリ内の情報を保持するコンポーネントです。
ADOT Collector のステートフルなコンポーネントの例には、以下のようなものがありますが、これらに限定されません:
- Tail Sampling Processor - 正確なサンプリングの判断を行うために、トレースのすべてのスパンが必要です。高度なサンプリングスケーリング技術は ADOT 開発者ポータルに記載されています。
- AWS EMF Exporter - 一部のメトリクスタイプで累積値からデルタ値への変換を実行します。この変換には、前回のメトリクス値をメモリに保存する必要があります。
- Cummulative to Delta Processor - 累積値からデルタ値への変換には、前回のメトリクス値をメモリに保存する必要があります。
scrapers である Collector コンポーネントは、テレメトリデータを受動的に受け取るのではなく、能動的に取得します。
現在、Prometheus receiver は ADOT Collector で唯一のスクレイパータイプのコンポーネントです。
Prometheus receiver を含む Collector 設定を水平方向にスケーリングする場合は、2 つの Collector が同じエンドポイントをスクレイプしないように、Collector ごとにスクレイピングジョブを分割する必要があります。
これを行わないと、Prometheus のサンプル順序エラーが発生する可能性があります。
Collector のスケーリングのプロセスと技術については、上流の OpenTelemetry ウェブサイトでより詳しく説明されています。