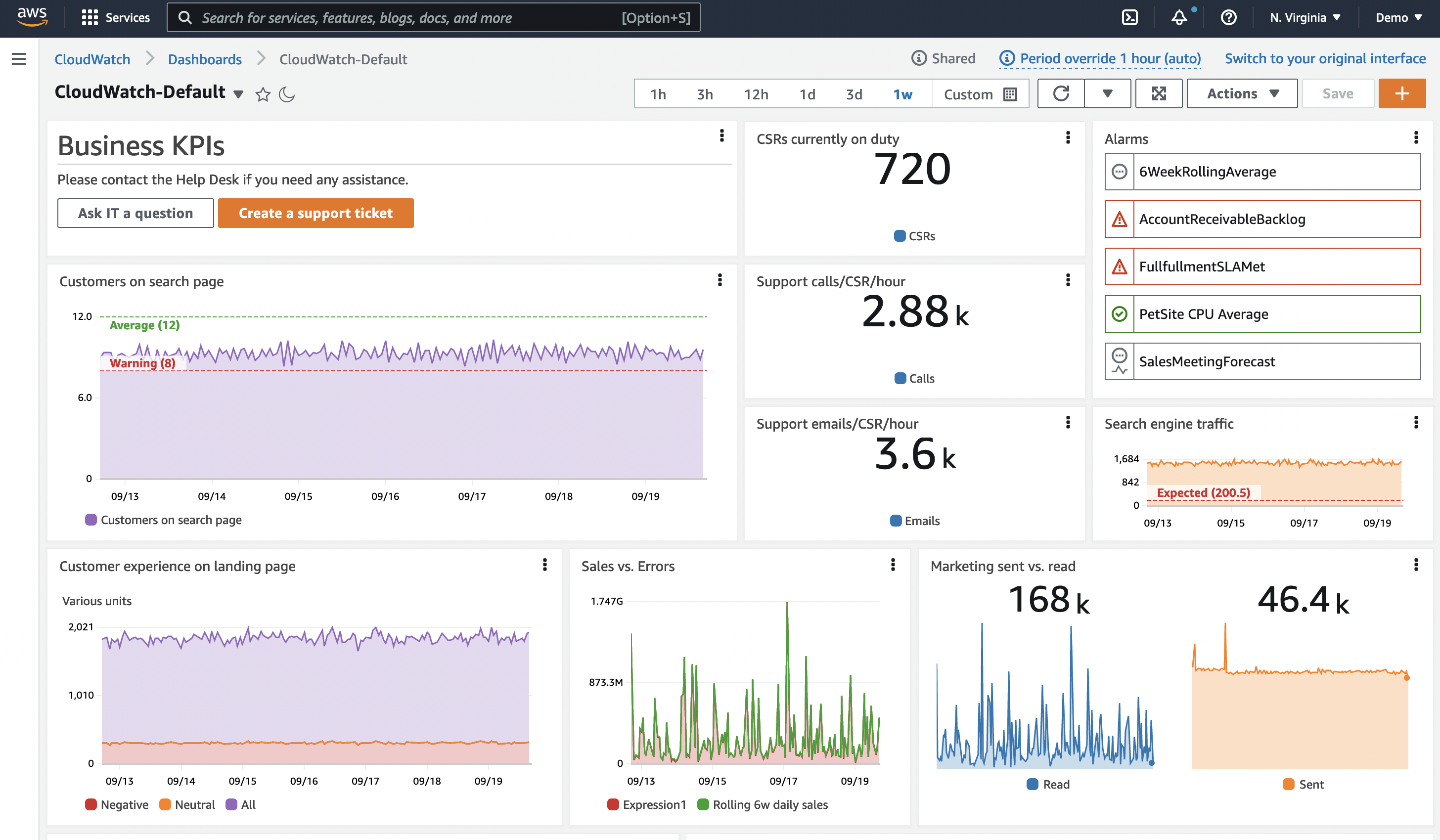
Dashboard
Dashboard 是您可观测性解决方案的重要组成部分。它们使您能够生成精心策划的数据可视化。它们让您查看数据的历史记录,并与其他相关数据一起查看。它们还允许您提供上下文信息,帮助您理解全局。
人们经常收集数据并创建告警,然后就停下来了。然而,告警只显示某个时间点的状态,通常只针对单个 metric 或少量数据。Dashboard 帮助您查看随时间变化的行为。
一个实际的例子:考虑一个高 CPU 告警
您知道机器正在以超出预期的 CPU 运行。您需要采取�行动吗?需要多快?什么可以帮助您做出决定?
- 这个实例/应用程序的正常 CPU 使用率是什么样的?
- 这是一个峰值还是 CPU 持续上升的趋势?
- 它是否影响了性能?如果没有,多久之后会影响?
- 这是一种常规现象吗?通常会自行恢复吗?
查看数据的历史记录
现在考虑一个带有 CPU 历史时间图的 dashboard。即使只有这一个 metric,您也可以看到这是一个峰值还是上升趋势。您还可以看到它上升的速度有多快,从而对行动的优先级做出一些决定。
查看对工作流的影响
但这台机器是做什么的?在我们的整体环境中,它有多重要?想象一下,我们现在添加一个工作流性能的可视化,无论是响应时间、吞吐量、错误还是其他度量。现在我们可以看到高 CPU 是否对该实例支持的工作流或用户产生了影响。
查看告警的历史记录
考虑添加一个可视化,显示上个月告警触发的频率,并结合更长时间的回顾来查看这是否是一种常规现象。例如,是否是备份任务触发了峰值?了解重复出现的模式可以帮助您理解潜在问题,并做出长期决策来完全消除告警的重复触发。
添加上下文
最后,在 dashboard 中添加一些上下文信息。包括此 dashboard 存在原因的简要描述、它相关的工作流、出现问题时该怎么做、文档链接以及联系人信息。
现在我们有了一个故事,它帮助 dashboard 用户看到正在发生什么,理解影响,并对采取什么行动及其紧迫性做出适当的数据驱动决策。
不要试图一次性可视化所有内容
我们经常谈论告警疲劳。太多告警而没有可识别的操作和优先级,可能会使您的团队超负荷并导致效率低下。告警应该针对对您重要的且可操作的事项。
Dashboard 在这方面更加灵活。它们不会像告警那样要求您的注意力,因此您有更多自由来可视化您尚不确定是否重要的内容,或者支持您的探索。不过,也不要过度!任何事情都可能因为过多而适得其反。
Dashboard 应该提供对您重要的事物的画面。��与决定要摄取什么数据一样,您需要考虑 dashboard 对您来说什么是重要的。 对于您的 dashboard,请考虑:
- 谁将查看这个?
- 他们的背景和知识是什么?
- 他们需要多少上下文信息?
- 他们试图回答什么问题?
- 他们看到这些数据后将采取什么行动?
有时候可能很难确定您的 dashboard 故事应该是什么,以及应该包含多少内容。那么您可以从哪里开始设计 dashboard 呢?让我们看看两种方式:KPI 驱动或事件驱动。
设计您的 dashboard:KPI 驱动
理解这一点的一种方法是从您的 KPI 反向推导。这通常是一种非常以用户为驱动的方法。 对于布局,通常我们从上到下工作,随着向下移动获得更多细节,或导航到更底层的 dashboard。
首先,理解您的 KPI。了解它们的含义。这将帮助您决定如何可视化这些内容。 许多 KPI 以单一数字显示。例如,成功完成特定工作流的客户百分比是多少,用了多长时间?但是在什么时间段内?如果您按一周取平均值,可能会达到 KPI,但仍有较短的时间段违反了您的标准。这些违反对您重要吗?它们是否影响了客户体验?如果是,您可以考虑不同的时间段和时间图来查看 KPI。也许不是每个人都需要看到细节,所以也许您将 KPI 的分解移到单独的 dashboard,面向不同的受众。
接下来,哪些因素贡献了这些 KPI? 哪些工作流需要运行才能使这些操作发生?您能衡量这些吗?
确定主要组件并添加其性能的可视化。当 KPI 超出阈值时,您应该能够快速查看工作流中主要影响在哪里。
您可以继续深入——什么影响了这些工作流的性能?在决定深度级别时,请记住您的受众。
考虑一个电子商务系统的例子,其 KPI 是下单数量。 为了下单,用户必须能够执行以下操作:搜索产品、添加到购物车、添加配送信息和支付订单。 对于这些工作流中的每一个,您可以考虑检查关键组件是否正常运行。例如,使用 RUM 或 Synthetics 获取操作成功的数据,查看用户是否受到问题的影响。您可以考虑测量吞吐量、延迟、失败操作百分比来查看每个操作的性能是否符合预期。您可以考虑测量底层基础设施来查看什么可能影响性能。
但是,不要把所有信息都放在同一个 dashboard 上。再次考虑您的用户受众。
创建层次化的 dashboard,允许逐级下钻并为正确的用户提供正确的上下文。
设计您的 dashboard:事件驱动
对于许多人来说,事件解决是可观测性的关键驱动力。您收到了来自用户或可观测性告警的问题通知,需要快速找到修复方案以及可能的问题根本原因。
首先查看您最近的事件。是否有共同的模式?哪些对您的公司影响最大?哪些重复发生?
在这种情况下,我们正在为那些试图理解严重性、识别根本原因和修复事件的人设计 dashboard。
回想一下具体的事件。
- 您如何验证事件是否如报告的那样?
- 您检查了什么?Endpoint?错误?
- 您如何理解影响以及问题的优先级?
- 您查看了什么来确定问题的原因?
应用程序性能监控(APM)在这里可以提供帮助,Synthetics 用于 endpoint 和工作流的常规基线测试,RUM 用于实际的客户体验。您可以使用这些数据快速可视化哪些工作流受到了影响以及影响程度。
显示错误计数随时间变化以及排名前几的错误的可视化,可以帮助您关注正确的领域,并显示错误的具体细节。这通常是我们使用日志数据以及错误代码和原因的动态可视化的地方。
在这里有某种过滤或下钻功能非常有用,可以尽快获得具体信息。考虑在不增加过多开销的情况下实现这一点。例如,拥有一个可以通过过滤获取更多细节的单一 dashboard。
布局
Dashboard 的布局也很重要。
通常,对于用户来说最重要的可视化应放在左上角,或以其他方式与页面导航的自然起始点对齐。
您可以使用布局来帮助讲述故事。例如,您可以使用从上到下的布局,向下滚动时看到更多细节。或者从左到右的显示可能很有用,左侧是更高级别的服务,向右移动时显示其依赖项。
创建动态内容
您的许多工作负载被设计为根据需求增长或缩减,您的 dashboard 需要考虑到这��一点。例如,您的实例可能在一个自动缩放组中,当达到某个负载时,会添加额外的实例。
一个通过某种 ID 指定特定实例来显示数据的 dashboard 将无法看到新实例的数据。为您的资源和数据添加元数据,这样您就可以创建可视化来捕获具有特定元数据值的所有实例。这样它们将反映实际状态。
动态可视化的另一个示例可能是能够找到当前发生的前 10 个错误,以及它们在近期历史中的表现。您希望能够在不知道可能出现哪些错误的情况下看到表格或图表。
先关注症状而非原因
当您观察症状时,您正在考虑这对用户和系统的影响。许多潜在原因可能产生相同的症状。这使您能够捕获更多问题,包括未知问题。当您了解了原因后,您的底层 dashboard 可以更具体地针对这些原因,帮助您快速诊断和修复问题。
不要捕获上周影响用户的特定 JavaScript 错误。捕获它所中断的工作流的影响,然后显示近期历史中 JavaScript 错误的排名或近期急剧增加的错误。
使用 top/bottom N
大多数时候没有必要同时可视化所有运维 metrics。大量 EC2 实例就是一个很好的例子:没有必要也没有价值同时显示数百台服务器的磁盘 IOPS 或 CPU 利用率。这会产生一个反模式,您可能会花更多时间挖掘 metrics,而不是看到性能最好(或最差)的资源。
使用您的 dashboard 显示任何给定 metric 的前 10 或 20 名,然后关注这揭示的症状。
CloudWatch metrics 允许您搜索任何时间序列的前 N 名。例如,此查询将返回 CPU 利用率最高的 20 个 EC2 实例:
SORT(SEARCH('{AWS/EC2,InstanceId} MetricName="CPUUtilization"', 'Average', 300), SUM, DESC, 10)
使用这种方法,或类似的 CloudWatch Metric Insights 来识别 dashboard 中性能最好或最差的 metrics。
使用阈值直观显示 KPI
您的 KPI 应该有警告或错误阈值,dashboard 可以使用水平注释来显示这些。这将在小部件上显示为高水位标记。直观地显示这些可以为运维人员提前预警业务成果或基础设施是否面临风险。
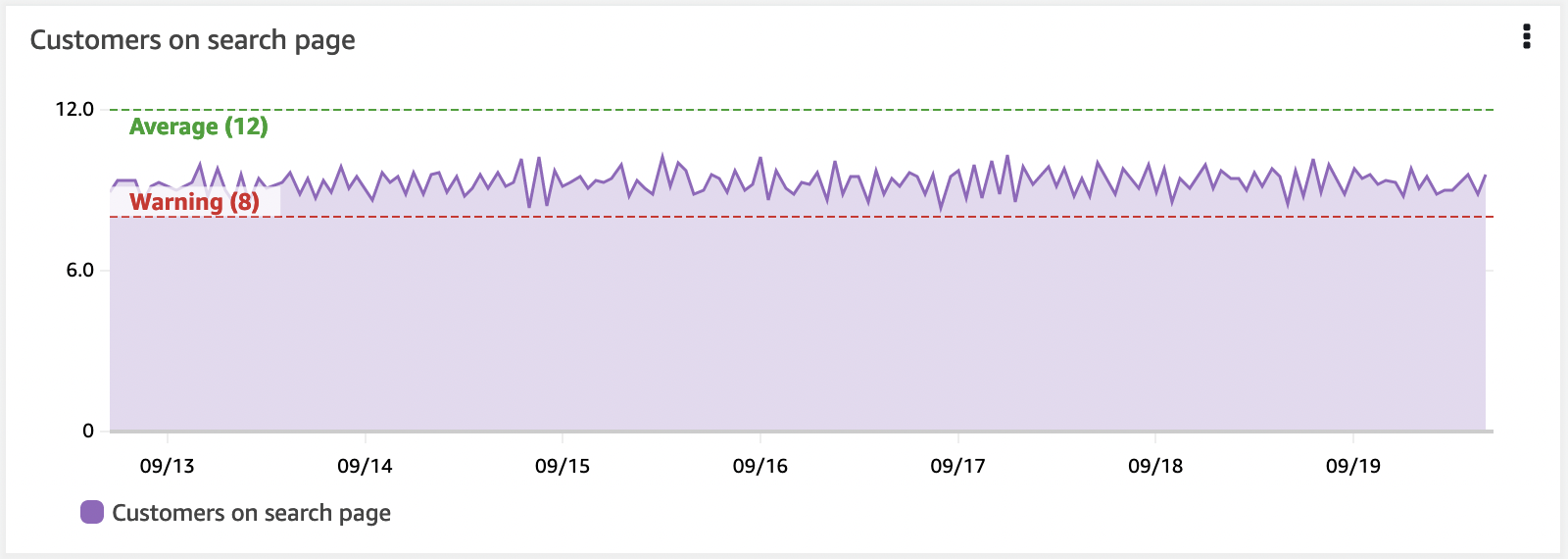
水平注释是精心设计的 dashboard 的关键部分。
上下文的重要性
人们很容易误解数据。他们的背景和当前的上下文会影响他们对数据的看法。
因此,请确保在 dashboard 中包含文本。这些数据用于什么,面向谁?它意味着什么?链接到应用程序的文档、支持人员、故障排除文档。您还可以使用文本显示来划分 dashboard 的显示区域。在左侧使用它们来设置从左到右的上下文。使用它们作为完整的水平显示来垂直划分 dashboard。
链接到 IT 支持、运维值班人员或业务负责人可以为团队提供一条快速联系能够在问题发生时提供帮助的人员的路径。
指向工单系统的超链接也是 dashboard 非常有用的补充。