ダッシュボード
ダッシュボードは、Observability ソリューションの重要な部分です。データのキュレーションされた視覚化を作成することができます。データの履歴を確認し、他の関連データと並べて表示することができます。また、コンテキストを提供することも可能です。全体像を理解するのに役立ちます。
多くの場合、データを収集してアラームを作成した後、そこで止まってしまいます。しかし、アラームは特定の時点のみを示すものであり、通常は単一のメトリクスまたは少量のデータに限られます。ダッシュボードを使用することで、時間の経過に伴う動作を確認できます。
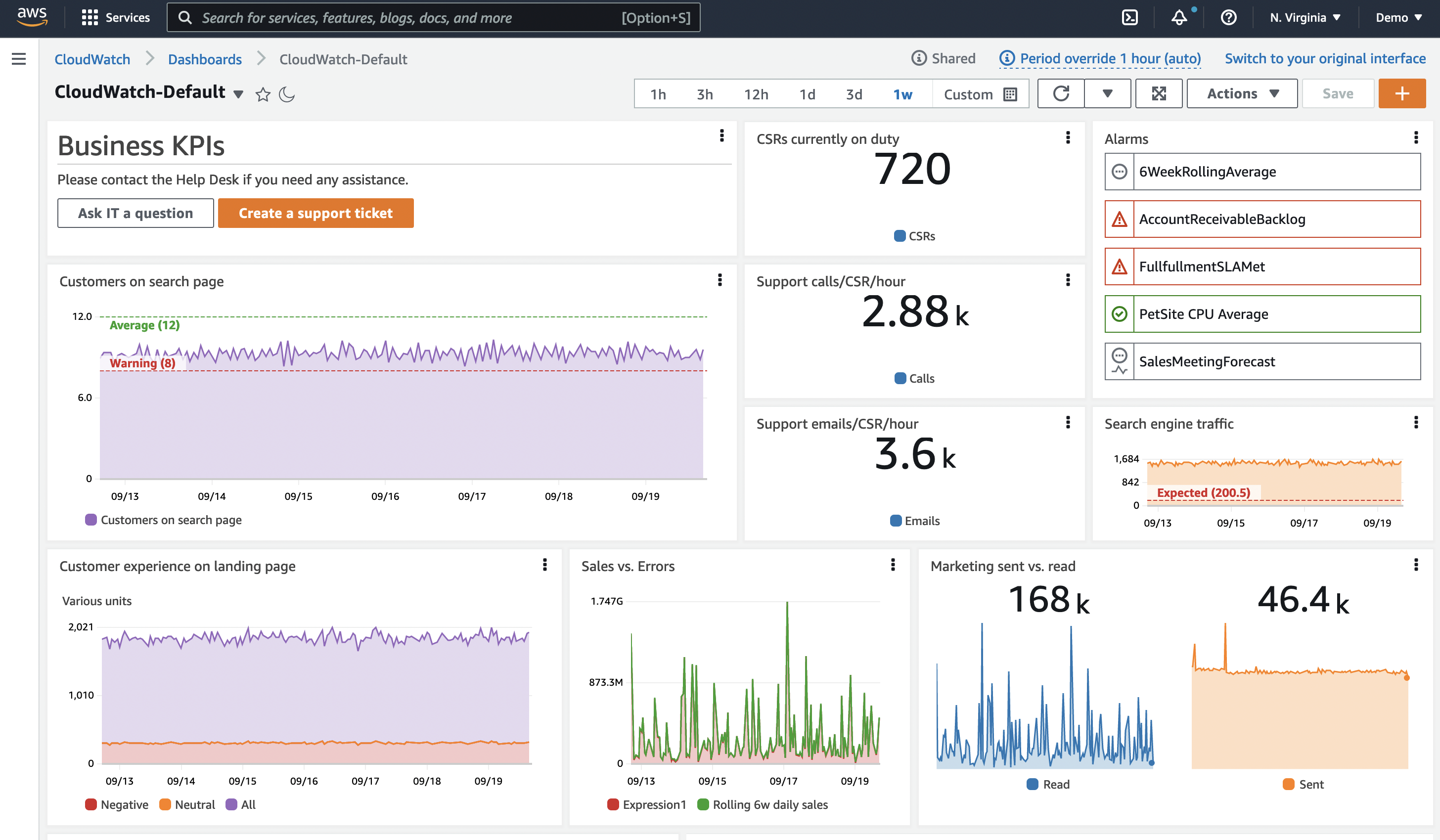
実践的な例: 高 CPU に対するアラームを考える
マシンが望ましい水準を超えた CPU で稼働していることがわかっています。対処が必要でしょうか。また、どのくらい迅速に対応すべきでしょうか?判断の助けになるものは何でしょうか?
- このインスタンス/アプリケーションにとって、通常の CPU 使用率はどのようなものですか?
- これはスパイクですか、それとも CPU が増加傾向にありますか?
- パフォーマンスに影響を与えていますか?影響がない場合、影響が出るまでどのくらいかかりますか?
- これは定期的に発生しますか?また、通常は自然に回復しますか?
データの履歴を確認する
次に、CPU の過去のタイムチャートを含むダッシュボードを考えてみましょう。この単一のメトリクスだけでも、これがスパイクなのか、それとも上昇トレンドなのかを確認できます。また、どのくらいの速さで上昇しているかも確認できるため、対応の優先度についていくつかの判断を下すことができます。
ワークフローへの影響を確認する
しかし、このマシンは何をしているのでしょうか?これは全体的なコンテキストの中でどれほど重要なのでしょうか?ワークフローのパフォーマンス(応答時間、スループット、エラー、またはその他の指標)の可視化を追加したとします。そうすることで、高い CPU 使用率がワークフローや、このインスタンスがサポートしているユーザーに影響を与えているかどうかを確認できます。
アラームの履歴を確認する
過去 1 か月間にアラームがトリガーされた頻度を示すビジュアライゼーションを追加し、それをさらに過去に遡って確認することで、これが定期的に発生しているかどうかを把握することを検討してください。たとえば、バックアップジョブがスパイクをトリガーしているのでしょうか?再発のパターンを把握することで、根本的な問題を理解し、アラームが再発しないようにするための長期的な意思決定に役立てることができます。
コンテキストを追加する
最後に、ダッシュボードにコンテキストを追加します。このダッシュボードが存在する理由の簡単な説明、関連するワークフロー、問題が発生した場合の対処方法、ドキュメントへのリンク、および連絡先を含めてください。
これで、ダッシュボードのユーザーが何が起きているかを把握し、影響を理解し、どのようなアクションを取るべきか、またその緊急性についてデータに基づいた適切な意思決定を行えるような ストーリー が完成しました。
すべてを一度に可視化しようとしないでください
アラーム疲れについてよく話題になります。識別可能なアクションや優先順位のないアラームが多すぎると、チームに過負荷をかけ、非効率につながる可能性があります。アラームは、あなたにとって重要であり、かつ対処可能なものに対して設定すべきです。
ダッシュボードはここではより柔軟です。アラートと同じように注意を要求するわけではないため、まだ重要かどうか確信が持てないものや、探索をサポートするものを可視化する自由度が高くなります。それでも、やりすぎは禁物です!良いものでも過剰になると、すべてが損なわれてしまいます。
ダッシュボードは、あなたにとって重要なものを視覚的に表示する必要があります。取り込むデータを決定する場合と同様に、ダッシュボードにとって何が重要かを考える必要があります。 ダッシュボードについては、以下の点を考慮してください。
- これは誰が閲覧しますか?
- 彼らのバックグラウンドや知識はどのようなものですか?
- どの程度のコンテキストが必要ですか?
- 彼らはどのような質問に答えようとしていますか?
- このデータを見た結果、どのようなアクションを取りますか?
ダッシュボードのストーリーをどのように構成し、何を含めるべきかを判断するのが難しい場合があります。では、ダッシュボードのデザインをどこから始めればよいでしょうか?KPI 駆動とインシデント駆動という 2 つのアプローチを見てみましょう。
ダッシュボードを設計する: KPI 主導
これを理解する一つの方法は、KPI から逆算することです。これは通常、非常にユーザー主導のアプローチです。 レイアウトについては、通常はトップダウンで作業し、ダッシュボードをさらに下に移動するか、下位レベルのダッシュボードに移動するにつれて、より詳細な情報を得ていきます。
まず、KPI を理解することが重要です。KPI が何を意味するかを把握することで、どのように可視化するかを決定しやすくなります。 多くの KPI は単一の数値として表示されます。たとえば、特定のワークフローを正常に完了している顧客の割合はどのくらいか、またそれにかかる時間はどのくらいかといった指標です。しかし、どの期間を対象にするかも重要です。1 週間の平均で KPI を達成できていても、その中に基準を下回る短い期間が存在する場合があります。そのような基準違反はあなたにとって重要ですか?顧客体験に影響を与えていますか?もしそうであれば、異なる期間や時系列チャートを使って KPI を確認することを検討してもよいでしょう。また、すべての人が詳細を確認する必要はないかもしれないため、KPI の内訳を別のオーディエンス向けの別のダッシ��ュボードに移すことも選択肢の一つです。
次に、それらの KPI に貢献するものは何ですか? それらのアクションを実現するために、どのようなワークフローが実行される必要がありますか?それらを測定できますか?
主要なコンポーネントを特定し、それらのパフォーマンスの可視化を追加します。KPI が違反した場合、ワークフローのどこに主な影響があるかをすばやく確認できるようにする必要があります。
さらに掘り下げることもできます。それらのワークフローのパフォーマンスに影響を与えるものは何でしょうか?深さのレベルを決める際には、対象読者を念頭に置いてください。
KPI として注文数を持つ e コマースシステムの例を考えてみましょう。 注文を完了するには、ユーザーが次のアクションを実行できる必要があります。商品を検索し、カートに追加し、配送先情報を入力し、注文の支払いを行います。 これらの各ワークフローについて、主要なコンポーネントが正常に機能しているかどうかを確認することを検討できます。たとえば、RUM または Synthetics を使用してアクションの成功に関するデータを取得し、ユーザーが問題の影響を受けているかどうかを確認します。スループット、レイテンシー、失敗したアクションの割合を測定して、各アクションのパフォーマンスが期待どおりかどうかを確認することも検討できます。また、パフォーマンスに影響を与えている可能性のある要因を把握するために、基盤となるインフラストラクチャの測定値を検討することもできます。
ただし、すべての情報を同じダッシュボードに配置しないようにしてください。ここでも、ユーザーオーディエンスを考慮してください。
ドリルダウンを可能にし、適切なユーザーに適切なコンテキストを提供するダッシュボードのレイヤーを作成します。
ダッシュボードを設計する: インシデント駆動型
多くの人にとって、インシデントの解決はオブザーバビリティの主要な推進力です。ユーザーまたはオブザーバビリティのアラームによって問題が通知され、迅速に修正策を見つけ、場合によっては問題の根本原因を特定する必要があります。
最近のインシデントを振り返�ることから始めましょう。共通のパターンはありますか?会社にとって最も影響が大きかったものはどれですか?繰り返し発生しているものはどれですか?
このケースでは、重大度を把握し、根本原因を特定してインシデントを修正しようとしているユーザー向けのダッシュボードを設計しています。
特定のインシデントを振り返ってください。
- インシデントが報告通りであることをどのように確認しましたか?
- 何を確認しましたか?エンドポイント?エラー?
- 問題の影響、およびその優先度をどのように把握しましたか?
- 問題の原因として何を調査しましたか?
アプリケーションパフォーマンスモニタリング (APM) は、エンドポイントとワークフローの定期的なベースラインおよびテストのための Synthetics と、実際のカスタマーエクスペリエンスのための RUM を活用することで、ここで役立ちます。このデータを使用して、どのワークフローが影響を受けているか、またその程度を迅速に可視化できます。
時間の経過に伴うエラー数や上位 # 件のエラーを表示するビジュアライゼーションは、適切な領域に集中し、エラーの具体的な詳細を確認するのに役立ちます。ここでは、ログデータやエラーコードと原因の動的なビジュアライゼーションを活用することが多いです。
フィルタリングやドリルダウンの機能を活用して、できるだけ迅速に詳細情報にアクセスできるようにすることが非常に有効です。過度なオーバーヘッドをかけず��にこれを実装する方法を検討してください。たとえば、フィルタリングによって詳細に絞り込める単一のダッシュボードを用意するといった方法が挙げられます。
レイアウト
ダッシュボードのレイアウトも重要です。
通常、ユーザーにとって最も重要なビジュアライゼーションは左上に配置するか、ページナビゲーションの自然な始まりに合わせて配置することが望ましいです。
レイアウトを活用してストーリーを伝えることができます。例えば、下にスクロールするほど詳細が表示されるトップダウンレイアウトを使用することができます。あるいは、左側に上位レベルのサービスを配置し、右に移動するにつれてその依存関係が表示される左右表示が便利な場合もあります。
動的コンテンツを作成する
多くのワークロードは、需要に応じて拡��張または縮小するように設計されており、ダッシュボードはこれを考慮する必要があります。たとえば、オートスケーリンググループにインスタンスを配置している場合、特定の負荷に達すると追加のインスタンスが追加されます。
特定の ID で指定されたインスタンスのデータを表示するダッシュボードでは、新しいインスタンスのデータを確認できません。リソースとデータにメタデータを追加することで、特定のメタデータ値を持つすべてのインスタンスをキャプチャするビジュアライゼーションを作成できます。これにより、実際の状態が反映されるようになります。
動的なビジュアライゼーションのもう一つの例として、現在発生している上位 10 件のエラーを見つけ、それらが最近の履歴においてどのように推移してきたかを確認できる機能が挙げられます。どのようなエラーが発生するかを事前に把握していなくても、テーブルやチャートで確認できるようにしたいと考えています。
原因よりも症状を先に考える
症状を観察する際には、それがユーザーやシステムに与える影響について考慮します。多くの根本的な原因が同じ症状を引き起こす可能性があります。これにより、未知の問題を含む、より多くの問題を把握できます。原因を理解するにつれて、下位レベルのダッシュボードはこれらの原因に対してより具体的になり、問題を迅速に診断して修正するのに役立ちます。
先週ユーザーに影響を与えた特定の JavaScript エラーをキャプチャするのではなく、それが中断したワークフローへの影響をキャプチャし、最近の履歴における JavaScript エラーの上位件数、または最近の履歴で急激に増加したエラーを表示してください。
上位/下位 N を使用する
ほとんどの場合、すべての運用メトリクスを同時に可視化する必要はありません。大規模な EC2 インスタンスのフリートはその良い例です。数百台のサーバーファーム全体のディスク IOPS や CPU 使用率を同時に表示する必要も価値もありません。これにより、最もパフォーマンスが高い(または低い)リソースを確認するよりも、メトリクスを掘り下げることに多くの時間を費やしてしまうというアンチパターンが生まれます。
ダッシュボードを使用して、特定のメトリクスの上位 10 件または 20 件を表示し、それによって明らかになる症状に焦点を当てます。
CloudWatch メトリクスを使用すると、任意の時系列のトップ N を検索できます。たとえば、このクエリは CPU 使用率が最も高い上位 20 件の EC2 インスタンスを返します。
SORT(SEARCH('{AWS/EC2,InstanceId} MetricName="CPUUtilization"', 'Average', 300), SUM, DESC, 10)
このアプローチ、またはCloudWatch Metric Insightsを使用した同様の方法で、ダッシュボード内のパフォーマンスが上位または下位のメトリクスを特定します。
KPI をしきい値とともに視覚的に表示する
KPI には警告またはエラーのしきい値を設定する必要があり、ダッシュボードでは水平アノテーションを使用してこれを表示できます。これはウィジェット上の高水位線として表示されます。視覚的に表示することで、ビジネス上の成果やインフラストラクチャが危険にさらされている場合に、オペレーターに事前警告を与えることができます。
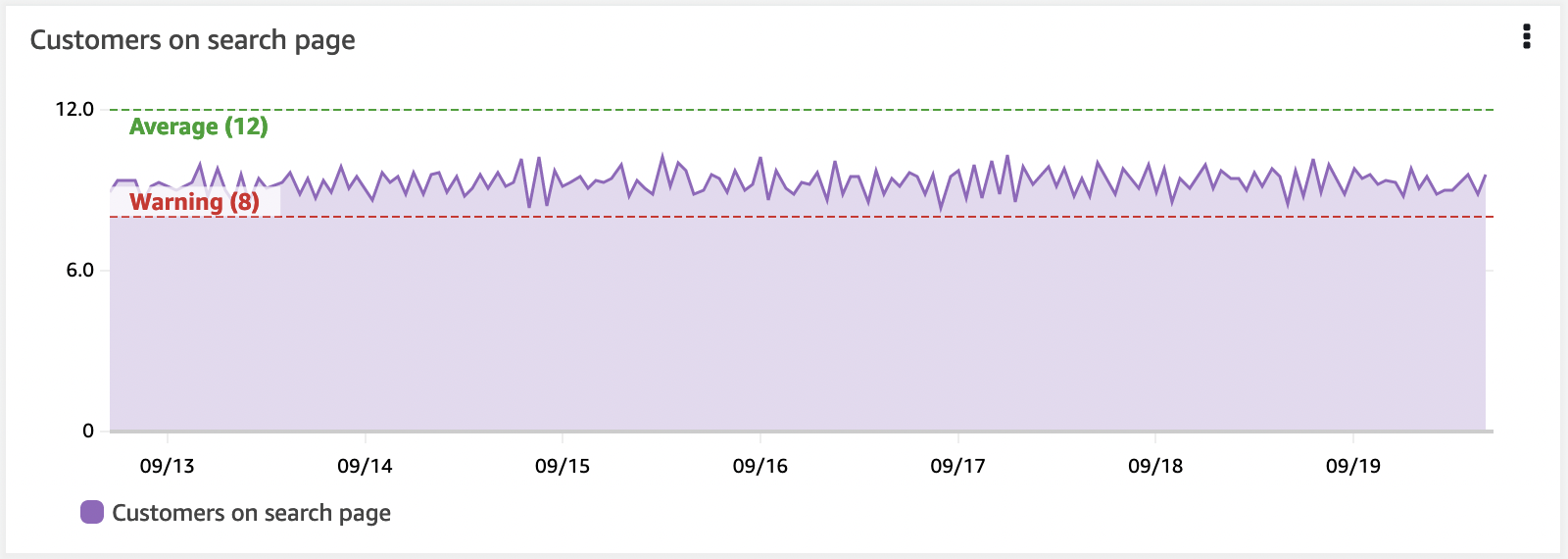
水平アノテーションは、十分に開発されたダッシュボードの重要な要素です。
コンテキストの重要性
人々はデータを誤って解釈しやすいものです。彼らの背景や現在の状況によって、データの見方が変わってきます。
ダッシュボードにテキストを含めるようにしてください。このデータは何のためのものか、誰のためのものか?それは何を意味するのか?アプリケーションに関するドキュメント、サポート担当者、トラブルシューティングドキュメントへのリンクを追加しましょう。テキスト表示を使用してダッシュボードの表示を分割することもできます。左側に配置して左右のコンテキストを設定したり、水平方向全体に表示してダッシュボードを縦に分割したりすることができます。
IT サポート、オンコールの運用担当者、またはビジネスオーナーへのリンクを設けることで、問題が発生した際にサポートを提供できる担当者に迅速に連絡できるパスをチームに提供できます。
チケットシステムへのハイパーリンクも、ダッシュボードに非常に役立つ追加機能です。