AWS에서의 GenAI Observability
개요
생성형 AI 워크로드는 기존 애플리케이션과 다른 방식으로 작동하며, 처음부터 Observability가 필수적입니다. 응답은 비결정적이고, 지연시간은 프롬프트 복잡성에 따라 극적으로 달라지며, 비용은 토큰 사용량에 직접 연결되고, 단일 에이전트 호출이 몇 초 만에 Bedrock, S3, Lambda, KMS에 걸쳐 수십 개의 API 호출을 체인할 수 있습니다.
적절한 Observability 없이 팀은 예측 가능한 문제에 직면합니다:
- 비용 초과 — 추적되지 않는 토큰 사용량이 예상치 못한 청구서로 이어집니다. 단일 폭주 에이전트 루프가 몇 분 만에 수백 달러를 소비할 수 있습니다.
- �성능 저하 — 느린 응답은 사용자 경험에 영향을 미치며, 보이지 않는 것은 고칠 수 없습니다. 모델 호출은 성공하면서 에이전트 워크플로우가 오케스트레이션 레이어에서 조용히 실패할 수 있습니다.
- 품질 격차 — 오류, 할루시네이션, 예상치 못한 출력이 사용자가 불만을 제기할 때까지 감지되지 않습니다.
- 컴플라이언스 및 감사 리스크 — 모델이 무엇을 말했는지, 어떤 파라미터를 사용했는지, 어떤 IAM 역할이 요청했는지에 대한 기록이 없습니다.
이 가이드는 AWS에서 GenAI 워크로드를 모니터링하기 위한 전략, AWS 구현, 활성화 패턴, 대시보드 설계를 안내합니다. 이 가이드는 동일한 텔레메트리를 DevOps, FinOps 및 기타 이해관계자를 위한 페르소나 기반 대시보드로 전환하는 방법을 보여주는 GenAI 텔레메트리를 위한 커스텀 대시보드 생성 가이드와 함께 사용됩니다.
GenAI Observability가 다른 이유
고유한 도전과제
비결정적 동작 — 동일한 입력이 다른 출력을 생성할 수 있습니다. 전통적인 "올바른 값을 반환했는가" 테스트는 적용되지 않습니다. 단순한 성공/실패가 아닌 품질 메트릭이 필요합니다.
가변 지연시간 — 응답 시간은 프롬프트 복잡성, 출력 길이, 모델 부하, 크로스 리전 라우팅에 따라 달라집니다. P50과 P95가 전통적인 API보다 훨씬 더 크게 벌어집니다.
토큰 기반 가격 책정 — 비용은 단순한 요청 수가 아닌 사용 패턴에 따라 확장됩니다. 평균 프롬프트 길이의 작은 증가가 월 청구서를 2배로 늘릴 수 있습니다.
멀티 서비스 복잡성 — 에이전트가 여러 AWS 서비스에 걸쳐 API 호출을 체인합니다. 단일 로그 소스로는 전체 스토리를 파악할 수 없습니다.
빠른 반복 — 모델과 프롬프트가 자주 변경됩니다. Observability는 시간에 따른 모델 버전, 프롬프트 템플릿, 구성 변경을 추적해야 합니다.
비즈니스 영향
Observability를 사후 고려사항으로 취급하는 조직은 일반적으로 사후에 이러한 패턴을 발견합니다:
- 단일 미조정 프롬프트가 월간 Bedrock 예산의 80%를 소비
- 모델 메트릭은 정상으로 보이면서 에이전트 워크플로우가 도구 레이어에서 실패
- 사전에 편집(redaction)이 구성되지 않아 PII가 로그로 유출
- 팀 태그가 적용되지 않아 비용 귀속 불가능
Observability를 일찍 올바르게 구축하면 나중의 비용이 많이 드는 개조를 방지할 수 있습니다.
GenAI를 위한 핵심 축
메트릭
"내 AI가 어떻게 수행되고 있는가?"에 답하는 운영 텔레메트리
추적해야 할 필수 메트릭:
- Token usage — 요청당 입력 토큰, 요청당 출력 토큰, 모델 및 사용자별 총 토큰, 토큰 비용 계산
- Latency — 첫 토큰까지 시간(TTFT), 총 응답 시간, P50/P95/P99 백분위수, 모델 및 리전별 지연시간
- Request volume — 초/분/시간당 요청, 성공 대 오류율, 동시 요청
- Cost — 요청당 비용, 모델/사용자/팀별 비용, 일일/월간 트렌드, 비용 효율성(달러당 출력 토큰)
로그
"내 AI가 무엇을 말했고, 누구에게?"에 답하는 콘텐츠 및 맥락
로깅해야 할 것:
- 요청/응답 쌍 (PII 편집 포함)
- 프롬프트 템플릿 및 변수
- 모델 파라미터 (temperature, max_tokens, top_p)
- 오류 메시지 및 스택 트레이스
- 사용자 컨텍스트 및 세션 ID
- A/B 테스트 변형
로그 레벨:
DEBUG— 상세 프롬프트 엔지니어링 반복INFO— 메타데이터가 포함된 성공 요청WARN— 재시도, 폴백, 속도 제한ERROR— 실패, 타임아웃, 유효하지 않은 응답
트레이스
"요청이 시스템을 어떻게 통과했는가?"에 답하는 분산 흐름
캡처해야 할 것:
- 엔드투엔드 요청 흐름
- 프롬프트 전처리 단계
- 모델 호출 스팬
- 도구 및 함수 호출 스팬
- 후처리 및 검증
- 다운스트림 서비스와의 통합
- 멀티 홉 에이전트 워크플로우
전략적 모범 사례
- 일찍 계측하세요 — 출시 후가 아닌 빌드 시에 Observability를 추가하세요. 계측이 벤더 중립적이고 이식 가능하도록 OpenTelemetry를 사용하세요.
- 다차원 태깅 — 나중에 비용과 성능을 분석할 수 있도록 모든 메트릭에
model,environment,application,team,region차원을 태깅하세요. - 알람 전에 기준선 설정 — 알람 임계값을 설정하기 전에 최소 1주일간 프로덕션에서 실행하여 정상 동작을 확립하세요. 기준선 없는 알람은 소음 피로를 유발합니다.
- 기술적 메트릭뿐 아니라 비즈니스 메트릭도 관찰 — 지연시간 및 오류율과 함께 출력 품질, 사용자 만족도(좋아요/싫어요), 기능별 비용을 추적하세요.
- 첫날부터 PII를 계획하세요 — 민감한 데이터가 저장되기 전에 로그에서 편집하세요. 자동 마스킹을 위해 CloudWatch Logs 데이터 보호 정책을 사용하세요.
- 보존 정책 설정 — 로그 볼륨은 빠르게 증가합니다. 목적별로 보존을 차별화하세요:
- 운영 로그: 7일
- 모델 호출: 30-90일
- 감사/컴플라이언스: 규제 요구사항에 따라 (종종 7년)
- 모델 버전과 프롬프트 템플릿 추적 — 무언가 변경될 때, 당시 프로덕션에 무엇이 있었는지와 상관관계를 파악해야 합니다.
AWS의 두 가지 데이터 파이프라인
Amazon CloudWatch는 두 가지 상호 보완적 데이터 파이프라인을 통해 GenAI에 대한 엔드투엔드 Observability를 제공합니다. 각각 다른 목적을 제공하고, 다른 데이터를 캡처하며, 다르게 활성화됩니다. 대부분의 프로덕션 설정에는 둘 다 필요합니다.
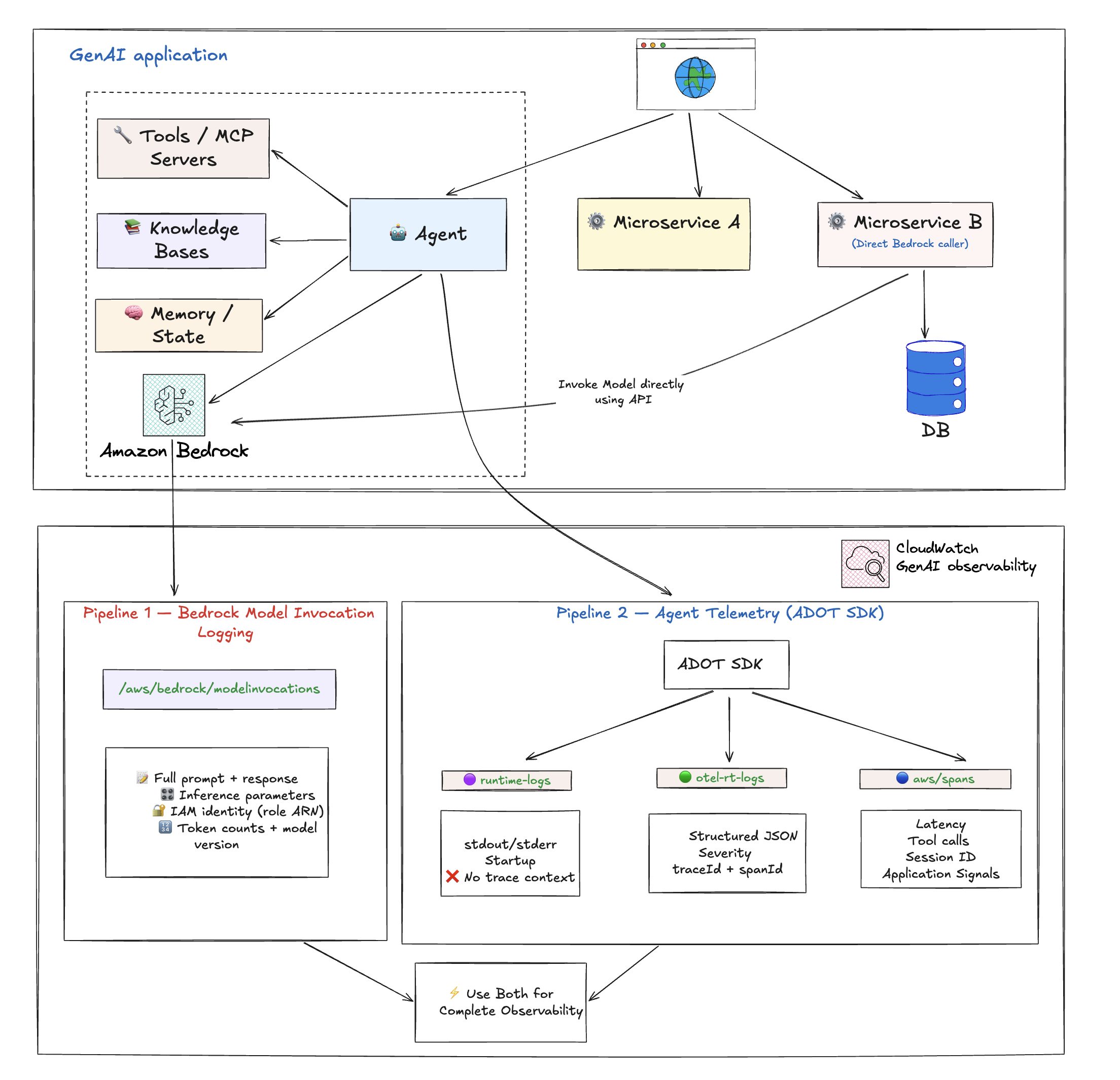
파이프라인 1: Bedrock 모델 호출 로깅
모든 모델 호��출에 대한 원시 요청과 응답을 캡처하는 Bedrock 수준의 로깅 기능입니다. 이것은 Bedrock 전용입니다 — Amazon Bedrock 파운데이션 모델에 대한 호출만 포함합니다. Bedrock이 아닌 모델(SageMaker에서 자체 호스팅, 외부 프로바이더)을 사용하는 경우 이 파이프라인은 적용되지 않습니다.
캡처하는 것:
| 필드 | 중요한 이유 |
|---|---|
| 전체 요청 페이로드 | 시스템 프롬프트와 메시지 기록을 포함하여 모델에 전송된 내용을 정확히 확인 |
| 전체 응답 페이로드 | 모델이 반환한 내용을 그대로 확인 |
추론 파라미터 (temperature, max_tokens, top_p) | 예상치 못한 모델 동작 디버그 — temp 0.7로 호출됐는지 0.0으로 호출됐는지? |
| 호출자 IAM 아이덴티티 (역할 ARN) | 보안 감사, 팀/역할별 비용 귀속 |
| Bedrock 오퍼레이션 유형 | InvokeModel, Converse, ConverseStream |
| 모델 버전 | 접미사를 포함한 정확한 모델 ID (예: cohere.command-r-plus-v1:0) |
| 토큰 수 | 콘텐츠에 직접 연결된 입력 및 출력 토큰 수 |
캡처하지 않는 것:
- 에이전트 오케스트레이션 흐름 (어떤 도구가 호출됐는지, 에이전트 루프 동작)
- 클라이언트 측 지연시간
- 분산 트레이스 상관관계 (traceId/spanId 없음 — requestId만 있음)
- 도구 호출 세부사항
- 인프라 컨텍스트
- Bedrock이 아닌 모델 호출
샘플 로그 항목:
{
"timestamp": "2026-04-17T14:21:50Z",
"accountId": "123456789012",
"region": "us-east-1",
"requestId": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"operation": "InvokeModel",
"modelId": "cohere.command-r-plus-v1:0",
"input": {
"inputBodyJson": {
"message": "Write a short joke about software engineers.",
"max_tokens": 256,
"temperature": 0.7
},
"inputTokenCount": 8
},
"output": {
"outputBodyJson": {
"text": "Why did the engineer break up? Because they couldn't commit.",
"finish_reason": "COMPLETE"
},
"outputTokenCount": 20
},
"identity": {
"arn": "arn:aws:sts::123456789012:assumed-role/my-bedrock-role/my-session"
},
"schemaType": "ModelInvocationLog"
}
활성화 방법:
Amazon Bedrock 콘솔(또는 API)을 통한 수동 옵트인입니다. 모델이 에이전트, 직접 API 호출, SDK 또는 다른 방법으로 호출되든 동일한 단계입니다. 활성화되면 모든 Bedrock 모델 호출에 계정 전체에 적용됩니다.
- Amazon Bedrock 콘솔을 엽니다
- Settings를 선택합니다
- Model invocation logging에서 Model invocation logging을 선택합니다
- 로그에 포함할 필수 데이터 유형을 선택합니다. CloudWatch Logs로만 전송하거나 Amazon S3와 CloudWatch Logs 모두에 전송하도록 선택합니다.
- CloudWatch Logs 구성에서 로그 그룹 이름을 생성하고 적절한 서비스 역할을 선택합니다
- Save settings를 선택합니다
자세한 내용은 Model Invocations 및 Set up a CloudWatch Logs destination을 참조하세요.
사전 구성된 대시보드:
모델 호출 로깅을 활성화하면 CloudWatch는 자동으로 다음을 보여주는 대시보드를 제공합니다:
- 호출 수 — Converse, ConverseStream, InvokeModel, InvokeModelWithResponseStream API에 대��한 성공한 요청 수
- 호출 지연시간 — 호출의 지연시간
- 모델별 토큰 수 — 모델별 입력 및 출력 토큰 수
- 모델 ID별 일일 토큰 수 — 모델 ID별 일일 총 토큰 수
- 입력 토큰별로 그룹화된 요청 — 토큰 범위로 그룹화된 요청 수
- 호출 스로틀 — 스로틀된 호출 수
- 호출 오류 수 — 오류가 발생한 호출 수
파이프라인 2: 에이전트 텔레메트리 (ADOT SDK 통해)
AWS Distro for OpenTelemetry (ADOT) SDK가 캡처하는 OpenTelemetry 기반 트레이스, 스팬, 로그입니다. 모델 호출 로깅과 달리 에이전트 텔레메트리는 Bedrock뿐만 아니라 모든 모델 프로바이더(Bedrock, SageMaker, 외부)와 작동합니다.
캡처하는 것:
- 에이전트 오케스트레이션 흐름 — 어떤 도구가 호출됐는지, 어떤 순서로, 에이전트 루프 반복
- 모델 호출 메타데이터 — 모델 ID, 토큰 수(입력/출력), 지연시간, 상태 코드, 종료 사유
- 도구 실행 세부사항 — 모든 도구 호출의 도구 이름, 기간, 성공/실패
- 분산 트레이스 상관관계 — 전체 엔드투엔드 요청 추적을 위한 traceId, spanId, parentSpanId
- 세션 �추적 — session.id가 여러 호출을 단일 사용자 세션에 연결
- 플랫폼 및 환경 컨텍스트 — cloud.platform, deployment.environment, 서비스 메타데이터
캡처하지 않는 것:
- 추론 파라미터 (temperature, max_tokens, top_p)
- 호출자 IAM 아이덴티티
- 기본적으로 전체 프롬프트/응답 콘텐츠 (프레임워크에 따라 다름 — Strands, LangChain, CrewAI 등은 지원됨; 다른 프레임워크는 다를 수 있음)
샘플 모델 호출 스팬 (aws/spans):
{
"resource": {
"attributes": {
"deployment.environment.name": "bedrock-agentcore:default",
"service.name": "MyAgent.DEFAULT",
"cloud.platform": "aws_bedrock_agentcore",
"telemetry.sdk.version": "1.40.0"
}
},
"traceId": "a1b2c3d4e5f6a7b8c9d0e1f2a3b4c5d6",
"spanId": "1a2b3c4d5e6f7a8b",
"parentSpanId": "9c8d7e6f5a4b3c2d",
"name": "chat us.anthropic.claude-sonnet-4-6",
"durationNano": 2644916837,
"attributes": {
"gen_ai.request.model": "us.anthropic.claude-sonnet-4-6",
"gen_ai.usage.input_tokens": 1980,
"gen_ai.usage.output_tokens": 119,
"gen_ai.response.finish_reasons": ["tool_use"],
"http.response.status_code": 200,
"session.id": "session-a1b2c3d4-e5f6-7890"
}
}
샘플 도구 실행 스팬 (aws/spans):
{
"traceId": "a1b2c3d4e5f6a7b8c9d0e1f2a3b4c5d6",
"spanId": "2b3c4d5e6f7a8b9c",
"parentSpanId": "d4e5f6a7b8c9d0e1",
"name": "execute_tool http_request",
"durationNano": 37505594,
"attributes": {
"gen_ai.tool.name": "http_request",
"gen_ai.tool.status": "success",
"gen_ai.system": "strands-agents"
}
}
데이터가 저장되는 위치:
| 로그 그룹 | 포함 내용 |
|---|---|
aws/spans | OTel 트레이스 스팬 — 모델 호출, 도구 실행, 에이전트 루프 반복 |
/aws/bedrock-agentcore/runtimes/<agent> (runtime-logs) | 애플리케이션 stdout/stderr — 시작 로그, 오류, 커스텀 앱 로깅 |
/aws/bedrock-agentcore/runtimes/<agent> (otel-rt-logs) | 에이전트 프레임워크의 OTel 로그 레코드 (지��원되는 프레임워크의 프롬프트/응답 콘텐츠) |
CloudWatch에서 구동하는 기능:
- Application Signals 대시보드 — 지연시간 백분위수, 오류율, 처리량
- Application Maps — 에이전트 → 모델 → 도구 호출 체인 시각화
- 분산 트레이싱 — 서비스 간 엔드투엔드 요청 추적
- SLO 모니터링
- 트레이스 분석 — 개별 요청을 엔드투엔드로 드릴다운
- 인프라 메트릭과의 상관관계
활성화 방법:
| 배포 모델 | 수행 작업 |
|---|---|
| Bedrock AgentCore | 없음 — ADOT SDK가 런타임에 내장되어 있습니다. 텔레메트리가 자동으로 흐릅니다. |
| Non-AgentCore (EKS/ECS/자체 호스팅) | ADOT 자동 계측 에이전트를 연결합니다. 코드 변경이 필요 없습니다. |
나란히 비교
| 알고 싶은 것 | 모델 호출 로깅 (Bedrock 전용) | 에이전트 텔레메트리 (ADOT) |
|---|---|---|
| 어떤 모델이 호출됐는가? | ✅ | ✅ |
| 지연시간 / 기간? | ❌ | ✅ (클라이언트 측) |
| 토큰 수? | ✅ | ✅ |
| 오류율 / 상태? | ✅ | ✅ |
| 에이전트 오케스트레이션 흐름? | ❌ | ✅ |
| 도구 호출 세부사항? | ❌ | ✅ |
| 전체 프롬프트 텍스트? | ✅ | 프레임워크에 따라 ��다름 |
| 전체 모델 응답? | ✅ | 프레임워크에 따라 다름 |
| 추론 파라미터? | ✅ | ❌ |
| 호출자 IAM 아이덴티티? | ✅ | ❌ |
| 분산 트레이스 상관관계? | ❌ | ✅ |
| 비에이전트 Bedrock 호출에 작동? | ✅ | ❌ |
| Bedrock이 아닌 모델에 작동? | ❌ (Bedrock 전용) | ✅ |
| Application Signals / Application Maps? | ❌ | ✅ |
파이프라인 2의 프롬프트/응답 콘텐츠 캡처는 에이전트 프레임워크의 OTel 계측에 따라 다릅니다. Strands, LangChain, CrewAI는 지원됩니다. 다른 프레임워크는 다를 수 있습니다.
요약: 에이전트 텔레메트리는 에이전트가 어떻게 수행되고 있는지를 알려줍니다. 모델 호출 로깅은 모델이 무엇을 말하고 누가 질문하는지를 알려줍니다. 완전한 Observability를 위해 둘 다 활성화하세요.
에이전틱 워크로드를 위한 Observability 활성화
시작하기 전에 전체 GenAI Observability 경험을 잠금 해제하기 위해 CloudWatch Transaction Search를 활성화하세요.
AgentCore Runtime 호스팅 에이전트
AgentCore Runtime은 동적 AI 에이전트와 도구를 배포하고 확장하기 위해 전용으로 구축된 안전하고 서버리스 런타임입니다. LangGraph, CrewAI, Strands Agents를 포함한 모든 오픈소스 프레임워크, 모든 프로토콜, 모든 모델을 지원합니다.
Observability가 내장되어 있습니다 — ADOT SDK가 AgentCore 런타임에 포함되어 있습니다. 메트릭이 자동으로 생성되고, 코드 변경 없이 트레이스가 흐릅니다.
비-AgentCore 호스팅 에이전트 (EKS, ECS, 자체 호스팅)
AgentCore 외부에서 에이전트를 호스팅하고 한 곳에서 엔드투엔드 모니터링을 위해 Observability 데이터를 CloudWatch로 가져올 수 있습니다. 워크로드에 ADOT 자동 계측 에이전트를 연결하세요 — 코드 변경이 필요 없습니다.
AgentCore memory, gateway, 및 내장 도구 리소스
AgentCore 모듈러 서비스의 메트릭과 트레이스에 대한 가시성을 확보하세요. CloudWatch Observability 구성을 참조하세요.
AgentCore Evaluations
AgentCore Evaluations는 AI 에이전트의 성능, 품질, 신뢰성을 모니터링하고 평가하는 기능을 제공합니다. AgentCore evaluations를 참조하세요.
활성화 요약
| 컴포넌트 | AgentCore | Non-AgentCore (EKS/ECS) |
|---|---|---|
| 메트릭 | 자동 | ADOT 자동 계측 에이전트 |
| 에이전트 트레이스 및 스팬 | 자동 (ADOT 내장) | ADOT 자동 계측 에이전트 |
| 모델 호출 로깅 | Bedrock 콘솔을 통한 수동 옵트인 | Bedrock 콘솔을 통한 수동 옵트인 |
양쪽 경로 모두에서 수동 옵트인이 진정으로 필요한 유일한 것은 모델 호출 로깅입니다. 나머지는 모두 자동이거나 ADOT 자동 계측 에이전트를 연결하여 처리됩니다.
민감한 데이터 보호
모델 호출을 로깅할 때, 프롬프트와 응답에 PII나 민감한 정보가 포함될 수 있습니다. Amazon CloudWatch Logs는 머신 러닝과 패턴 매칭을 사용하여 민감한 데이터를 식별하고 마스킹하는 데이터 보호 정책을 제공합니다.
두 가지 수준에서 데이터 보호를 구성할 수 있습니다:
계정 수준 데이터 보호
- Amazon CloudWatch 콘솔을 엽니다
- 탐색 창에서 Settings를 선택합니다
- Logs 탭을 선택합니다
- Configure the Data protection account policy를 선택합니다
- 데이터에 관련된 데이터 식별자를 지정합니다 (관리형 또는 커스텀)
- (선택사항) 감사 결과의 대상을 선택합니다 (CloudWatch Logs, Firehose, 또는 S3)
- Activate data protection을 선택합니다
로그 그룹 수준 데이터 보호
- Amazon CloudWatch 콘솔을 엽니다
- 탐색 패널에서 Logs, Log Management를 선택합니다
- Log groups 탭을 선택하고, 로그 그룹(예:
aws/bedrock/modelinvocations)을 선택한 후 Create data protection policy를 선택합니다 - 데이터에 관련된 데이터 식별자를 지정합니다
- (선택사항) 감사 결과의 대상을 선택합니다
- Activate data protection을 선택합니다
자세한 내용은 Protecting sensitive log data with masking 및 Protect sensitive data를 참조하세요.
언제 무엇을 활성화할 것인가
| 시나리오 | 모델 호출 �로깅 | 에이전트 텔레메트리 (ADOT) |
|---|---|---|
| 에이전트 없이 Bedrock 사용 (직접 API) | ✅ 유일한 옵션 | ❌ 해당 없음 |
| 모든 LLM 상호작용의 컴플라이언스/감사 추적 | ✅ 필수 | 있으면 좋음 |
| 프롬프트 품질 또는 예상치 못한 모델 출력 디버깅 | ✅ 필수 (추론 파라미터 + 콘텐츠) | 컨텍스트에 도움 |
| 팀/역할별 비용 귀속 | ✅ 필수 (IAM 아이덴티티) | ❌ 불가능 |
| 평가/파인튜닝 파이프라인 구축 | ✅ 필수 (구조화된 콘텐츠) | 프레임워크에 따라 다름 |
| 에이전트 실행, 운영 대시보드 원함 | 있으면 좋음 | ✅ 필수 |
| 지연시간/오류 모니터링만 | 불필요 | ✅ 충분 |
대시보드 구축
두 파이프라인이 모두 흐르면 다양한 대상을 위한 대시보드를 구축할 수 있습니다. 바로 사용할 수 있는 쿼리는 GenAI 텔레메트리를 위한 커스텀 대시보드 생성 가이드를 참조하세요.
대상별 대시보드 계층
경영진 대시보드 — 상위 KPI:
- 일일 총 비용
- 요청 볼륨 트렌드
- 오류율
- 사용량 기준 상위 모델
DevOps 대시보드 — 실시간 모니터링:
- 종료 사유 분류 (end_turn vs tool_use vs max_tokens)
- 완료율 대 잘림 트렌드
- 에이전트 트레이스 대 오류 (시간별)
- 스팬 오류 드릴다운
- 컴포넌트 성능 분석 (P50/P95/P99)
- 크로스 리전 추론 지연시간
FinOps 대시보드 — 비용 관리:
- 총 지출 (시간별, 일별, 월별)
- 모델별 비용 분포
- 역할/사용자별 상위 10 지출자
- 입력 대 출력 비용 분할
- 프롬프트 캐싱 기회
- 이상 탐지가 포함된 일일 비용 트렌드
개발자 대시보드 — 디버깅 및 최적화:
- 요청 트레이스
- 기능별 토큰 사용량
- 지연시간 분석
- 스택 트레이스가 포함된 오류 상세
- 토큰 효율성 (높은 입력, 낮은 출력 낭비 감지)
샘플 DevOps 쿼리: 완료율
성공적 완료 대 잘린 응답의 시간별 비율을 추적합니다. 95% 이상의 완료율을 목표로 하세요.
fields @timestamp, modelId,
output.outputBodyJson.stopReason as stop_reason
| filter schemaType = "ModelInvocationLog"
| filter ispresent(output.outputBodyJson.stopReason)
| stats sum(stop_reason = "end_turn" or stop_reason = "tool_use") as ok,
sum(stop_reason = "max_tokens") as truncated
by bin(@timestamp, 1h) as hour
| sort hour desc
샘플 FinOps 쿼리: 역할별 상위 지출자
SOURCE "bedrock-model-invocation-logging"
| filter @logStream = 'aws/bedrock/modelinvocations'
| fields replace(`identity.arn`, "arn:aws:sts::ACCOUNT_ID:assumed-role/", "") as userRole
| stats sum(totalCostUSD) as spend, count(*) as invocations
by userRole
| sort spend desc
| limit 10
전체 비용 계산 및 더 많은 예시는 대시보드 쿼리 가이드를 참조하세요.
알림 전략
긴급도와 영향에 맞는 단계별 알림을 설정하세요.
긴급 알림 (즉시 호출)
- 오류율 5% 초과
- P95 지연시간 10초 초과
- 일일 비용이 기준선의 150% 초과
- 모델 사용 불가
- 에이전트 오류율이 15분간 10% 초과
경고 알림 (업무 시간 중 조사)
- 토큰 사용량이 주간 대비 20% 증가 추세
- 7일간 지연시간 저하
- 캐시 히트율 감소
- 비정상적인 요청 패턴
- 완료율이 2시간 동안 95% 미만
- 컴포넌트 P95가 5000ms 초과
정보성 알림 (일일 요약)
- 일일 비용 요약
- 주간 사용 보고서
- 모델 성능 비교
- 상위 지출자 보고서
알림 라우팅 예시
route:
group_by: ['alertname', 'cloud_provider']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'default'
routes:
- match:
severity: critical
receiver: 'pagerduty'
- match:
severity: warning
receiver: 'slack-ops'
- match:
alertname: MonthlyBudgetExceeded
receiver: 'slack-finops'
Observability 성숙도 모델
레벨 1: 기본 모니터링
- 요청 수와 오류 추적
- 기본 지연시간 메트릭
- 수동 비용 추적
레벨 2: 포괄적 메트릭
- 토큰 수준 추적
- 다차원 메트릭 (모델, 팀, 환경)
- 자동화된 대시보드
- 기준선을 활용한 기본 알림
레벨 3: 고급 분석
- 에이전트 워크플로우 간 분산 트레이싱
- 팀/기능별 비용 귀속
- 품질 점수 및 사용자 피드백 통합
- 트렌드 기반 예측 알림
레벨 4: AI 기반 Observability
- 비용 및 동작에 대한 이상 탐지
- 자동화된 근본 원인 분석
- 자가 치유 시스템 (더 저렴한 모델로 자동 폴백)
- 지속적 최적화 루프
MLOps와의 통합
Observability는 프로덕션뿐만 아니라 ML 수명 주기 전체에 걸쳐 확장되어야 합니다:
학습 단계:
- 학습 비용 및 기간 추적
- 모델 품질 메트릭 모니터링
- 모델 및 프롬프트의 버전 관리
배포 단계:
- 메트릭 비교�를 통한 카나리 배포
- Blue-green 배포 모니터링
- Observability 신호 기반 롤백 트리거
프로덕션 단계:
- 지속적 모니터링
- 드리프트 감지 기반 자동 재학습 트리거
- 성능 저하 감지
최적화 단계:
- 프롬프트 및 모델을 위한 A/B 테스트 프레임워크
- 비용-성능 트레이드오프 분석
- 프롬프트 엔지니어링 피드백 루프
피해야 할 일반적인 안티패턴
- PII 편집 없이 전체 프롬프트와 응답 로깅 — 컴플라이언스 위반, 데이터 유출 위험. 모델 호출 로깅을 활성화하기 전에 데이터 보호 정책을 구성하세요.
- 집계 메트릭만 추적 — 요청별 세부사항 없이는 개별 문제를 디버그하거나 비용을 귀속할 수 없습니다.
- 기준선 없이 알림 설정 — 오탐으로 인한 알림 피로. 항상 정상 동작을 먼저 확립하세요.
- 청구서가 올 때까지 토큰 사용량 무시 — 청구서를 볼 때는 이미 손해가 발생했습니다. 매일 모니터링하세요.
- 프로바이더별 다른 메트릭 이름 사용 — 모델 간 성능을 비교할 수 없습니다. OpenTelemetry GenAI 시맨틱 컨벤션으로 표준화하세요.
- 텔레메트리 데이터를 무기한 저장 — 컴플라이언스 문제 및 불필요한 스토리지 비용. 데이터 클래스별 보존 정책을 설정하세요.
- 수동 대시보드 생성 — 불일치 및 유지보수 부담. 대시보드에 Infrastructure as Code를 사용하세요.
- 기술적 메트릭만 모니터링 — 품질 및 비즈니스 영향 문제를 놓칩니다. 지연시간과 함께 사용자 만족도를 추적하세요.
시작 체크리스트
프로덕션 전
- CloudWatch Transaction Search 활성화
- AgentCore의 경우: 에이전트 배포 — 텔레메트리가 자동으로 흐릅니다
- 비-AgentCore의 경우: ADOT 자동 계측 에이전트 연결
- Bedrock 콘솔을 통해 Bedrock 모델 호출 로깅 활성화
- PII 편집을 위한 데이터 보호 정책 구성
- 각 로그 그룹에 대한 로그 보존 정책 설정
- 대시보드 쿼리 가이드를 사용하여 초기 대시보드 구축
- �기준선 메트릭 문서화 (지연시간, 토큰 사용량, 비용)
- 적절한 임계값으로 알람 구성
- 일반적인 문제에 대한 런북 작성
프로덕션
- 프로덕션에서 모니터링 활성화
- 올바른 채널로 알림 라우팅 (PagerDuty, Slack)
- 팀 접근 구성 (이해관계자를 위한 읽기 전용 대시보드)
- 백업 및 재해 복구 테스트
- 정기 검토 일정 수립 (주간 비용 검토, 월간 성능 검토)
추가 리소스
관련 가이드
- GenAI 텔레메트리를 위한 커스텀 대시보드 생성 — 텔레메트리를 DevOps, FinOps 및 기타 이해관계자를 위한 페르소나 기반 대시보드로 전환
AWS 문서
- Model Invocations — CloudWatch GenAI Observability
- Getting Started with AgentCore Observability
- Set up Bedrock Model Invocation Logging
- Protect Sensitive Data in CloudWatch Logs
- Configure Custom Observability for AgentCore
- Configure Third-Party Observability
- AgentCore Evaluations
표준 및 도구
- AWS Distro for OpenTelemetry (ADOT)
- OpenTelemetry GenAI Semantic Conventions
- OpenTelemetry Specification
기여자: AWS Observability Team 최종 업데이트: 2026-04-21