GenAI 텔레메트리를 위한 커스텀 대시보드 생성
왜 커스텀 대시보드인가?
Bedrock 모델 호출 로깅을 활성화하고 ADOT 자동 계측 에이전트를 배포하면, AWS는 기본 제공 대시보드로 시작점을 제공합니다. Bedrock은 자동으로 호출 수, 지연시간, 토큰 수, 스로틀 메트릭을 제공합니다. Application Signals는 서비스 맵과 SLO 뷰를 자동 생성합니다. 이것은 견고한 기반이지만 전체 그림은 아닙니다.
기본 제공 대시보드는 "지금 내 AI가 정상인가?"에 답합니다. DevOps, FinOps, 보안 팀이 실제로 묻는 질문에는 답하지 못합��니다:
- 어떤 호출자가 Bedrock 예산의 80%를 소비하고 있는가?
- 오후 3시 배포 후 왜 완료율이 떨어졌는가?
- 크로스 리전 추론이 실제로 도움이 되는가, 아니면 지연시간만 추가하는가?
- 어떤 프롬프트가 캐싱에서 가장 큰 이점을 얻을 수 있는가?
- PII를 반환한 모델 호출을 누가 했고, 무엇을 물었는가?
- 에이전트가 도구 레이어에서 실패하는가, 모델 레이어에서 실패하는가?
이러한 질문에 답하려면 로그 그룹을 조인하고, 토큰에서 비용을 계산하고, IAM 역할로 세그먼트하고, 스팬 트리를 드릴다운하는 커스텀 쿼리가 필요합니다. 원시 텔레메트리는 이미 흐르고 있으며 — 가치는 이를 어떻게 분석하느냐에 있습니다.
하나의 파이프라인, 다양한 대상
GenAI 텔레메트리는 세 개의 로그 그룹에 도착합니다: bedrock-model-invocation-logging, aws/spans, /aws/bedrock-agentcore/runtimes/<agent>. 데이터는 변하지 않지만 표현 방식이 다릅니다. 동일한 호출 데이터가 다음과 같이 됩니다:
- DevOps 대시보드 — 완료율, 컴포넌트 지연시간, 에이전트 오류 드릴다운을 보여주며 "시스템이 작동하는가?"에 초점
- FinOps 대시보드 — 모델별 비용, 상위 지출자, 캐싱 기회를 보여주며 "효율적으로 지출하고 있는가?"에 초점
이 가이드는 두 가지를 모두 구축하기 위한 쿼리를 제��공합니다. 대상에 맞는 섹션을 선택하세요. 각 쿼리는 소스 로그 그룹, 뷰 유형, 쿼리 언어, 답변하는 질문을 표기합니다.
기본 데이터 파이프라인과 각각을 언제 활성화해야 하는지에 대한 개요는 GenAI Observability on AWS를 참조하세요.
DevOps 페르소나 대시보드
DevOps 팀은 다음에 답해야 합니다: 내 GenAI 워크로드가 정상이고, 병목현상은 어디인가? 이 쿼리들은 호출 상태, 에이전트 워크플로우 안정성, 성능 병목현상에 초점을 맞춥니다.
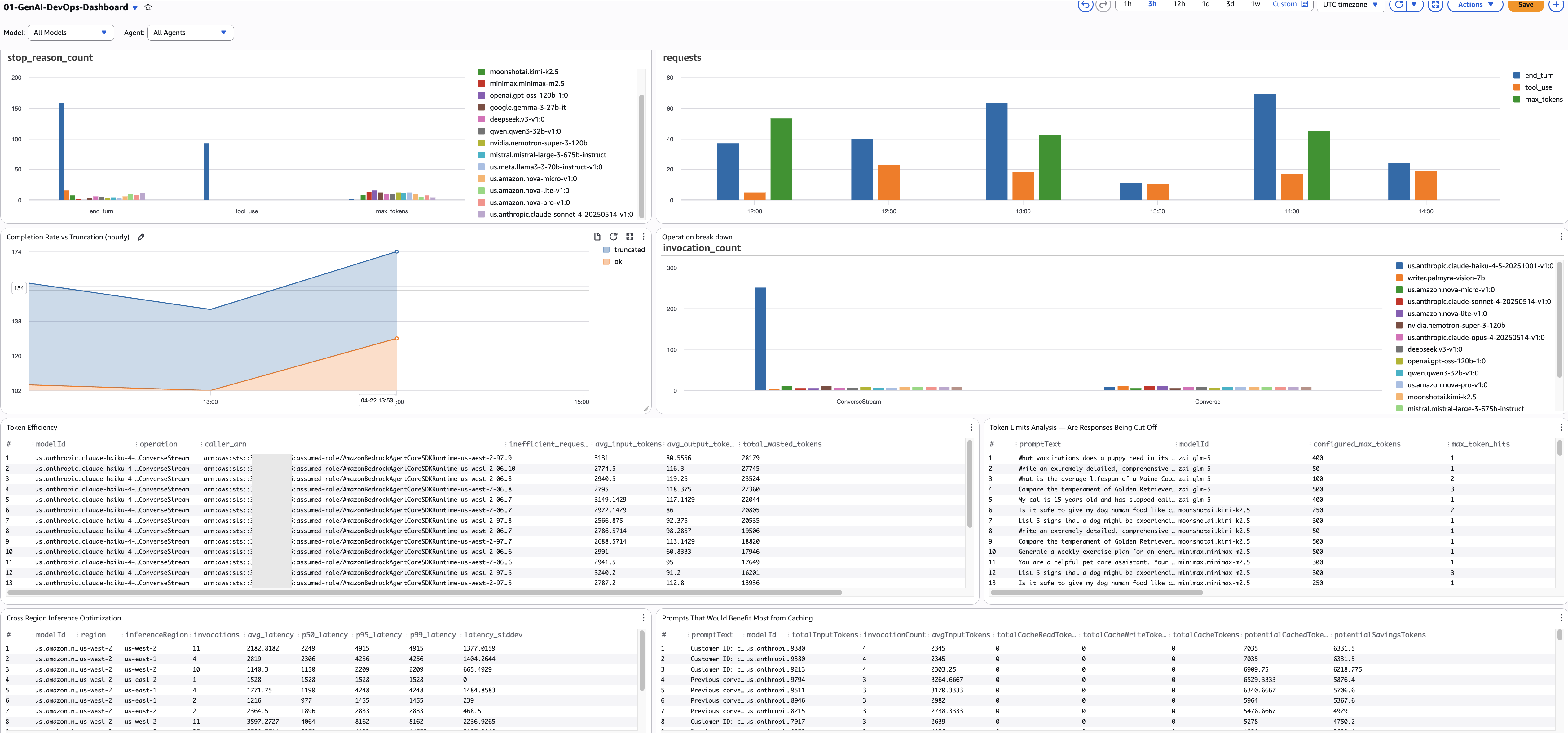
모델 호출 상태
1. 모델별 종료 사유 분류
- 목적: 모든 모델에 걸친 모든 종료 사유의 분포를 보여줍니다. 모든 Bedrock 호출은 종료 사유와 함께 끝납니다 —
end_turn(자연 완료),tool_use(도구 호출),max_tokens(잘림),stop_sequence(경계 도달), 또는 오류. 예: 요약 모델 호출의 15%가max_tokens로 끝나는 것을 발견할 수 있습니다 — 사용자가 잘린 응답을 받고 있다는 의미 — 반면 분류 모델은 100%end_turn입니다. - 소스:
bedrock-model-invocation-logging - 뷰: 막대 차트
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields @timestamp, modelId, operation, requestId,
output.outputBodyJson.stopReason as stop_reason
| filter schemaType = "ModelInvocationLog"
| filter ispresent(output.outputBodyJson.stopReason)
or ispresent(output.outputBodyJson.error)
| stats count() as stop_reason_count by stop_reason, modelId
- 알람: 비정상 종료 사유(
end_turn,tool_use,stop_sequence가 아닌 것)가 모델 전체 호출의 10%를 초과하는 경우.
2. 완료율 대 잘림 (시간별)
- 목적: 성공적 완료(
end_turn+tool_use) 대 잘린 응답(max_tokens)의 시간별 비율을 추적합니다. 이것이 SLA 메트릭입니다 — 95% 이상의 완료율을 목표로 하세요. 예: 오후 3시에서 4시 사이에 완료율이 97%에서 88%로 떨어지면 무언가 변경된 것입니다 — 새 프롬프트 템플릿, 모델 업데이트 또는 구성 변경이 더 많은 잘림을 야기하고 있습니다. - 소스:
bedrock-model-invocation-logging - 뷰: 시계열 (스택형)
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields @timestamp, modelId,
output.outputBodyJson.stopReason as stop_reason
| filter schemaType = "ModelInvocationLog"
| filter ispresent(output.outputBodyJson.stopReason)
| stats sum(stop_reason = "end_turn" or stop_reason = "tool_use") as ok,
sum(stop_reason = "max_tokens") as truncated
by bin(@timestamp, 1h) as hour
| sort hour desc
- 알람:
ok / (ok + truncated)가 2시간 연속 95% 미만인 경우.
3. 토큰 효율성 — 낭비 토큰 찾기
- 목적: 높은 입력 토큰(2000 초과)을 보내면서 낮은 출력(200 미만)을 받는 호출자를 찾습니다 — 토큰 낭비의 징후입니다. 예: 한 단어 레이블(3 토큰)을 얻기 위해 전체 제품 카탈로그(8000 토큰)를 보내는 분류 파이프라인.
caller_arn컬럼은 정확히 어떤 서비스나 역할이 책임이 있는지 알려주므로, 프롬프트 재구성에 대한 타겟된 대화가 가능합니다. - 소스:
bedrock-model-invocation-logging - 뷰: 테이블
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields @timestamp, modelId, operation,
input.inputTokenCount as input_tokens,
output.outputTokenCount as output_tokens,
identity.arn as caller_arn
| filter schemaType = "ModelInvocationLog"
| filter input_tokens > 2000 and output_tokens < 200
| stats count() as inefficient_requests,
avg(input_tokens) as avg_input_tokens,
avg(output_tokens) as avg_output_tokens,
sum(input_tokens) as total_wasted_tokens
by modelId, operation, caller_arn
| sort total_wasted_tokens desc
- 알람: 24시간 내
total_wasted_tokens가 100K를 초과하는 호출자.
4. 크로스 리전 추론 지연시간
- 목적: 각 모델에 대해 추론 리전별 지연시간 백분위수를 비교합니다. 크로스 리전 추론을 활성화한 경우 일부 요청은 더 높은 지연시간을 가진 원거리 리전으로 라우팅됩니다. 예: 요약 모델의 P95가 us-west-2에서 12초이지만 us-east-1에서 4초라면 — us-east-1을 선호하도록 추론 프로필을 구성하면 P95를 40% 줄일 수 있습니다.
- 소스:
bedrock-model-invocation-logging - 뷰: 테이블
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields @timestamp, modelId, region, inferenceRegion,
output.outputBodyJson.metrics.latencyMs as latency
| filter schemaType = "ModelInvocationLog"
| filter ispresent(inferenceRegion)
| filter latency > 0
| stats count() as invocations,
avg(latency) as avg_latency,
pct(latency, 50) as p50_latency,
pct(latency, 95) as p95_latency,
pct(latency, 99) as p99_latency,
stddev(latency) as latency_stddev
by modelId, region, inferenceRegion
| sort modelId asc, avg_latency asc
- 알람: 특정 리전에서 모델 P95가 10초를 초과하는 경우.
5. 프롬프트 캐싱 기회
- 목적: 반복 호출되지만 캐시 히트가 없거나 낮은 프롬프트를 찾습니다 — 가장 큰 캐싱 ROI 기회입니다. 예: 500회 사용되었지만 캐시 읽기가 0인 시스템 프롬프트는 매번 전체 비용을 지불하고 있다는 의미입니다 — 캐싱을 활성화하면 해당 입력 토큰의 90%를 절약할 수 있습니다.
- 소스:
bedrock-model-invocation-logging - 뷰: 테이블
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields @timestamp,
input.inputBodyJson.messages.0.content.0.text as promptText,
input.inputTokenCount as inputTokens,
input.cacheReadInputTokenCount as cacheReadTokens,
input.cacheWriteInputTokenCount as cacheWriteTokens,
modelId
| filter input.inputTokenCount > 0
| stats sum(input.inputTokenCount) as totalInputTokens,
count(*) as invocationCount,
avg(input.inputTokenCount) as avgInputTokens,
sum(input.cacheReadInputTokenCount) as totalCacheReadTokens,
sum(input.cacheWriteInputTokenCount) as totalCacheWriteTokens
by promptText, modelId
| filter invocationCount > 1
| sort totalInputTokens desc
- 알람: 없음 (최적화 검토용, 주간 실행).
에이전트 워크플로우 상태
6. 에이전트 트레이스 대 오류 (시간별)
- 목적: 전체 에이전트 트레이스와 오류 스팬의 시간별 카운트 — 에이전트 수준의 안정성 메트릭입니다. 예: total_traces가 시간당 500이지만 error_spans가 오후 3시에 5에서 80으로 급증하면 에이전트 워크플로우에서 무언가 고장난 것입니다. 이것은 모델 수준 메트릭이 놓치는 문제를 포착합니다 — 모델은 성공하면서 도구 타임아웃이나 가드레일 거부로 에이전트가 실패할 수 있습니다.
- 소스:
aws/spans - 뷰: 시계열
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields attributes.session.id as sessionId, traceId,
status.code as statusCode, durationNano/1000000 as durationMs
| filter ispresent(sessionId)
| stats count_distinct(traceId) as total_traces,
sum(statusCode = "ERROR") as error_spans
by bin(@timestamp, 1h) as hour
| sort hour desc
- 알람:
error_spans / total_traces가 15분간 10%를 초과하는 경우.
7. 스팬 오류 드릴다운
- 목적: 에이전트 오류가 있을 때, 정확히 어떤 컴포넌트가 실패하는지 알려줍니다 — 지식 베이스 검색, 가드레일 검사, 도구 실행 또는 모델 호출. 예: 오류의 70%가 HTTP 503과 함께 KB 검색 스팬에 있다면 — 모델 문제가 아니라 OpenSearch 클러스터가 부하에서 스로틀링되고 있는 것입니다.
- 소스:
aws/spans - 뷰: 테이블
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields name as spanName,
resource.attributes.service.name as serviceName,
status.code as statusCode,
status.message as statusMessage,
attributes.http.response.status_code as httpStatus,
durationNano/1000000 as durationMs,
traceId, spanId, parentSpanId
| filter resource.attributes.aws.service.type = "gen_ai_agent"
| filter status.code = "ERROR"
or attributes.http.response.status_code >= 400
| stats count() as error_count,
count_distinct(traceId) as affected_traces,
avg(durationMs) as avg_error_duration_ms,
earliest(statusMessage) as error_message
by spanName, serviceName, httpStatus
| sort error_count desc
- 알람: 15분 내 10건 이상의 오류가 있는 컴포넌트.
8. 컴포넌트 성능 분석 (시간별)
- 목적: 전체 백분위수 분포(P50, P95, P99)를 포함한 에이전트 컴포넌트별 시간당 성능입니다. 에이전트 시간이 어디에 소비되는지와 어떤 컴포넌트가 병목인지 보여줍니다. 예: 가드레일 검사가 평균 2.8초(P95: 4.1초)이고 모델 호출이 평균 1.2초(P95: 2.0초)라면 — 가드레일을 먼저 최적화하세요, 모델 최적화보다 영향이 더 큽니다.
- 소스:
aws/spans - 뷰: 테이블
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields name as spanName,
resource.attributes.service.name as serviceName,
durationNano/1000000 as durationMs,
traceId
| filter resource.attributes.aws.service.type = "gen_ai_agent"
| filter ispresent(spanName)
| stats count() as invocations,
avg(durationMs) as avg_duration_ms,
pct(durationMs, 50) as p50_duration_ms,
pct(durationMs, 95) as p95_duration_ms,
pct(durationMs, 99) as p99_duration_ms,
sum(durationMs) as total_time_ms
by bin(1h), spanName, serviceName
| sort total_time_ms desc
- 알람: 컴포넌트 P95가 5000ms를 초과하는 경우.
FinOps 페르소나 대시보드
FinOps 팀은 다음에 답해야 합니다: GenAI 지출이 어디로 가고 있으며, 어떻게 최적화할 수 있는가? 이 쿼리들은 토큰 사용량에서 비용을 계산하고, 팀과 역할에 지출을 귀속시키며, 프롬프트 캐싱과 같은 최적화 기회를 표면화합니다.
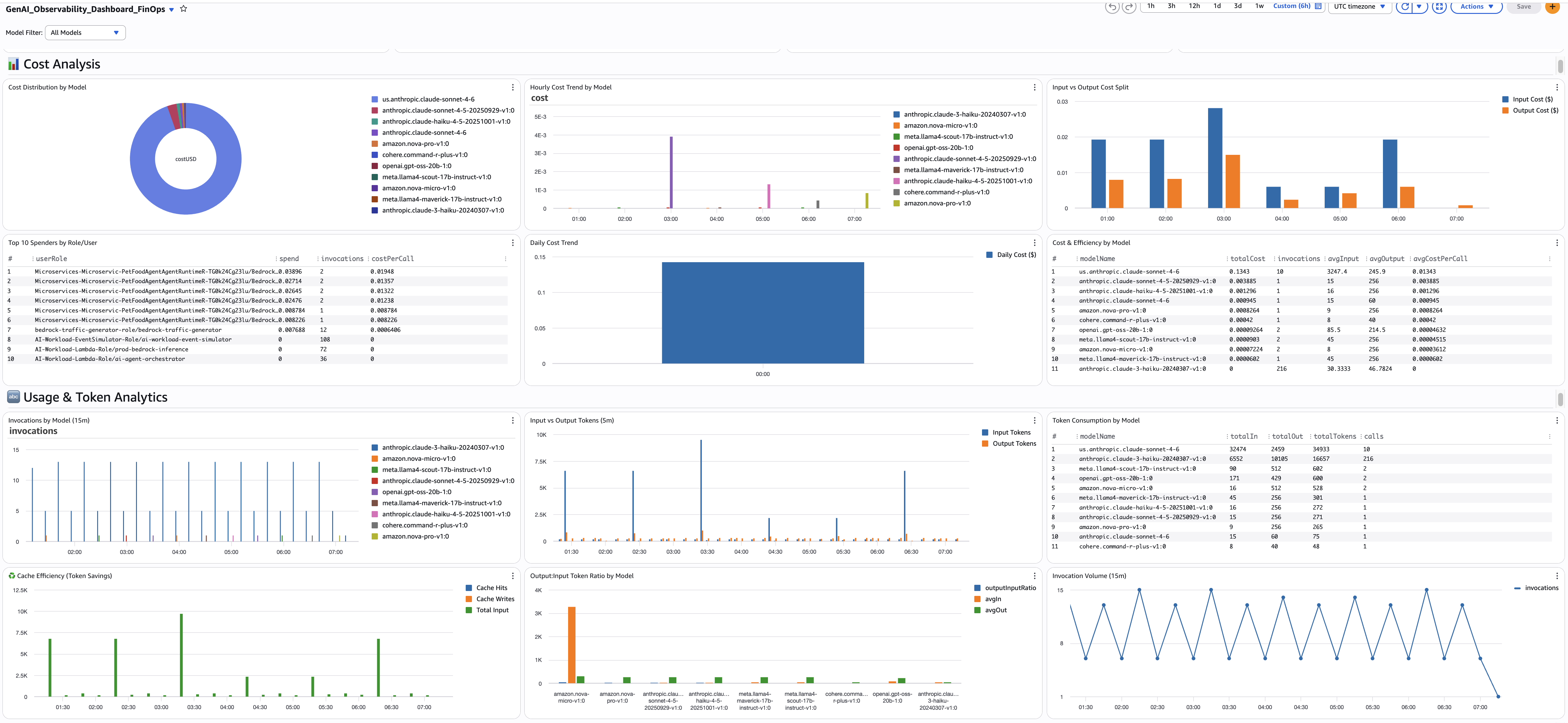
모든 FinOps 쿼리는 토큰당 가격을 기반으로 하는 비용 계산 패턴을 사용합니다. strcontains 곱셈 패턴은 각 모델을 토큰당 요율에 매핑합니다. Bedrock 가격이 변경되면 가격 값을 업데이트하세요.
요약
9. 총 예상 지출
- 목적: 선택한 시간 범위에서 모든 모델에 걸친 총 GenAI 지출을 보여주는 단일 값 위젯입니다. 이것이 헤드라인 KPI — CFO가 관심을 갖는 숫자입니다.
- 소스:
bedrock-model-invocation-logging - 뷰: 단일 값
- 쿼리 언어: CloudWatch Logs Insights
- 쿼리:
fields coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens
| fields (inputTokens *
((strcontains(modelId, "nova-micro") * 0.000000035) +
(strcontains(modelId, "nova-lite") * 0.00000006) +
(strcontains(modelId, "nova-pro") * 0.0000008) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000003) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000003) +
(strcontains(modelId, "claude-haiku") * 0.000001) +
(strcontains(modelId, "llama4-maverick") * 0.0000002) +
(strcontains(modelId, "llama4-scout") * 0.00000015) +
(strcontains(modelId, "command-r-plus") * 0.0000025) +
(strcontains(modelId, "command-r-v") * 0.00000015) +
(strcontains(modelId, "gpt-oss-120b") * 0.00000009) +
(strcontains(modelId, "gpt-oss-20b") * 0.00000004))) +
(outputTokens *
((strcontains(modelId, "nova-micro") * 0.00000014) +
(strcontains(modelId, "nova-lite") * 0.00000024) +
(strcontains(modelId, "nova-pro") * 0.0000032) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000015) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000015) +
(strcontains(modelId, "claude-haiku") * 0.000005) +
(strcontains(modelId, "llama4-maverick") * 0.0000002) +
(strcontains(modelId, "llama4-scout") * 0.00000015) +
(strcontains(modelId, "command-r-plus") * 0.00001) +
(strcontains(modelId, "command-r-v") * 0.0000006) +
(strcontains(modelId, "gpt-oss-120b") * 0.00000045) +
(strcontains(modelId, "gpt-oss-20b") * 0.0000002))) as totalCostUSD
| stats sum(totalCostUSD) as TotalSpendUSD
- 알람: 일일 지출이 7일 평균의 150%를 초과하는 경우.
나머지 FinOps 쿼리(10-17번)와 전체 쿼리 세트는 영어 원본 가이드를 참조하세요. 쿼리 SQL 자체는 동일하며, 위에서 설명한 패턴을 따릅니다.
다음 단계
두 파이프라인이 모두 흐르면 다양한 대상을 위한 대시보드를 구축할 수 있습니다. 기본 데이터 파이프라인과 활성화 시기에 대한 개요는 AWS에서의 GenAI Observability 가이드를 참조하세요.