为 GenAI 遥测数据创建自定义 Dashboard
为什么需要自定义 Dashboard?
当您启用 Bedrock Model Invocation Logging 并部署 ADOT 自动检测 agent 时,AWS 通过开箱即用的 dashboard 为您提供了一个良好的起点。Bedrock 自动提供调用计数、延迟、token 计数和限流 metrics。Application Signals 自动生成服务映射和 SLO 视图。这是一个坚实的基础 — 但不是全貌。
开箱即用的 dashboard 回答"我的 AI 现在健康吗?"它们不回答 DevOps、FinOps 和安全团队实际提出的问题:
- 哪个调用者消耗了我们 Bedrock 预算的 80%?
- 为什么完成率在下午 3 点部署后下降了?
- 跨区域推理实际上有帮助吗,还是增加了延迟?
- 哪些提示最适合缓存?
- 谁发起了那个返回 PII 的模型调用,他们问了什么?
- 我的 Agent 是在工具层还是模型层失败的?
回答这些问题需要自定义查询,这些查询连接日志组、从 token 计算成本、按 IAM 角色分段并深入 span 树。原始遥测数据已经在流动 — 价值来自于您如何切片。
一个管道,不同的受众
您的 GenAI 遥测数据落入三个日志组:bedrock-model-invocation-logging、aws/spans 和 /aws/bedrock-agentcore/runtimes/<agent>。数据不变,但呈现方式不同。相同的调用数据变成:
- DevOps dashboard 展示完成率、组件延迟和 Agent 错误下钻 — 聚焦于"系统是否正常工作?"
- FinOps dashboard 展示每个模型的成本、最大支出者和缓存优化机会 — 聚焦于"我们的支出是否高效?"
本指南为您提供构建这两种 dashboard 所需的查询。请根据您的受众选择相关章节。每个查询都标注了其来源日志组、视图类型、查询语言以及它所回答的问题。
有关底层数据管道的概述以及何时启用各管道,请参阅 GenAI Observability on AWS。
DevOps 角色 Dashboard
DevOps 团队需要回答:我的 GenAI 工作负载是否健康,瓶颈在哪里? 这些查询聚焦于调用健康状况、Agent 工作流可靠性和性能瓶颈。
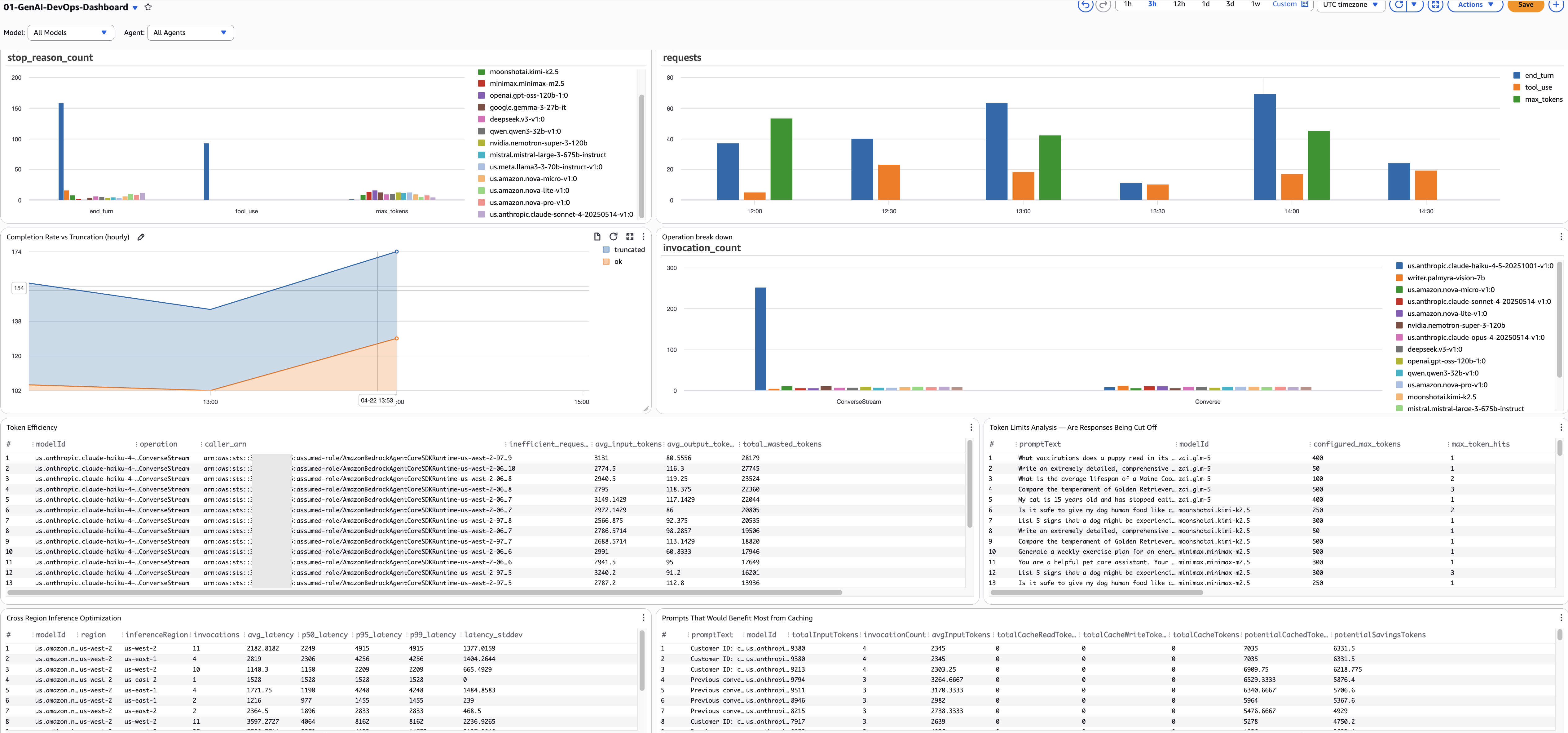
模型调用健康状况
1. 按模型分类的停止原因分布
- 用途: 展示所有模型的停止原因分布。每个 Bedrock 调用都以一个停止原因结束 —
end_turn(自然完成)、tool_use(调用工具)、max_tokens(被截断)、stop_sequence(触发边界)或错误。例如:您可能发现摘要模型 15% 的调用以max_tokens结束 — 意味着用户获得了被截断的响应 — 而分类模型则 100% 为end_turn。 - 来源:
bedrock-model-invocation-logging - 视图: 柱状图
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp, modelId, operation, requestId,
output.outputBodyJson.stopReason as stop_reason
| filter schemaType = "ModelInvocationLog"
| filter ispresent(output.outputBodyJson.stopReason)
or ispresent(output.outputBodyJson.error)
| stats count() as stop_reason_count by stop_reason, modelId
- 告警: 任何非健康停止原因(非
end_turn、tool_use或stop_sequence)超过模型总调用量的 10%。
2. 完成率与截断率(按小时)
- 用途: 按小时跟踪成功完成(
end_turn+tool_use)与截断响应(max_tokens)的比率。这是您的 SLA metric — 目标为 95% 以上的完成率。例如:如果完成率在下午 3 点到 4 点之间从 97% 下降到 88%,说明有变化发生 — 新的提示模板、模型更新或配置更改导致了更多截断。 - 来源:
bedrock-model-invocation-logging - 视图: 时间序列(堆叠)
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp, modelId,
output.outputBodyJson.stopReason as stop_reason
| filter schemaType = "ModelInvocationLog"
| filter ispresent(output.outputBodyJson.stopReason)
| stats sum(stop_reason = "end_turn" or stop_reason = "tool_use") as ok,
sum(stop_reason = "max_tokens") as truncated
by bin(@timestamp, 1h) as hour
| sort hour desc
- 告警:
ok / (ok + truncated)连续 2 小时低于 95%。
3. Token 效率 — 发现浪费的 Token
- 用途: 查找发送高输入 token(超过 2000)但接收低输出(低于 200)的调用者 — 这是 token 浪费的信号。例如:一个分类管道将整个产品目录(8000 token)发送给模型以获取一个单词的标签(3 token)。
caller_arn列精确告诉您哪个服务或角色负责,以便您可以有针对性地讨论重构其提示。 - 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp, modelId, operation,
input.inputTokenCount as input_tokens,
output.outputTokenCount as output_tokens,
identity.arn as caller_arn
| filter schemaType = "ModelInvocationLog"
| filter input_tokens > 2000 and output_tokens < 200
| stats count() as inefficient_requests,
avg(input_tokens) as avg_input_tokens,
avg(output_tokens) as avg_output_tokens,
sum(input_tokens) as total_wasted_tokens
by modelId, operation, caller_arn
| sort total_wasted_tokens desc
- 告警: 任何调用者在 24 小时内
total_wasted_tokens超过 100K。
4. 跨区域推理延迟
- 用途: 比较每个模型在不同推理区域的延迟百分位数。如果您启用了跨区域推理,某些请求会路由到延迟更高的远端区域。例如:您的摘要模型 P95 在 us-west-2 为 12 秒,但在 us-east-1 为 4 秒 — 配置推理配置文件优先选择 us-east-1 可以将 P95 降低 40%。
- 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp, modelId, region, inferenceRegion,
output.outputBodyJson.metrics.latencyMs as latency
| filter schemaType = "ModelInvocationLog"
| filter ispresent(inferenceRegion)
| filter latency > 0
| stats count() as invocations,
avg(latency) as avg_latency,
pct(latency, 50) as p50_latency,
pct(latency, 95) as p95_latency,
pct(latency, 99) as p99_latency,
stddev(latency) as latency_stddev
by modelId, region, inferenceRegion
| sort modelId asc, avg_latency asc
- 告警: 任何模型在特定区域的 P95 超过 10 秒。
5. 提示缓存优化机会
- 用途: 查找被重复调用但缓存命中为零或很低的提示 — 这些是缓存投资回报率最高的机会。例如:一个系统提示被使用 500 次但缓存读取为零,意味着您每次都在支付全价 — 启用缓存可以节省这些输入 token 90% 的费用。
- 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp,
input.inputBodyJson.messages.0.content.0.text as promptText,
input.inputTokenCount as inputTokens,
input.cacheReadInputTokenCount as cacheReadTokens,
input.cacheWriteInputTokenCount as cacheWriteTokens,
modelId
| filter input.inputTokenCount > 0
| stats sum(input.inputTokenCount) as totalInputTokens,
count(*) as invocationCount,
avg(input.inputTokenCount) as avgInputTokens,
sum(input.cacheReadInputTokenCount) as totalCacheReadTokens,
sum(input.cacheWriteInputTokenCount) as totalCacheWriteTokens
by promptText, modelId
| filter invocationCount > 1
| sort totalInputTokens desc
- 告警: 无(优化审查,建议每周运行)。
Agent 工作流健康状况
6. Agent Traces 与错误(按小时)
- 用途: 按小时统计 Agent traces 总数和错误 span 数 — 这是您的 Agent 级可靠性 metric。例如:如果 total_traces 为 500/小时,但 error_spans 在下午 3 点从 5 跃升到 80,说明 Agent 工作流出了问题。这能捕获模型级 metrics 遗漏的问题 — 模型可能成功但 Agent 因工具超时或护栏拒绝而失败。
- 来源:
aws/spans - 视图: 时间序列
- 查询语言: CloudWatch Logs Insights
- 查询:
fields attributes.session.id as sessionId, traceId,
status.code as statusCode, durationNano/1000000 as durationMs
| filter ispresent(sessionId)
| stats count_distinct(traceId) as total_traces,
sum(statusCode = "ERROR") as error_spans
by bin(@timestamp, 1h) as hour
| sort hour desc
- 告警:
error_spans / total_traces超过 10% 持续 15 分钟。
7. Span 错误下钻
- 用途: 当您已知存在 Agent 错误时,此查询精确告诉您是哪个组件出了问题 — 知识库检索、护栏检查、工具执行还是模型调用。例如:70% 的错误出现在知识库检索 span 中且 HTTP 状态码为 503 — 是您的 OpenSearch 集群在负载下限流,而不是模型问题。
- 来源:
aws/spans - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields name as spanName,
resource.attributes.service.name as serviceName,
status.code as statusCode,
status.message as statusMessage,
attributes.http.response.status_code as httpStatus,
durationNano/1000000 as durationMs,
traceId, spanId, parentSpanId
| filter resource.attributes.aws.service.type = "gen_ai_agent"
| filter status.code = "ERROR"
or attributes.http.response.status_code >= 400
| stats count() as error_count,
count_distinct(traceId) as affected_traces,
avg(durationMs) as avg_error_duration_ms,
earliest(statusMessage) as error_message
by spanName, serviceName, httpStatus
| sort error_count desc
- 告警: 任何组件在 15 分钟内超过 10 个错误。
8. 组件性能分解(按小时)
- 用途: 按小时展示每个 Agent 组件的性能,包含完整的百分位分布(P50、P95、P99)。展示 Agent 时间花在哪里以及哪个组件是瓶颈。例如:护栏检查平均耗时 2.8 秒(P95:4.1 秒),而模型调用平均耗时 1.2 秒(P95:2.0 秒)— 应优先优化护栏,其影响比任何模型优化都大。
- 来源:
aws/spans - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields name as spanName,
resource.attributes.service.name as serviceName,
durationNano/1000000 as durationMs,
traceId
| filter resource.attributes.aws.service.type = "gen_ai_agent"
| filter ispresent(spanName)
| stats count() as invocations,
avg(durationMs) as avg_duration_ms,
pct(durationMs, 50) as p50_duration_ms,
pct(durationMs, 95) as p95_duration_ms,
pct(durationMs, 99) as p99_duration_ms,
sum(durationMs) as total_time_ms
by bin(1h), spanName, serviceName
| sort total_time_ms desc
- 告警: 任何组件 P95 超过 5000ms。
FinOps 角色 Dashboard
FinOps 团队需要回答:我们的 GenAI 支出去哪里了,如何优化? 这些查询从 token 使用量计算成本,将支出归因于团队和角色,并发现提示缓存等优化机会。
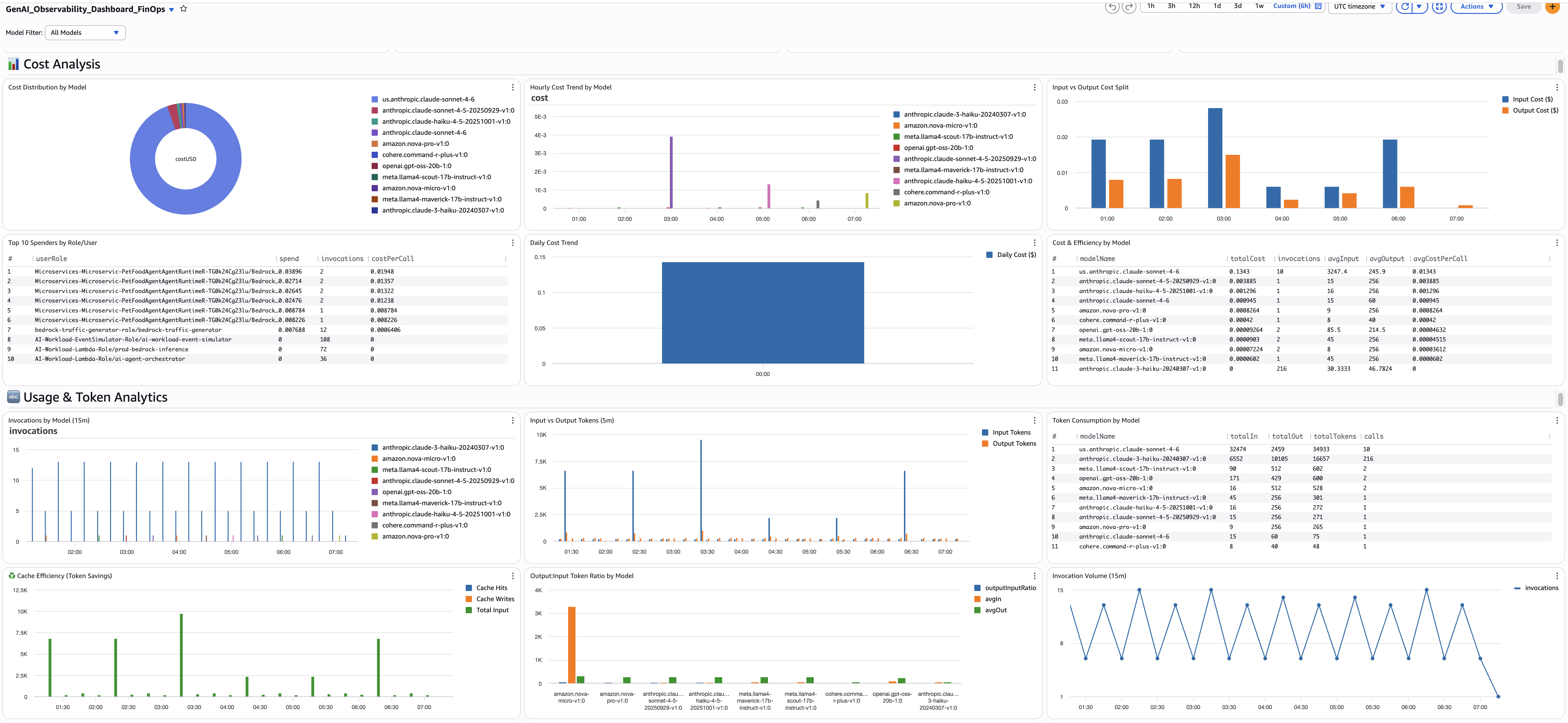
所有 FinOps 查询都使用基于每 token 定价的成本计算模式。strcontains 乘法模式将每个模型映射到其每 token 费率。当 Bedrock 定价变更时请更新定价值。
执行摘要
9. 总估算支出
- 用途: 单值小组件,显示所选时间范围内所有模型的 GenAI 总支出。这是您的核心 KPI — CFO 关心的数字。
- 来源:
bedrock-model-invocation-logging - 视图: 单值
- 查询语言: CloudWatch Logs Insights
- 查询:
fields coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens
| fields (inputTokens *
((strcontains(modelId, "nova-micro") * 0.000000035) +
(strcontains(modelId, "nova-lite") * 0.00000006) +
(strcontains(modelId, "nova-pro") * 0.0000008) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000003) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000003) +
(strcontains(modelId, "claude-haiku") * 0.000001) +
(strcontains(modelId, "llama4-maverick") * 0.0000002) +
(strcontains(modelId, "llama4-scout") * 0.00000015) +
(strcontains(modelId, "command-r-plus") * 0.0000025) +
(strcontains(modelId, "command-r-v") * 0.00000015) +
(strcontains(modelId, "gpt-oss-120b") * 0.00000009) +
(strcontains(modelId, "gpt-oss-20b") * 0.00000004))) +
(outputTokens *
((strcontains(modelId, "nova-micro") * 0.00000014) +
(strcontains(modelId, "nova-lite") * 0.00000024) +
(strcontains(modelId, "nova-pro") * 0.0000032) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000015) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000015) +
(strcontains(modelId, "claude-haiku") * 0.000005) +
(strcontains(modelId, "llama4-maverick") * 0.0000002) +
(strcontains(modelId, "llama4-scout") * 0.00000015) +
(strcontains(modelId, "command-r-plus") * 0.00001) +
(strcontains(modelId, "command-r-v") * 0.0000006) +
(strcontains(modelId, "gpt-oss-120b") * 0.00000045) +
(strcontains(modelId, "gpt-oss-20b") * 0.0000002))) as totalCostUSD
| stats sum(totalCostUSD) as TotalSpendUSD
- 告警: 每日支出超过 7 天平均值的 150%。
成本分析
10. 按模型分类的成本分布
- 用��途: 饼图展示哪些模型占据了您的支出。例如:您发现 Claude Sonnet 4.6 占账单的 70% 而 Nova Lite 仅占 5% — 如果某些用例可以迁移到 Nova,这就是一个提示迁移机会。
- 来源:
bedrock-model-invocation-logging - 视图: 饼图
- 查询语言: CloudWatch Logs Insights
- 查询(在查询 9 的成本计算模式后追加):
| stats sum(totalCostUSD) as costUSD by modelName
| sort costUSD desc
- 告警: 无(信息展示用途)。
11. 按角色/用户排列的前 10 名支出者
- 用途: 识别哪些 IAM 角色或用户在驱动支出。结合调用次数和单次调用成本,您可以看出某个团队支出更多是因为调用量还是因为其调用更昂贵。例如:
data-science-exploration角色有 100K 次调用,每次 $0.002,而prod-chatbot有 10K 次调用,每次 $0.05 — 优化路径完全不同。 - 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields replace(`identity.arn`, "arn:aws:sts::ACCOUNT_ID:assumed-role/", "") as userRole
| fields coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens
| fields (inputTokens *
((strcontains(modelId, "nova-micro") * 0.000000035) +
(strcontains(modelId, "nova-lite") * 0.00000006) +
(strcontains(modelId, "nova-pro") * 0.0000008) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000003) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000003) +
(strcontains(modelId, "claude-haiku") * 0.000001))) +
(outputTokens *
((strcontains(modelId, "nova-micro") * 0.00000014) +
(strcontains(modelId, "nova-lite") * 0.00000024) +
(strcontains(modelId, "nova-pro") * 0.0000032) +
(strcontains(modelId, "claude-sonnet-4-6") * 0.000015) +
(strcontains(modelId, "claude-sonnet-4-5") * 0.000015) +
(strcontains(modelId, "claude-haiku") * 0.000005))) as totalCostUSD
| stats sum(totalCostUSD) as spend,
count(*) as invocations,
(sum(totalCostUSD) / count(*)) as costPerCall
by userRole
| sort spend desc
| limit 10
- 告警: 任何角色的每日支出超过其 7 天平均值的 2 倍。
12. 输入与输出成本分布(按小时)
- 用途: 展示您在输入 token(提示)还是输出 token(完成)上花费更多。如果输入成本占主导,请优化提示并启用缓存。如果输出成本占主导,请减少 max_tokens 或切换到更便宜的模型。
- 来源:
bedrock-model-invocation-logging - 视图: 柱状图(堆叠)
- 查询语言: CloudWatch Logs Insights
- 查询(在成本计算模式后追加,拆分输入/输出):
| stats sum(inputCostUSD) as InputCost, sum(outputCostUSD) as OutputCost
by bin(1h) as hour
| sort hour asc
- 告警: 无(分析小组件)。
Token 消耗
13. 调用计数(15 分钟窗口)
- 用途: 以 15 分钟为窗口的流量基线。如果调用量通常为每窗口 2-4 次但突然飙升到 10 次,说明有变化发生 — 新功能上线、负载测试或失控的重试循环。将其与小时成本趋势对比,可以看出成本峰值是与流量峰值相关还是与模型选择变化相关。
- 来源:
bedrock-model-invocation-logging - 视图: 时间序列
- 查询语言: CloudWatch Logs Insights
- 查询:
stats count(*) as invocations by bin(15m) as period
| sort period asc
- 告警: 连续 2 个周期调用量超过正常 15 分钟平均值的 3 倍。
14. 输入与输出 Token
- 用途: 以 5 分钟为窗口展示输入与输出 token 消耗量。比率揭示了您的工作负载特征。例如:如果输入 token 持续为输出 token 的 10 倍,说明您正在为短响应发送大量上下文(RAG、系统提示)— 这是提示缓存的最佳候选场景。如果输出 token 突然飙升,可能是模型更新或提示变更导致生成了更长的响应。
- 来源:
bedrock-model-invocation-logging - 视图: 柱状图(堆叠)
- 查询语言: CloudWatch Logs Insights
- 查询:
fields
coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens
| stats sum(inputTokens) as totalInputTokens,
sum(outputTokens) as totalOutputTokens
by bin(5m) as period
| sort period asc
- 告警: 输入输出比超过 20:1 持续 1 小时 — 需调查提示优化。
15. Token 总量
- 用途: 以 5 分钟为窗口的合计(输入 + 输出)token 消耗量。最简单的使用量视图。例如:如果总 token 量逐周增长但调用次数没有相应增加,说明单个请求正在变大(更长的提示或更长的响应)。与调用计数对比可以区分"更多请求"和"更大的请求"。
- 来源:
bedrock-model-invocation-logging - 视图: 柱状图
- 查询语言: CloudWatch Logs Insights
- 查询:
fields
coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens
| stats sum(inputTokens) + sum(outputTokens) as totalTokens by bin(5m) as period
| sort period asc
- 告警: 任何 5 分钟窗口内总 token 量超过 7 天平均值的 200%。
调用详情
16. 单次调用详情表
- 用途: 最近 200 次调用的完整详情 — 模型名称、temperature、maxTokens 配置、输入/输出/总 token 数、缓存读写 token 数以及每次调用的估算成本。这是用于调查特定调用的下钻表。例如:您发现一个调用有 12,000 输入 token、50 输出 token、零缓存读取、成本 $0.04 — 这是一个将整个文档发送给模型进行分类的任务。
- 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
fields @timestamp, modelId,
replace(replace(replace(modelId,
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:inference-profile/us.", ""),
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:inference-profile/", ""),
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:", "") as modelName,
coalesce(input.inputBodyJson.inferenceConfig.temperature,
input.inputBodyJson.temperature) as temperature,
coalesce(input.inputBodyJson.inferenceConfig.maxTokens,
input.inputBodyJson.max_completion_tokens,
input.inputBodyJson.max_tokens) as maxTokens,
coalesce(output.outputBodyJson.usage.inputTokens,
output.outputBodyJson.usage.prompt_tokens,
output.outputBodyJson.usage.input_tokens,
input.inputTokenCount) as inputTokens,
coalesce(output.outputBodyJson.usage.outputTokens,
output.outputBodyJson.usage.completion_tokens,
output.outputBodyJson.usage.output_tokens,
output.outputTokenCount) as outputTokens,
coalesce(output.outputBodyJson.usage.totalTokens,
output.outputBodyJson.usage.total_tokens,
floor(inputTokens + outputTokens)) as totalTokens,
coalesce(output.outputBodyJson.usage.cache_read_input_tokens,
output.outputBodyJson.usage.cacheReadInputTokenCount) as cacheReadTokens,
coalesce(output.outputBodyJson.usage.cache_creation_input_tokens,
output.outputBodyJson.usage.cacheWriteInputTokenCount) as cacheWriteTokens
| display @timestamp, modelName, temperature, maxTokens,
inputTokens, outputTokens, totalTokens,
cacheReadTokens, cacheWriteTokens
| sort @timestamp desc
| limit 200
- 告警: 无(下钻表 — 用于问题调查)。
17. Token 数最高的前 10 个提示
- 用途: Token 消耗最高的 10 次调用,包含完整的请求/响应体、模型名称、token 计数和延迟。这些是您最昂贵的单次调用。例如:排名第一的提示使用了 15,000 token 且延迟 8 秒 — 阅读实际提示文本会发现它将整个知识库塞入上下文而不是使用检索。需要在 Bedrock 模型调用日志设置中启用"记录请求和响应体"。
- 来源:
bedrock-model-invocation-logging - 视图: 表格
- 查询语言: CloudWatch Logs Insights
- 查询:
filter !isPresent(errorCode)
| fields jsonParse(@message) as json_message,
replace(replace(replace(modelId,
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:inference-profile/us.", ""),
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:inference-profile/", ""),
"arn:aws:bedrock:us-east-1:ACCOUNT_ID:", "") as modelName
| unnest json_message.input into inputMessage
| unnest json_message.output into outputMessage
| display requestId, timestamp, modelName, inputMessage, outputMessage,
coalesce(input.inputTokenCount, 0) as inputTokenCount,
coalesce(output.outputTokenCount, 0) as outputTokenCount,
coalesce(input.inputTokenCount, 0) + coalesce(output.outputTokenCount, 0) as totalTokenCount,
(output.outputBodyJson.metrics.latencyMs / 1000) as latency
| sort totalTokenCount desc
| limit 10
- 告警: 任何单次调用超过 20,000 总 token — 需审查提示设计。
模型定价参考
这些价格仅为快照,可能已过时。AWS 会定期更新 Bedrock 定价并添加新模型。请始终在 AWS Bedrock 定价页面 上验证当前费率,并相应更新查询中 strcontains 乘数的值。
价格为每 token 单价(非每 1K 或 1M token)。更新方法:在 Bedrock 定价页面 找到您的模型,将每 1M token 价格转换为每 token 价格(除以 1,000,000),然后替换每个成本查询 strcontains 块中的对应值。
| 模型 | 输入 ($/token) | 输出 ($/token) |
|---|---|---|
| Nova Micro | 0.000000035 | 0.00000014 |
| Nova Lite | 0.00000006 | 0.00000024 |
| Nova Pro | 0.0000008 | 0.0000032 |
| Claude Sonnet 4.6 | 0.000003 | 0.000015 |
| Claude Sonnet 4.5 | 0.000003 | 0.000015 |
| Claude Sonnet 4 | 0.000003 | 0.000015 |
| Claude Haiku 4.5 | 0.000001 | 0.000005 |
| Llama 4 Maverick | 0.0000002 | 0.0000002 |
| Llama 4 Scout | 0.00000015 | 0.00000015 |
| Cohere Command R+ | 0.0000025 | 0.00001 |
| Cohere Command R | 0.00000015 | 0.0000006 |
| GPT OSS 120B | 0.00000009 | 0.00000045 |
| GPT OSS 20B | 0.00000004 | 0.0000002 |
告警建议
DevOps 告警
| 告警 | 条件 | 严重程度 |
|---|---|---|
| 完成率下降 | ok / (ok + truncated) 连续 2 小时低于 95% | 警告 |
| Token 浪费 | 调用者在 24 小时内浪费 token 超过 100K | 警告 |
| 跨区域延迟 | 模型 P95 在某区域超过 10 秒 | 警告 |
| Agent 错误率 | error_spans / total_traces 超过 10% 持续 15 分钟 | 严重 |
| 组件错误 | 组件在 15 分钟内超过 10 个错误 | 严重 |
| 组件延迟 | 组件 P95 超过 5000ms | 警告 |
FinOps 告警
| 告警 | 条件 | 严重程度 |
|---|---|---|
| 每日成本飙升 | 每日成本超过 7 天平均值的 150% | 警告 |
| 小时成本异常 | 小时成本超过小时平均值的 3 倍 | 警告 |
| 成本集中 | 单个模型超过总支出的 60% | 警告 |
| Token 量飙升 | 1 小时内总 token 超过基线的 2 倍 | 警告 |
| 错误率成本浪费 | 错误率超过 5%(为失败调用付费) | 警告 |
| 角色预算 | 任何角色的每日支出超过其 7 天平均值的 2 倍 | 警告 |
| Token 比例失衡 | 输入输出比超过 20:1 持续 1 小时 | 警告 |
| 高 token 调用 | 任何单次调用超过 20,000 token | 警告 |
其他资源
- GenAI Observability on AWS — 配套指南:策略、管道、启用方法、dashboard
- Model Invocations — CloudWatch
- Getting Started with AgentCore Observability
- CloudWatch Logs Insights Query Syntax
- OpenSearch SQL in CloudWatch Logs Insights
- AWS Bedrock Pricing
贡献者: AWS Observability Team 最后更新: 2026-04-21