클라우드 애그노스틱 AI Observability 플랫폼 - 아키텍처
개요
이 문서는 AWS 관리형 서비스를 기반으로 구축된 클라우드 애그노스틱 AI Observability 플랫폼의 아키텍처를 설명합니다. 이 플랫폼은 여러 클라우드 프로바이더에 걸친 Large Language Model (LLM) 워크로드에 대해 통합 모니터링, 비용 최적화, 운영 인사이트를 제공합니다.
아키텍처 다이어그램
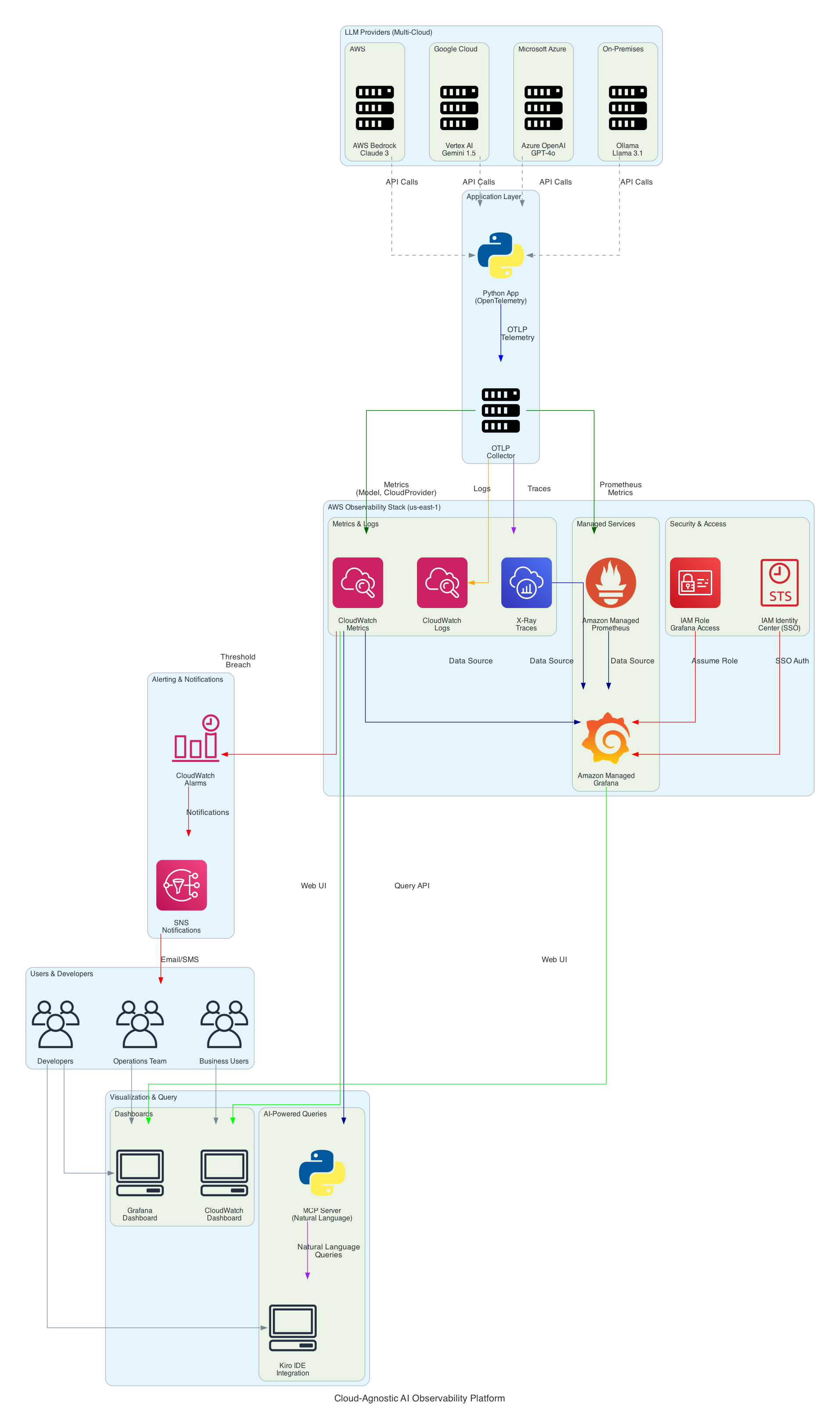
아키텍처 구성 요소
1. LLM Providers Layer (멀티 클라우드)
이 플랫폼은 여러 프로바이더에 걸친 LLM 호출 모니터링을 지원합니다:
아래 나열된 모델은 이 데모에서 사용된 것입니다. 이 플랫폼은 AI 게이트웨이로 LiteLLM을 사용하므로, LiteLLM이 지원하는 모든 LLM으로 대체할 수 있습니다 — gateway/litellm-config.yaml을 원하는 모델로 업데이트하기만 하면 됩니다. Observability 파이프라인은 어떤 모델을 선택하든 동일하게 작동합니다.
AWS Bedrock
- 모델: Claude 3 Haiku, Claude 3 Sonnet
- 통합: AWS SDK (boto3)
- 메트릭: 토큰 사용량, 지연시간, 요청 수
- 차원:
CloudProvider=aws
Google Vertex AI
- 모델: Gemini 1.5 Pro, Gemini 1.5 Flash
- 통합: 시뮬레이션 (프로덕션에서는 Google Cloud SDK 사용)
- 메트릭: 토큰 사용량, 지연시간, 요청 수
- 차원:
CloudProvider=gcp
Azure OpenAI
- 모델: GPT-4o, GPT-4o Mini
- 통합: 시뮬레이션 (프로덕션에서는 Azure SDK 사용)
- 메트릭: 토큰 사용량, 지연시간, 요청 수
- 차원:
CloudProvider=azure
On-Premises (Ollama)
- 모델: Llama 3.1 70B, Mistral 7B
- 통합: 시뮬레이션 (프로덕션에서는 Ollama API 사용)
- 메트릭: 토큰 사용량, 지연시간, 요청 수
- 차원:
CloudProvider=on-prem
2. Application Layer
Python 애플리케이션
- 프레임워크: 계측을 위한 OpenTelemetry SDK
- 언어: Python 3.8+
- 역할:
- 프로바이더별 LLM API 호출
- 텔레메트리 수집 (메트릭, 트레이스, 로그)
- OpenTelemetry Collector로 데이터 전송
OpenTelemetry Collector
- 프로토콜: OTLP (OpenTelemetry Protocol)
- 형식: 클라우드 애그노스틱, 벤더 중립적
- 역할:
- 애플리케이션에서 텔레메트리 수신
- 데이터 변환 및 보강
- AWS 서비스로 내보내기
3. AWS Observability 스택
Amazon CloudWatch
- 서비스 유형: 관리형 메트릭 및 모니터링
- 리전: us-east-1
- 네임스페이스:
AIObservability - 메트릭:
InputTokens- 프롬프트의 토큰 수OutputTokens- 완성의 토큰 수Latency- 밀리초 단위 응답 시간
- 차원:
Model- LLM 모델 식별자CloudProvider- 프로바이더 (aws, gcp, azure, on-prem)
- 보존 기간: 15개월 (기본값)
- 비용: 메트릭당 월 $0.30 (처음 10,000 메트릭 무료)
AWS X-Ray
- 서비스 유형: 분산 트레이싱
- 리전: us-east-1
- 역할:
- 서비스 간 요청 흐름 추적
- 성능 병목현상 식별
- 서비스 의존성 시각화
- 트레이스 형식: X-Ray segment documents
- 보존 기간: 30일
- 비용: 기록된 100만 트레이스당 $5.00
CloudWatch Logs
- 서비스 유형: 로그 집계 및 분석
- 리전: us-east-1
- 로그 그룹:
/ai-observability-demo - 형식: JSON 구조화 로그
- 기능:
- 쿼리를 위한 CloudWatch Logs Insights
- 로그 보존 정책
- 알림을 위한 메트릭 필터
- 보존 기간: 7일 (구성 가능)
- 비용: 수집된 GB당 $0.50
Amazon Managed Prometheus (AMP)
- 서비스 유형: 관리형 Prometheus 호환 모니터링
- 리전: us-east-1
- Workspace ID:
<your-amp-workspace-id> - 용도: 시계열 메트릭 스토리지
- 쿼리 언어: PromQL
- 보존 기간: 150일
- 비용: 수집된 100만 샘플당 $0.10
Amazon Managed Grafana (AMG)
- 서비스 유형: 시각화를 위한 관리형 Grafana
- 리전: us-east-1
- Workspace ID:
<your-amg-workspace-id> - 인증: IAM Identity Center (SSO)
- 데이터 소스:
- Amazon CloudWatch
- AWS X-Ray
- Amazon Managed Prometheus
- 기능:
- 템플릿 변수를 활용한 동적 대시보드
- 멀티 클라우드 필터링
- 자동 새로고침 (30초)
- 비용: 활성 사용자당 월 $9.00
4. 보안 및 접근 제어
IAM Role (Grafana 접근)
- 역할 이름:
ai-observability-grafana-role - 목적: Grafana가 AWS 서비스를 쿼리할 수 있도록 허용
- 관리형 정책:
CloudWatchReadOnlyAccessAWSXRayReadOnlyAccessAmazonPrometheusQueryAccess
- 신뢰 정책: Grafana 워크스페이스가 역할을 수임할 수 있도록 허용
- 최소 권한 원칙: 읽기 전용 접근만 허용
IAM Identity Center (SSO)
- 리전: us-east-2 (Ohio)
- 목적: Grafana 사용자를 위한 싱글 사인온
- 사용자:
<your-email>(ADMIN 역할) - 통합: SAML 2.0 인증
- 장점:
- 중앙 집중식 사용자 관리
- MFA 지원
- 감사 로깅
5. 시각화 및 쿼리 레이어
Grafana 대시보드
- 유형: 템플릿 변수를 활용한 동적 대시보드
- 파일:
grafana/dashboards/ai-observability-dynamic.json - 기능:
- Cloud Provider 드롭다운 (자동 검색: aws, gcp, azure, on-prem)
- Model 드롭다운 (모든 모델 자동 검색)
- 다중 선택 필터
- 실시간 메트릭 (30초 새로고침)
- 패널:
- 모델별 Input Tokens (시계열)
- 모델별 Output Tokens (시계열)
- 모델별 Latency (시계열)
- 총 요청 수 (stat)
- 평균 지연시간 (stat)
CloudWatch 대시보드
- 이름:
AI-Observability-Demo - 유형: 네이티브 CloudWatch 대시보드
- 위젯:
- Input/Output 토큰 메트릭
- 지연시간 통계
- 요청 수
- 차원: Model 및 CloudProvider
- 접근: AWS Console
MCP Server (자연어 쿼리)
- 기술: Model Context Protocol
- 언어: Python 3.8+
- 통합: Kiro IDE
- 도구:
get_token_usage- 토큰 소비량 쿼리get_model_latency- 지연시간 통계 쿼리get_request_count- 요청 볼륨 쿼리get_cost_estimate- 비용 추정compare_models- 모델 간 비교
- 쿼리 예시:
- "어떤 모델이 가장 많은 토큰을 소비하고 있나요?"
- "Claude Haiku의 평균 지연시간은 얼마인가요?"
- "지난 1시간 동안의 LLM 비용을 추정해 주세요"
Kiro IDE 통합
- 목적: 개발자 중심 Observability
- 기능:
- IDE 내 자연어 쿼리
- 대시보드 전환 불필요
- 개발 중 실시간 메트릭
- 구성:
kiro-mcp-config.json
6. 알림 및 통지
CloudWatch Alarms
- 목적: 사전 예방적 모니터링 및 알림
- 알람 유형:
- 비용 임계값 초과
- 지연시간 SLA 위반
- 오류율 증가
- 토큰 사용량 이상
- 동작: SNS 알림 트리거
Amazon SNS
- 목적: 다채널 알림
- 채널:
- 이메일
- SMS
- Slack (webhook 경유)
- PagerDuty 통합
- 구독자: 운영 팀
데이터 흐름
1. LLM 호출 흐름
User Request → Application → LLM Provider API
↓
OpenTelemetry SDK
↓
(Collect Telemetry)
↓
OTLP Collector
2. 텔레메트리 내보내기 흐름
OTLP Collector → CloudWatch (Metrics)
→ X-Ray (Traces)
→ CloudWatch Logs (Logs)
→ Prometheus (Time Series)
3. 시각화 흐름
CloudWatch/X-Ray/Prometheus → Grafana → Users
→ CloudWatch Dashboard → Users
4. 쿼리 흐름 (MCP)
Developer → Kiro IDE → MCP Server → CloudWatch API → Response
5. 알림 흐름
CloudWatch Metrics → Alarm Threshold → SNS → Operations Team
주요 설계 결정
1. 클라우드 애그노스틱 접근법
결정: OpenTelemetry를 계측 표준으로 사용
근거:
- 벤더 중립적, 오픈소스 표준
- 모든 LLM 프로바이더와 호환
- 프로바이더 변경에 대비한 미래 보장
- 클라우드 플랫폼 간 이식 가능
트레이드오프:
- 추가 추상화 레이어
- OTLP collector 설정 필요
- OpenTelemetry 학습 곡선
2. AWS 관리형 서비스
결정: 자체 호스팅 대신 Amazon Managed Grafana 및 Prometheus 사용
근거:
- 인프라 관리 부담 없음
- 내장된 고가용성 및 확장성
- 자동 패치 및 업데이트
- AWS 네이티브 보안 통합
- 사용량 기반 과금 모델
트레이드오프:
- 자체 호스팅보다 높은 비용 (대규모의 경우)
- 커스터마이징 유연성 감소
- AWS 리전 의존성
3. 차원 메트릭
결정: 메트릭 이름 접두사 대신 CloudWatch 차원(Model, CloudProvider) 사용
근거:
- 유연한 쿼리 및 집계
- 효율적인 스토리지 (메트릭 폭발 방지)
- Grafana에서 동적 필터링 지원
- 새 차원 추가 용이
트레이드오프:
- CloudWatch 차원 제한 (메트릭당 30개)
- 신중한 차원 설계 필요
- 쿼리 복잡도 증가
4. SSO를 위한 IAM Identity Center
결정: Grafana 네이티브 인증 대신 IAM Identity Center 사용
근거:
- 중앙 집중식 사용자 관리
- 기본 제공 MFA 지원
- 컴플라이언스를 위한 감사 로깅
- 기업 ID 프로바이더와 통합
트레이드오프:
- 추가 AWS 서비스 의존성
- 설정 복잡도
- 리전 제약 (us-east-2)
5. 자연어 쿼리를 위한 MCP
결정: 기존 쿼리 도구 대신 커스텀 MCP 서버 구축
근거:
- 개발자 중심 경험
- 컨텍스트 전환 감소
- 자연어 인터페이스
- IDE 통합
트레이드오프:
- 유지보수할 커스텀 코드
- 지원되는 IDE로 제한
- MCP 프로토콜 지식 필요
확장성 고려사항
메트릭 볼륨
현재 규모:
- 호출당 3개 메트릭 (InputTokens, OutputTokens, Latency)
- 메트릭당 2개 차원 (Model, CloudProvider)
- 데모에서 분당 ~10회 호출
프로덕션 규모 추정:
- 초당 1,000회 호출
- 분당 180,000 메트릭 데이터 포인트
- 일당 2억 5,900만 데이터 포인트
CloudWatch 제한:
- 계정/리전당 초당 1,000 트랜잭션 (TPS)
- API당 150 TPS (PutMetricData)
- 해결책: 배치 처리 사용 (요청당 최대 1,000 메트릭)
비용 최적화
전략:
- 메트릭 집계: CloudWatch로 전송하기 전에 메트릭 사전 집계
- 샘플링: 높은 볼륨 워크로드에서 트레이스 샘플링 (예: 요청의 10%)
- 보존 정책: 비중요 로그의 보존 기간 단축
- 예약 용량: 예측 가능한 워크로드에 Savings Plans 사용
월간 예상 비용 (일 100만 호출):
- CloudWatch Metrics: ~$90
- CloudWatch Logs: ~$15
- X-Ray: ~$150
- Amazon Managed Grafana: 사용자당 $9
- Amazon Managed Prometheus: ~$30
- 합계: ~$300/월 + 사용자당 $9
고가용성
내장 HA:
- CloudWatch: 기본 Multi-AZ
- X-Ray: 기본 Multi-AZ
- Amazon Managed Grafana: Multi-AZ 배포
- Amazon Managed Prometheus: Multi-AZ 배포
애플리케이션 HA:
- 여러 AZ에 걸친 애플리케이션 배포
- 분산을 위한 Application Load Balancer 사용
- 지수 백오프를 활용한 재시도 로직 구현
보안 모범 사례
1. 최소 권한 접근
- Grafana 역할은 AWS 서비스에 대한 읽기 전용 접근만 보유
- CloudWatch, X-Ray, Prometheus에 대한 쓰기 권한 없음
- 사용자 그룹별 별도 역할
2. 암호화
- 저장 시: AWS KMS로 암호화된 CloudWatch Logs
- 전송 ��시: 모든 API 호출에 TLS 1.2+
- Grafana: 유효한 SSL 인증서를 사용한 HTTPS만 허용
3. 네트워크 보안
- AWS 관리형 VPC의 Grafana 워크스페이스
- 백엔드 서비스에 대한 퍼블릭 인터넷 접근 없음
- AWS 서비스 접근을 위한 VPC 엔드포인트 (선택사항)
4. 감사 로깅
- 모든 API 호출을 CloudTrail로 로깅
- CloudWatch에 Grafana 접근 로그
- IAM Identity Center 감사 로그
5. 시크릿 관리
- IAM 역할을 통한 AWS 자격 증명 (하드코딩된 키 없음)
- AWS Secrets Manager에 LLM API 키 저장
- 자동 키 로테이션 정책
모니터링 시스템의 모니터링
메타 모니터링
플랫폼 상태를 위한 CloudWatch Metrics:
- Grafana 워크스페이스 상태
- Prometheus 워크스페이스 상태
- API 호출 성공률
- 쿼리 지연시간
알람:
- Grafana 워크스페이스 사용 불가
- CloudWatch API 스로틀링
- X-Ray 트레이스 수집 실패
재해 복구
백업 전략
CloudWatch:
- 메트릭: 15개월 보존 (백업 불필요)
- 로그: 장기 보존을 위해 S3로 내보내기
- 대시보드: Git에서 버전 관리
Grafana:
- 대시보드: JSON으로 내보내기, Git에 저장
- 데이터 소스: 코드로 구성 (Terraform)
- 사용자: IAM Identity Center를 통해 관리
복구 시간 목표 (RTO): 1시간 복구 시점 목표 (RPO): 5분
재해 복구 Plan
- 인프라: Terraform을 통해 재배포
- 대시보드: Git 저장소에서 임포트
- 데이터: CloudWatch 데이터 유지 (조치 불필요)
- 사용자: IAM Identity Center를 통해 재할당
향후 개선 사항
단기 (1-3개월)
- 이상 탐지: ML 기반 비정상 패턴 알림
- 비용 예측: 트렌드 기반 월간 비용 예측
- SLO 추적: Service Level Objective 모니터링
- 멀티 리전: AWS 리전 간 메트릭 집계
중기 (3-6개월)
- 고급 분석: BigQuery/Athena 통합
- 커스텀 대시보드: 팀별 뷰
- 통합 테스트: 자동화된 Observability 테스트
- API Gateway: 외부 통합을 위한 RESTful API
장기 (6-12개월)
- AI 기반 인사이트: 자동화된 근본 원인 분석
- 예측 스케일링: 예측 기반 할당량 자동 조정
- 비용 최적화 엔진: 자동 모델 선택
- 컴플라이언스 자동화: 자동화된 감사 보고서
참고 자료
AWS 서비스 문서
표준 및 프로토콜
관련 패턴
문서 버전: 1.0
최종 업데이트: 2026년 2월
관리: AWS Solutions Architecture Team