云无关 AI 可观测性平台 - 架构
概述
本文档描述了基于 AWS 托管服务构建的云无关 AI 可观测性平台的架构。该平台为跨多个云提供商的大语言模型 (LLM) 工作负载提供统一监控、成本优化和运营洞察。
架构图
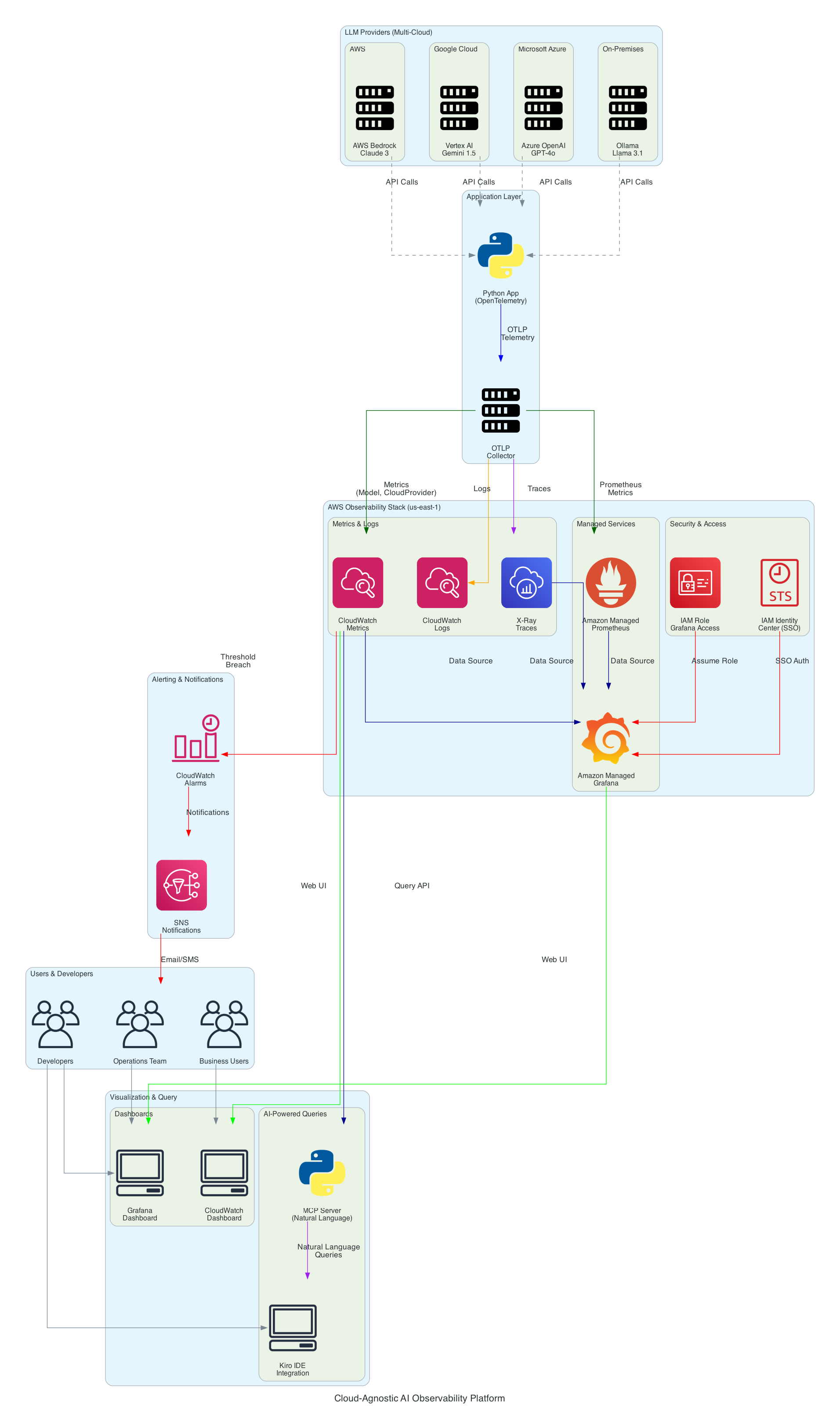
架构组件
1. LLM 提供商层(多云)
该平台支持跨多个提供商监控 LLM 调用:
模型灵活性
以下列出的模型是此演示中使用的模型。由于该平台使用 LiteLLM 作为 AI 网关,您可以替换 LiteLLM 支持的任何 LLM — 只需使用您首选的模型更新 gateway/litellm-config.yaml。无论您选择哪些模型,可观测性管道的工作方式都相同。
AWS Bedrock
- 模型:Claude 3 Haiku、Claude 3 Sonnet
- 集成:AWS SDK (boto3)
- Metrics:Token 使用量、延迟、请求计数
- 维度:
CloudProvider=aws
Google Vertex AI
- 模型:Gemini 1.5 Pro、Gemini 1.5 Flash
- 集成:模拟(生产环境使用 Google Cloud SDK)
- Metrics:Token 使用量、延迟、请求计数
- 维度:
CloudProvider=gcp
Azure OpenAI
- 模型:GPT-4o、GPT-4o Mini
- 集成:模拟(生产环境使用 Azure SDK)
- Metrics:Token 使用量、延迟、请求计数
- 维度:
CloudProvider=azure
本地部署 (Ollama)
- 模型:Llama 3.1 70B、Mistral 7B
- 集成:模拟(生产环境使用 Ollama API)
- Metrics:Token 使用量、延迟、请求计数
- 维度:
CloudProvider=on-prem
2. 应用层
Python 应用
- 框架:OpenTelemetry SDK 用于检测
- 语言:Python 3.8+
- 职责:
- 跨提供商调用 LLM API
- 收集遥测数据(metrics、traces、logs)
- 将数据发送到 OpenTelemetry Collector
OpenTelemetry Collector
- 协议:OTLP (OpenTelemetry Protocol)
- 格式:云无关、供应商中立
- 职责:
- 接收来自应用的遥测数据
- 转换和丰富数据
- 导出到 AWS 服务
3. AWS 可观测性堆栈
Amazon CloudWatch
- 服务类型:托管 metrics 和监控
- 区域:us-east-1
- 命名空间:
AIObservability - Metrics:
InputTokens- 提示词的 token 计数OutputTokens- 补全内容的 token 计数Latency- 响应时间(毫秒)
- 维度:
Model- LLM 模型标识符CloudProvider- 提供商 (aws, gcp, azure, on-prem)
- 保留期:15 个月(默认)
- 成本:每个 metric 每月 $0.30(前 10,000 个 metrics 免费)
AWS X-Ray
- 服务类型:分布式追踪
- 区域:us-east-1
- 职责:
- 跟踪跨服务的请求流
- 识别性能瓶颈
- 可视化服务依赖关系
- Trace 格式:X-Ray segment 文档
- 保留期:30 天
- 成本:每百万条 traces 记录 $5.00
CloudWatch Logs
- 服务类型:日志聚合和分析
- 区域:us-east-1
- 日志组:
/ai-observability-demo - 格式:JSON 结构化日志
- 功能:
- CloudWatch Logs Insights 用于查询
- 日志保留策略
- Metric 过滤器用于告警
- 保留期:7 天(可配置)
- 成本:每 GB 摄取 $0.50
Amazon Managed Prometheus (AMP)
- 服务类型:托管的 Prometheus 兼容监控
- 区域:us-east-1
- 工作区 ID:
<your-amp-workspace-id> - 用例:时间序列 metrics 存储
- 查询语言:PromQL
- 保留期:150 天
- 成本:每百万样本摄取 $0.10
Amazon Managed Grafana (AMG)
- 服务类型:托管 Grafana 用于可视化
- 区域:us-east-1
- 工作区 ID:
<your-amg-workspace-id> - 认证:IAM Identity Center (SSO)
- 数据源:
- Amazon CloudWatch
- AWS X-Ray
- Amazon Managed Prometheus
- 功能:
- 带模板变量的动态 dashboard
- 多云过滤
- 自动刷新(30 秒)
- 成本:每活跃用户每月 $9.00
4. 安全和访问控制
IAM 角色(Grafana 访问)
- 角色名称:
ai-observability-grafana-role - 用途:允许 Grafana 查询 AWS 服务
- 托管策略:
CloudWatchReadOnlyAccessAWSXRayReadOnlyAccessAmazonPrometheusQueryAccess
- 信任策略:允许 Grafana 工作区承担角色
- 最小权限原则:仅只读访问
IAM Identity Center (SSO)
- 区域:us-east-2 (Ohio)
- 用途:Grafana 用户的单点登录
- 用户:
<your-email>(ADMIN 角色) - 集成:SAML 2.0 认证
- 优势:
- 集中用户管理
- MFA 支持
- 审计日志
5. 可视化和查询层
Grafana Dashboard
- 类型:带模板变量的动态 dashboard
- 文件:
grafana/dashboards/ai-observability-dynamic.json - 功能:
- Cloud Provider 下拉菜单(自动发现:aws、gcp、azure、on-prem)
- Model 下拉菜单(自动发现所有模型)
- 多选过滤器
- 实时 metrics(30 秒刷新)
- 面板:
- 按模型统计的 Input Tokens(时间序列)
- 按模型统计的 Output Tokens(时间序列)
- 按模型统计的延迟(时间序列)
- 总请求数(统计值)
- 平均延迟(统计值)
CloudWatch Dashboard
- 名称:
AI-Observability-Demo - 类型:原生 CloudWatch dashboard
- Widget:
- Input/Output token metrics
- 延迟统计
- 请求计数
- 维度:Model 和 CloudProvider
- 访问:AWS 控制台
MCP Server(自然语言查询)
- 技术:Model Context Protocol
- 语言:Python 3.8+
- 集成:Kiro IDE
- 工具:
get_token_usage- 查询 token 消耗get_model_latency- 查询延迟统计get_request_count- 查询请求量get_cost_estimate- 估算成本compare_models- 并行比较
- 查询示例:
- "哪个模型消耗的 token 最多?"
- "Claude Haiku 的平均延迟是多少?"
- "估算过去一小时的 LLM 成本"
Kiro IDE 集成
- 用途:以开发者为中心的可观测性
- 功能:
- IDE 中的自然语言查询
- 无需切换到 dashboard
- 开发期间的实时 metrics
- 配置:
kiro-mcp-config.json
6. 告警和通知
CloudWatch Alarms
- 用途:主动监控和告警
- 告警类型:
- 成本阈值突破
- 延迟 SLA 违规
- 错误率上升
- Token 使用异常
- 操作:触发 SNS 通知
Amazon SNS
- 用��途:多渠道通知
- 渠道:
- 电子邮件
- SMS
- Slack(通过 webhook)
- PagerDuty 集成
- 订阅者:运维团队
数据流
1. LLM 调用流
User Request → Application → LLM Provider API
↓
OpenTelemetry SDK
↓
(Collect Telemetry)
↓
OTLP Collector
2. 遥测数据导出流
OTLP Collector → CloudWatch (Metrics)
→ X-Ray (Traces)
→ CloudWatch Logs (Logs)
→ Prometheus (Time Series)
3. 可视化流
CloudWatch/X-Ray/Prometheus → Grafana → Users
→ CloudWatch Dashboard → Users
4. 查询流 (MCP)
Developer → Kiro IDE → MCP Server → CloudWatch API → Response
5. 告警流
CloudWatch Metrics → Alarm Threshold → SNS → Operations Team
关键设计决策
1. 云无关方法
决策:使用 OpenTelemetry 作为检测标准
理由:
- 供应商中立的开源标准
- 适用于任何 LLM 提供商
- 面向未来,不受提供商变更影响
- 可跨云平台移植
权衡:
- 额外的抽象层
- 需要 OTLP collector 设置
- OpenTelemetry 学习曲线
2. AWS 托管服务
决策:使用 Amazon Managed Grafana 和 Prometheus 而非自托管
理由:
- 无基础设施管理开销
- 内置高可用性和可扩展性
- 自动补丁和更新
- AWS 原生安全集成
- 按使用量付费的定价模型
权衡:
- 比自托管成本更高(大规模时)
- 自定义灵活性较低
- AWS 区域依赖
3. 维度 Metrics
决策:使用 CloudWatch 维度(Model、CloudProvider)而非 metric 名称前缀
理由:
- 灵活的查询和聚合
- 高效存储(无 metric 爆炸��)
- 支持 Grafana 中的动态过滤
- 易于添加新维度
权衡:
- CloudWatch 维度限制(每个 metric 30 个)
- 需要仔细的维度设计
- 查询复杂性增加
4. 用于 SSO 的 IAM Identity Center
决策:使用 IAM Identity Center 而非 Grafana 原生认证
理由:
- 集中用户管理
- 开箱即用的 MFA 支持
- 合规审计日志
- 与企业身份提供商集成
权衡:
- 额外的 AWS 服务依赖
- 设置复杂性
- 区域限制 (us-east-2)
5. 用于自然语言查询的 MCP
决策:构建自定义 MCP server 而非使用现有查询工具
理由:
- 以开发者为中心的体验
- 减少上下文切换
- 自然语言界面
- IDE 集成
权衡:
- 需要维护自定义代码
- 仅限支持的 IDE
- 需要 MCP 协议知识
可扩展性考虑
Metrics 量
当前规模:
- 每次调用 3 个 metrics(InputTokens、OutputTokens、Latency)
- 每个 metric 2 个维度(Model、CloudProvider)
- 演示中约每分钟 10 次调用
生产规模估算:
- 每秒 1,000 次调用
- 每分钟 180,000 个 metric 数据点
- 每天 2.59 亿个数据点
CloudWatch 限制:
- 每个账户每个区域 1,000 TPS(每秒事务数)
- 每个 API(PutMetricData)150 TPS
- 解决方案:使用批处理(每个请求最多 1,000 个 metrics)
成本优化
策略:
- Metric 聚合:在发送到 CloudWatch 之前预聚合 metrics
- 采样:对高流量工作负载采样 traces(例如 10% 的请求)
- 保留策略:减少非关键日志的保留时间
- 预留容量:对可预测的工作负载使用 Savings Plans
估计月成本(每天 100 万次调用):
- CloudWatch Metrics:~$90
- CloudWatch Logs:~$15
- X-Ray:~$150
- Amazon Managed Grafana:每用户 $9
- Amazon Managed Prometheus:~$30
- 总计:~$300/月 + 每用户 $9
高可用性
内置 HA:
- CloudWatch:默认多 AZ
- X-Ray:默认多 AZ
- Amazon Managed Grafana:��多 AZ 部署
- Amazon Managed Prometheus:多 AZ 部署
应用 HA:
- 跨多个 AZ 部署应用
- 使用 Application Load Balancer 进行分发
- 实现带指数退避的重试逻辑
安全最佳实践
1. 最小权限访问
- Grafana 角色仅对 AWS 服务具有只读访问权限
- 无 CloudWatch、X-Ray 或 Prometheus 的写入权限
- 不同用户组的独立角色
2. 加密
- 静态加密:CloudWatch Logs 使用 AWS KMS 加密
- 传输加密:所有 API 调用使用 TLS 1.2+
- Grafana:仅 HTTPS,具有有效 SSL 证书
3. 网络安全
- Grafana 工作区位于 AWS 托管的 VPC 中
- 后端服务无公共互联网访问
- 用于 AWS 服务访问的 VPC endpoint(可选)
4. 审计日志
- CloudTrail 记录所有 API 调用
- Grafana 访问日志在 CloudWatch 中
- IAM Identity Center 审计日志
5. 密钥管理
- 通过 IAM 角色获取 AWS 凭证(无硬编码密钥)
- LLM API 密钥存储在 AWS Secrets Manager 中
- 自动密钥轮换策略
监控监控系统
元监控
平台健康状况的 CloudWatch Metrics:
- Grafana 工作区状态
- Prometheus 工作区状态
- API 调用成功率
- 查询延迟
告警:
- Grafana 工作区不可用
- CloudWatch API 限流
- X-Ray trace 摄取失败
灾难恢复
备份策略
CloudWatch:
- Metrics:保留 15 个月(无需备份)
- Logs:导出到 S3 用于长期保留
- Dashboard:在 Git 中进行版本控制
Grafana:
- Dashboard:导出为 JSON,存储在 Git 中
- 数据源:配置即代码(Terraform)
- 用户:通过 IAM Identity Center 管理
恢复时间目标 (RTO):1 小时 恢复点目标 (RPO):5 分钟
灾难恢复计划
- 基础设施:通过 Terraform 重新部署
- Dashboard:从 Git 仓库导入
- 数据:CloudWatch 数据持久化(无需操作)
- 用户:通过 IAM Identity Center 重新分配
未来增强
短期(1-3 个月)
- 异常检测:基于 ML 的异常模式告警
- 成本预测:基于趋势预测月度成本
- SLO 跟踪:服务级别目标监控
- 多区域:跨 AWS 区域聚合 metrics
中期(3-6 个月)
- 高级分析:BigQuery/Athena 集成
- 自定义 Dashboard:团队特定视图
- 集成测试:自动化可观测性测试
- API Gateway:用于外部集成的 RESTful API
长期(6-12 个月)
- AI 驱动的洞察:自动化根因分析
- 预测性扩展:基于预测自动调整配额
- 成本优化引擎:自动化模型选择
- 合规自动化:自动化审计报告
参考资料
AWS 服务文档
标准和协议
相关模式
文档版本:1.0 最后更新:2026 年 2 月 维护者:AWS Solutions Architecture Team