EKS 클러스터 전체 GPU 비용 할당
이 문서에서는 Amazon EKS에서 GPU 슬라이스 비용 할당을 위한 엔드투엔드 개념 증명(PoC)을 설명합니다.
문제 정의
여러 테넌트가 GPU 용량(예: MIG 슬라이스)을 공유할 때 다음 질문에 답해야 합니다:
- 누가 어떤 GPU 지분을 요청했는가 (파드 / 네임스페이스 / BU별)?
- 누가 실제로 GPU를 사용했는가 (�그리고 얼마나)?
- GPU 시간당 $12와 같은 "공개" 가격이 주어졌을 때 어떻게 계산하는가:
- 할당 비용 (요청된 지분 기반)
- 실효 비용 (관찰된 사용률 기반)
- 낭비 (할당 - 실효)
아키텍처 (고수준)
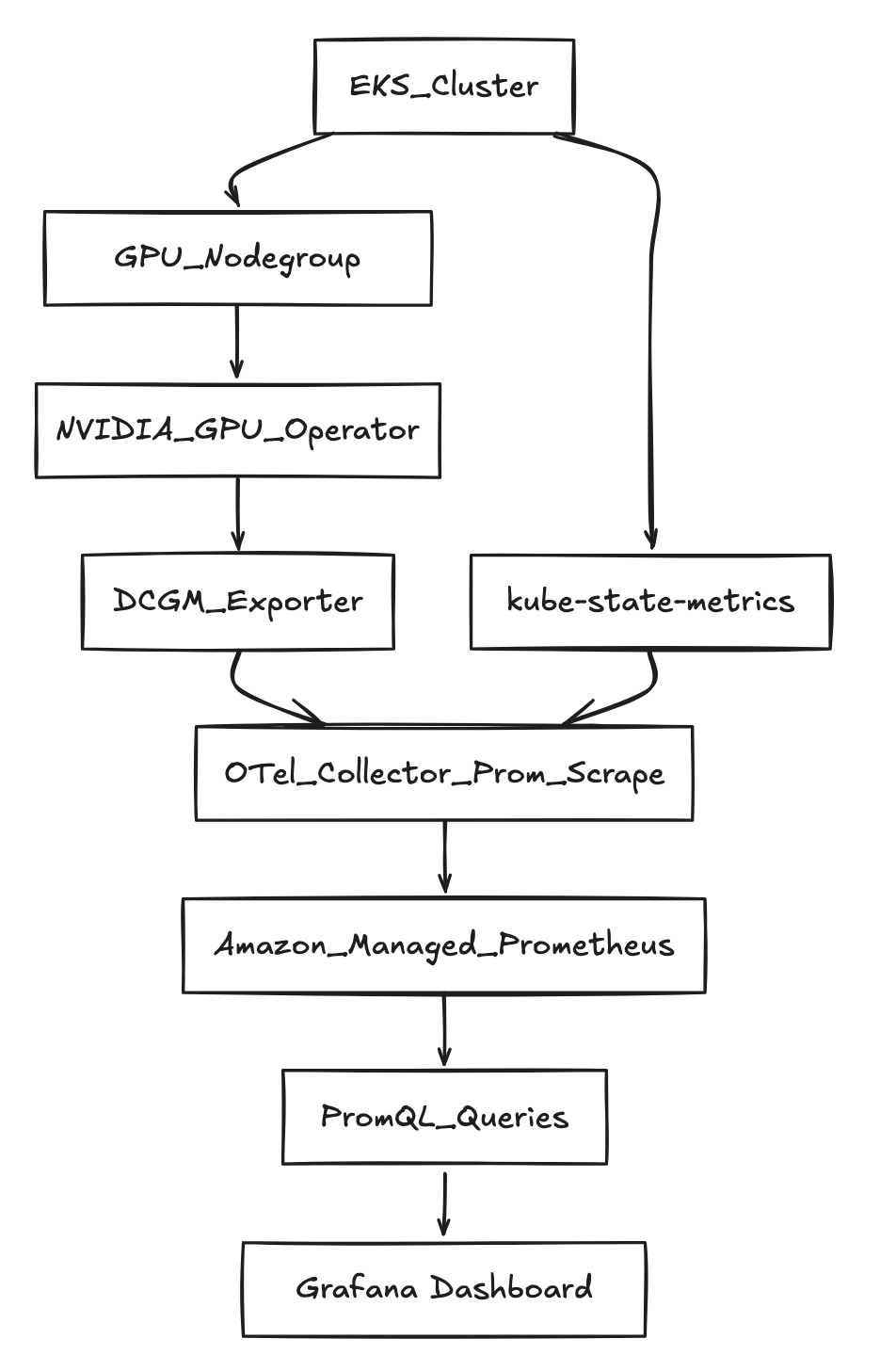
사전 요구사항
AWS + EKS 사전 요구사항
- 다음을 생성할 수 있는 권한이 있는 AWS 계정:
- EKS 클러스터 + 노드그룹
- 서비스 계정용 IAM 역할 (IRSA)
- AMP 워크스페이스
- 리전에서 GPU 인스턴스를 실행하기 위한 할당량 및 AZ 용량
사용되는 변수
export AWS_REGION="us-west-2"
export CLUSTER_NAME="gpu-cost-poc"
export AMP_ALIAS="gpu-cost-poc"
# 시연하려는 공개/벤치마크 가격 (아직 CUR이 아님)
export GPU_HOURLY_RATE="12"
# PoC를 위한 MIG 프로파일 (예: A100 40GB는 일반적으로 7개 슬라이스/GPU로 1g.5gb 지원)
export MIG_PROFILE_LABEL="all-1g.5gb"
# 중요: 이 PoC에서 MIG 슬라이스는 nvidia.com/gpu로 노출됨 (1 "gpu" == 1 MIG 슬라이스)
export MIG_RESOURCE_KEY="nvidia.com/gpu"
# A100에서 1g.5gb의 경우: 물리적 GPU당 일반적으로 7개 슬라이스
export SLICES_PER_GPU="7"
# kube-state-metrics는 확장 리소스 이름을 "정리"할 수 있음
export KSM_RESOURCE_REGEX='nvidia.*(gpu|mig).*'
단계별 지침
단계 1 — EKS 클러스터 생성
eksctl이 지원하는 버전 목록 확인:
eksctl utils describe-cluster-versions
클러스터 생성 (--version을 생략하면 eksctl이 지원되는 기본값을 선택):
eksctl create cluster \
--name "$CLUSTER_NAME" \
--region "$AWS_REGION" \
--managed
단계 2 — "시스템" 노드그룹 추가 (권장)
CoreDNS와 operator를 고비용 GPU 노드에서 분리합니다.
eksctl create nodegroup \
--cluster "$CLUSTER_NAME" \
--region "$AWS_REGION" \
--name "system-ng" \
--node-type "m5.large" \
--nodes 2 --nodes-min 2 --nodes-max 3
단계 3 — GPU 노드그룹 추가
eksctl create nodegroup \
--cluster "$CLUSTER_NAME" \
--region "$AWS_REGION" \
--name "gpu-ng-ubuntu" \
--node-type "p4d.24xlarge" \
--node-ami-family "Ubuntu2204" \
--install-nvidia-plugin=false \
--nodes 1 --nodes-min 1 --nodes-max 1 \
--node-labels "workload=gpu"
GPU 워크로드만 스케줄링되도록 taint 적용:
kubectl taint nodes -l workload=gpu nvidia.com/gpu=present:NoSchedule --overwrite
단계 4 — NVIDIA GPU Operator 설치 (MIG 활성화)
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm upgrade --install gpu-operator nvidia/gpu-operator \
-n gpu-operator --create-namespace \
--set mig.strategy=single
단계 5 — GPU 노드에 MIG 프로파일 활성화
현재 MIG 레이블 확인:
kubectl get nodes -l workload=gpu -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.nvidia\.com/mig\.capable}{"\t"}{.metadata.labels.nvidia\.com/mig\.config}{"\t"}{.metadata.labels.nvidia\.com/mig\.config\.state}{"\n"}{end}'
MIG 지오메트리 적용:
kubectl label nodes -l workload=gpu nvidia.com/mig.config="$MIG_PROFILE_LABEL" --overwrite
성공 대기:
kubectl get nodes -l workload=gpu -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.nvidia\.com/mig\.config}{"\t"}{.metadata.labels.nvidia\.com/mig\.config\.state}{"\n"}{end}'
단계 6 — AMP 워크스페이스 생성
aws amp create-workspace --alias "$AMP_ALIAS" --region "$AWS_REGION"
export AMP_WORKSPACE_ID="$(aws amp list-workspaces --region "$AWS_REGION" --query "workspaces[?alias=='$AMP_ALIAS'].workspaceId | [0]" --output text)"
export AMP_ENDPOINT="$(aws amp describe-workspace --workspace-id "$AMP_WORKSPACE_ID" --region "$AWS_REGION" --query "workspace.prometheusEndpoint" --output text)"
echo "$AMP_WORKSPACE_ID"
echo "$AMP_ENDPOINT"
단계 7 — 수집 + 쿼리를 위한 IRSA
eksctl utils associate-iam-oidc-provider \
--cluster "$CLUSTER_NAME" \
--region "$AWS_REGION" \
--approve
eksctl create iamserviceaccount \
--cluster "$CLUSTER_NAME" --region "$AWS_REGION" \
--name amp-ingest --namespace observability \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusRemoteWriteAccess \
--approve --override-existing-serviceaccounts
eksctl create iamserviceaccount \
--cluster "$CLUSTER_NAME" --region "$AWS_REGION" \
--name amp-query --namespace observability \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonPrometheusQueryAccess \
--approve --override-existing-serviceaccounts
단계 8 — kube-state-metrics 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade --install kube-state-metrics prometheus-community/kube-state-metrics \
-n kube-system
단계 9 — OTel Collector 배포 (Prometheus 스크레이프 → AMP remote_write)
kubectl -n observability patch configmap amp-scraper-otel-env --type merge -p "$(cat <<PATCH
{
"data": {
"AWS_REGION": "${AWS_REGION}",
"AMP_ENDPOINT": "${AMP_ENDPOINT}"
}
}
PATCH
)"
kubectl -n observability rollout restart deploy/amp-scraper-otel
kubectl -n observability rollout status deploy/amp-scraper-otel
단계 10 — 3개 BU 워크로드 배포 (3/2/2 슬라이스)
BU 네임스페이스 + 디플로이먼트를 적용합니다.
핵심 세부사항: 파드당 nvidia.com/gpu: 1을 요청합니다 (이 경우 MIG 슬라이스가 nvidia.com/gpu로 노출되므로).
쿼리: 할당, 사용률, 실효 비용, 낭비
1) 네임스페이스(BU)별 요청 슬라이스
Q='sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"})'
ENCODED="$(python3 -c 'import urllib.parse,sys; print(urllib.parse.quote(sys.argv[1]))' "$Q")"
awscurl --service aps --region "$AWS_REGION" \
-X POST "${AMP_ENDPOINT}api/v1/query" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "query=${ENCODED}"
관찰된 출력:
{"namespace":"bu-a","value":[...,"3"]}
{"namespace":"bu-b","value":[...,"2"]}
{"namespace":"bu-c","value":[...,"2"]}
2) GPU 사용률 메트릭 찾기
메트릭 이름 나열:
awscurl --service aps --region "$AWS_REGION" \
"${AMP_ENDPOINT}api/v1/label/__name__/values" \
| python3 -c 'import sys,json; j=json.load(sys.stdin); print("\n".join(j["data"]))' \
| egrep -i "dcgm.*util|DCGM.*UTIL|gr_engine_active|sm_active" \
| head -n 30
발견된 메트릭:
DCGM_FI_PROF_GR_ENGINE_ACTIVE
3) 사용률 분수 (스칼라)
Q='scalar(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100)'
ENCODED="$(python3 -c 'import urllib.parse,sys; print(urllib.parse.quote(sys.argv[1]))' "$Q")"
awscurl --service aps --region "$AWS_REGION" \
-X POST "${AMP_ENDPOINT}api/v1/query" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "query=${ENCODED}"
관찰된 예시 (저부하 시):
{"resultType":"scalar","result":[...,"0.0004539326785714286"]}
4) 할당 계산 (시간당)
BU당 할당 $/시간:
allocated_usd_per_hr =
sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"})
* (GPU_HOURLY_RATE / SLICES_PER_GPU)
상수 (12/7)을 적용:
Q='sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}) * (12/7)'
ENCODED="$(python3 -c 'import urllib.parse,sys; print(urllib.parse.quote(sys.argv[1]))' "$Q")"
awscurl --service aps --region "$AWS_REGION" \
-X POST "${AMP_ENDPOINT}api/v1/query" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "query=${ENCODED}"
이 결과는 다음과 일치합니다:
- BU-A: (3/7 × 12 = 5.142857) $/시간
- BU-B: (2/7 × 12 = 3.428571) $/시간
- BU-C: (2/7 × 12 = 3.428571) $/시간
5) 실효 $/시간 및 낭비 $/시간
핵심 포인트: 사용률은 스칼라인 반면 할당은 네임스페이스 레이블 벡터입니다. scalar(...)를 사용하여 Prometheus가 "브로드캐스트"하도록 합니다.
실효 $/시간:
Q='(sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}) * (12/7))
* scalar(clamp_min(clamp_max(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100, 1), 0))'
ENCODED="$(python3 -c 'import urllib.parse,sys; print(urllib.parse.quote(sys.argv[1]))' "$Q")"
awscurl --service aps --region "$AWS_REGION" \
-X POST "${AMP_ENDPOINT}api/v1/query" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "query=${ENCODED}"
관찰된 예시 출력:
{"namespace":"bu-a","value":[...,"0.002325599081632653"]}
{"namespace":"bu-b","value":[...,"0.0015503993877551022"]}
{"namespace":"bu-c","value":[...,"0.0015503993877551022"]}
낭비 $/시간:
Q='(sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}) * (12/7))
- (
(sum by (namespace) (kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}) * (12/7))
* scalar(clamp_min(clamp_max(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100, 1), 0))
)'
ENCODED="$(python3 -c 'import urllib.parse,sys; print(urllib.parse.quote(sys.argv[1]))' "$Q")"
awscurl --service aps --region "$AWS_REGION" \
-X POST "${AMP_ENDPOINT}api/v1/query" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "query=${ENCODED}"
관찰된 예시 출력:
{"namespace":"bu-a","value":[...,"5.14053154377551"]}
{"namespace":"bu-b","value":[...,"3.427021029183673"]}
{"namespace":"bu-c","value":[...,"3.427021029183673"]}
Amazon Managed Grafana (AMG): AMP 위에 대시보드
이 PoC를 쉽게 공유하기 위해 가장 빠른 시각화 레이어는 **Amazon Managed Grafana (AMG)**입니다.
1) AMG 워크스페이스 생성 (CLI)
aws grafana create-workspace \
--name "${CLUSTER_NAME}-gpu-cost" \
--region "${AWS_REGION}" \
--authentication-providers AWS_SSO \
--permission-type SERVICE_MANAGED \
--workspace-data-sources PROMETHEUS
워크스페이스 URL 가져오기:
export AMG_WORKSPACE_ID="$(aws grafana list-workspaces --region "${AWS_REGION}" --query "workspaces[?name=='${CLUSTER_NAME}-gpu-cost'].id | [0]" --output text)"
aws grafana describe-workspace --region "${AWS_REGION}" --workspace-id "${AMG_WORKSPACE_ID}" \
--query "workspace.{status:status,endpoint:endpoint,roleArn:iamRoleArn}" --output yaml
2) AMG가 AMP를 쿼리하도록 허용
export AMG_ROLE_ARN="$(aws grafana describe-workspace --region "${AWS_REGION}" --workspace-id "${AMG_WORKSPACE_ID}" --query "workspace.iamRoleArn" --output text)"
ROLE_NAME="$(basename "$AMG_ROLE_ARN")"
aws iam attach-role-policy --role-name "$ROLE_NAME" --policy-arn arn:aws:iam::aws:policy/AmazonPrometheusQueryAccess
3) AMP를 Prometheus 데이터 소스로 추가 (Grafana UI)
AMG UI에서:
- Connections → Data sources → Add data source → Prometheus
- URL:
https://aps-workspaces.${AWS_REGION}.amazonaws.com/workspaces/${AMP_WORKSPACE_ID} - SigV4: 활성화
- Region:
${AWS_REGION} - Service:
aps
- Region:
- Save & test
4) 스타터 패널 (PromQL)
BU/네임스페이스별 요청 슬라이스
sum by (namespace) (
kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}
)
BU/네임스페이스별 할당 $/시간 (12/7 상수)
sum by (namespace) (
kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}
) * (12/7)
사용률 분수 스칼라 (클러스터 수준 프록시)
scalar(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100)
실효 $/시간 (프록시)
(sum by (namespace) (
kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}
) * (12/7))
* scalar(clamp_min(clamp_max(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100, 1), 0))
낭비 $/시간 (프록시)
(sum by (namespace) (
kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}
) * (12/7))
-
((sum by (namespace) (
kube_pod_container_resource_requests{resource=~"nvidia.*(gpu|mig).*",unit="integer"}
) * (12/7))
* scalar(clamp_min(clamp_max(avg(DCGM_FI_PROF_GR_ENGINE_ACTIVE)/100, 1), 0)))
학습 내용 및 향후 개선 사항
이 PoC가 증명하는 것
- 요청이 선언된 경우(BU당 슬라이스) 단순 상수로 가격을 책정하면 할당은 간단합니다.
- MIG를 사용하면 요청된 슬라이스가 비용 지분에 깔끔하게 매핑됩니다.
- 낭비를 "할당 - 실효"로 계산하여 유휴 슬라이스에 대한 낮은 ROI를 보여줄 수 있습니다.
이 PoC에서 "근사적"인 부분
- MIG의 경우 버전/구성에 따라 DCGM 메트릭에 파드별 GPU 사용률 레이블이 없을 수 있습니다.
- 이 PoC는 BU별 "실제 사용량"의 프록시로 클러스터 수준 사용률 스칼라를 사용했습니다.
프로덕션 수준으로 만들기 위한 다음 단계
- 진정한 파드별 할당:
- 할당된 MIG 디바이스를 읽고 파드 레이블로 사용률을 보고하는 파드별 GPU 사용량 exporter 추가, 또는
- NVIDIA 디바이스 플러그인 / 런타임에서 스케줄러/디바이스 매핑 통합
- 실제 가격 책정:
- 상수 $/GPU-시간을 AWS CUR 또는 온디맨드 가격 API로 대체
- 대시보드:
- AMP를 Grafana에 연결하고 BU별
allocated,effective,waste를 시계열 차트로 표시
- AMP를 Grafana에 연결하고 BU별