Amazon EKS API Server 모니터링
Observability 모범 사례 가이드의 이 섹션에서는 API Server 모니터링과 관련된 다음 주제를 심층적으로 다룹니다:
- Amazon EKS API Server 모니터링 소개
- API Server 문제 해결 대시보드 설정
- API 문제 해결 대시보드를 사용한 API Server 문제 이해
- API Server에 대한 무제한 list 호출 이해
- API Server에 대한 잘못된 동작 방지
- API Priority and Fairness
- 가장 느린 API 호출 식별 및 API Server 지연 문제
소개
Amazon EKS 관리형 컨트롤 플레인을 모니터링하는 것은 EKS 클러스터의 건강 상태와 관련된 문제를 사전에 식별하기 위한 매우 중요한 Day 2 운영 활동입니다. Amazon EKS 컨트롤 플레인 모니터링은 수집된 메트릭을 기반으로 사전 조치를 취할 수 있게 해줍니다. 이러한 메트릭은 API 서버의 문제를 해결하고 근본 원인을 파악하는 데 도움이 됩니다.
이 섹션에서는 Amazon EKS API 서버 모니터링을 위해 Amazon Managed Service for Prometheus(AMP)를, 메트릭 시각화를 위해 Amazon Managed Grafana(AMG)를 사용할 것입니다. Prometheus는 강력한 쿼리 기능을 제공하고 다양한 워크로드에 대한 광범위한 지원을 갖춘 인기 있는 오픈 소스 모니터링 도구입니다. Amazon Managed Service for Prometheus는 완전 관리형 Prometheus 호환 서비스로 Amazon EKS, Amazon Elastic Container Service(Amazon ECS), Amazon Elastic Compute Cloud(Amazon EC2)와 같은 환경을 안전하고 안정적으로 모니터링하기 쉽게 해줍니다. Amazon Managed Grafana는 오픈 소스 Grafana를 위한 완전 관리형 보안 데이터 시각화 서비스로, 고객이 여러 데이터 소스에서 애플리케이션의 운영 메트릭, 로그, 트레이스를 즉시 쿼리, 상관 분석, 시각화할 수 있게 합니다.
먼저 Amazon Managed Service for Prometheus와 Amazon Managed Grafana를 사용하여 Prometheus로 Amazon Elastic Kubernetes Service(Amazon EKS) API Server를 문제 해결하는 데 도움이 되는 스타터 대시보드를 설정하겠습니다. 이어지는 섹션에서 EKS API Server 문제 해결 시 문제 이해, API priority and fairness, 잘못된 동작 방지에 대해 심층적으로 다룹니다. 마지막으로 가장 느린 API 호출 식별과 API 서버 지연 문제에 대해 심층적으로 살펴보며, 이를 통해 Amazon EKS 클러스터의 상태를 건강하게 유지하기 위한 조치를 취할 수 있습니다.
API Server 문제 해결 대시보드 설정
Prometheus로 Amazon Elastic Kubernetes Service(Amazon EKS) API Server를 문제 해결하는 데 도움이 되는 AMP를 사용한 스타터 대시보드를 설정하겠습니다. 이를 사용하여 프로덕션 EKS 클러스터를 문제 해결하면서 메트릭을 이해하는 데 도움을 드리겠습니다. 수집된 메트릭에 대해 더 깊이 초점을 맞추어 Amazon EKS 클러스터 문제 해결 시 그 중요성을 이해하겠습니다.
먼저 Amazon EKS 클러스터에서 Amazon Managed Service for Prometheus로 메트릭을 수집하기 위한 ADOT Collector를 설정합니다. 이 설정에서는 EKS ADOT 애드온을 사용하며, 이를 통해 EKS 클러스터가 가동된 후 언제든지 ADOT를 애드온으로 활성화할 수 있습니다. ADOT 애드온에는 최신 보안 패치와 버그 수정이 포함되어 있으며 Amazon EKS와 함께 작동하도록 AWS에서 검증되었습니다. 이 설정은 EKS 클러스터에 ADOT 애드온을 설치하고 클러스터에서 메트릭을 수집하는 방법을 보여줍니다.
다음으로, 첫 번째 단계에서 설정한 AMP를 데이터 소스로 사용하여 메트릭을 시각화하기 위한 Amazon Managed Grafana 작업 공간을 설정합니다. 마지막으로 API 문제 해결 대시보드를 다운로드하고, Amazon Managed Grafana로 이동하여 추가 문제 해결을 위해 메트릭을 시각화하는 API 문제 해결 대시보드 JSON을 업로드합니다.
API 문제 해결 대시보드를 사용한 문제 이해
클러스터에 설치하고 싶은 흥미로운 오픈 소스 프로젝트를 발견했다고 가정해 보겠습니다. 해당 오퍼레이터가 클러스터에 DaemonSet을 배포하는데, 잘못된 형식의 요청을 사용하거나, 불필요하게 많은 LIST 호출을 하거나, 또는 1,000개 노드 전체의 각 DaemonSet이 매분 클러스터의 모든 50,000개 파드 상태를 요청할 수도 있습니다! 이런 일이 자주 발생할까요? 네, 자주 발생합니다! 이것이 어떻게 발생하는지 간단히 살펴보겠습니다.
LIST vs. WATCH 이해
일부 애플리케이션은 클러스터의 오브젝트 상태를 이해해야 합니다. 예를 들어, 머신 러닝(ML) 애플리케이션이 Completed 상태가 아닌 파드가 얼마나 있는지 이해하여 작업 상태를 알고 싶을 수 있습니다. Kubernetes에서는 WATCH라는 정상적인 방법이 있고, 최신 상태를 찾기 위해 클러스터의 모든 오브젝트를 나열하는 비정상적인 방법이 있습니다.
정상적인 WATCH
WATCH 또는 단일 장기 연결을 사용하여 푸시 모델을 통해 업데이트를 받는 것은 Kubernetes에서 가장 확장 ��가능한 업데이트 방식입니다. 단순화하면, 시스템의 전체 상태를 요청한 다음 해당 오브젝트에 대한 변경 사항이 수신될 때만 캐시의 오브젝트를 업데이트하고, 주기적으로 재동기화를 실행하여 업데이트가 누락되지 않았는지 확인합니다.
아래 이미지에서는 apiserver_longrunning_gauge를 사용하여 두 API 서버에 걸친 이러한 장기 연결 수에 대한 아이디어를 얻습니다.
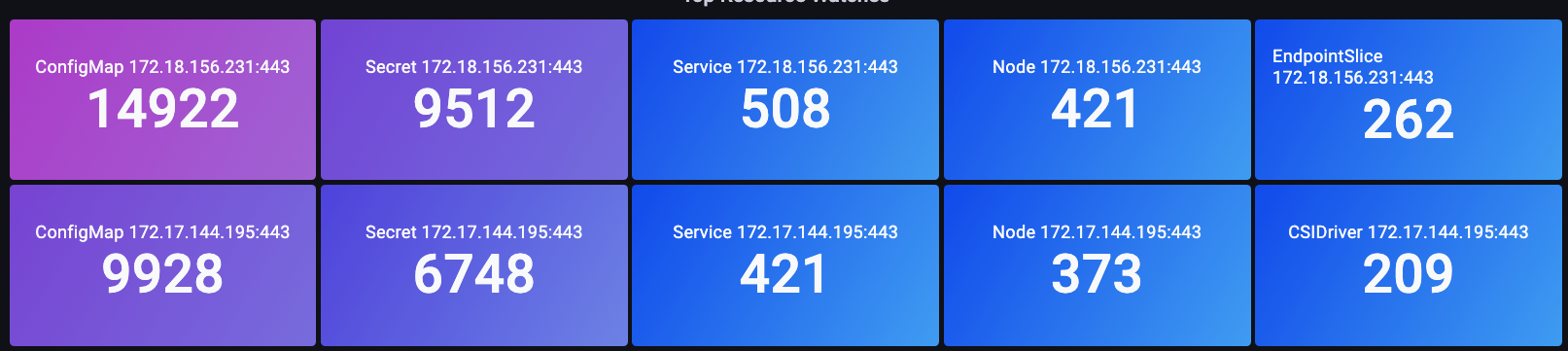
그림: apiserver_longrunning_gauge 메트릭
이 효율적인 시스템에서도 과도한 사용이 가능합니다. 예를 들어, 매우 작은 노드를 많이 사용하고 각각 API 서버와 통신해야 하는 DaemonSet을 두 개 이상 사용하면, 시스템에 대한 WATCH 호출 수를 불필요하게 극적으로 증가시키기 쉽습니다. 예를 들어, 8개의 xlarge 노드와 단일 8xlarge의 차이를 살펴보겠습니다. 여기서 시스템에 대한 WATCH 호출이 8배 증가하는 것을 볼 수 있습니다.
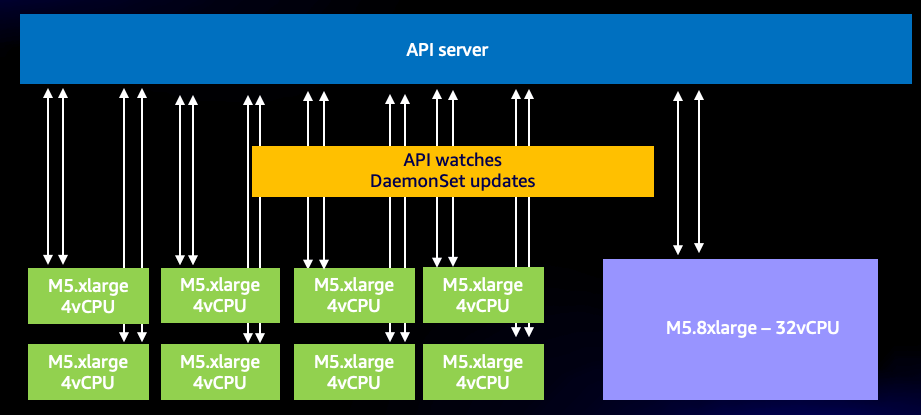
그림: 8개의 xlarge 노드 간 WATCH 호출.
이것들은 효율적인 호출이지만, 앞서 언급한 비정상적인 호출이라면 어떨까요? 위의 DaemonSet 중 하나가 1,000개 노드 각각에서 클러스터의 총 50,000개 파드에 대한 업데이트를 요청한다고 상상해 보세요. 다음 섹션에서 이 무제한 list 호출의 개념을 살펴보겠습니다.
계속하기 전에 주의할 점은, 위 예시와 같은 유형의 통합은 매우 신중하게 수행해야 하며 고려해야 할 다른 많은 요소가 있다는 것입니다. 시스템의 제한된 수의 CPU를 놓고 경쟁하는 스레드 수로 인한 지연, 파드 이탈률, 노드가 안전하게 처리할 수 있는 최대 볼륨 연결 수 등 모든 것이 포함됩니다. 하지만 우리의 초점은 문제 발생을 방지할 수 있는 실행 가능한 단계로 이어지는 메트릭, 그리고 아마도 설계에 대한 새로운 통찰력을 제공하는 메트릭에 있을 것입니다.
WATCH 메트릭은 간단하지만 문제가 있는 경우 watch 수를 추적하고 줄이는 데 사용할 수 있습니다. 이 수를 줄이기 위해 고려할 수 있는 몇 가지 옵션은 다음과 같습니다:
- Helm이 히스토리 추적을 위해 생성하는 ConfigMap 수 제한
- WATCH를 사용하지 않는 Immutable ConfigMap 및 Secret 사용
- 합리적인 노드 크기 조정 및 통합
API Server에 대한 무제한 list 호출 이해
이제 우리가 이야기해 온 LIST 호출에 대해 알아보겠습니다. list 호출은 오브젝트의 상태를 이해해야 할 때마다 Kubernetes 오브젝트의 전체 히스토리를 가져오는 것이며, 이번에는 캐시에 아무것도 저장되지 않습니다.
이것이 얼마나 영향을 미칠까요? 얼마나 많은 에이전트가 데이터를 요청하는지, 얼마나 자주 요청하는지, 얼마나 많은 데이터를 요청하는지에 따라 달라집니다. 클러스터의 모든 것을 요청하는 건지, 아니면 단일 네임스페이스만 요청하는 건지? 매분, 모든 노드에서 발생하는 건지? 노드에서 전송되는 모든 로그에 Kubernetes 메타데이터를 추가하는 로깅 에이전트의 예를 사용해 보겠습니다. 이는 대규모 클러스터에서 압도적인 양의 데이터가 될 수 있습니다. 에이전트가 list 호출을 통해 해당 데이터를 가져오는 방법은 여러 가지가 있으므로 몇 가지를 살펴보겠습니다.
아래 요청은 특정 네임스페이스에서 파드를 요청합니다.
/api/v1/namespaces/my-namespace/pods
다음으로, 클러스터의 모든 50,000개 파드를 요청하지만 한 번에 500개씩 청크로 나눕니다.
/api/v1/pods?limit=500
다음 호출은 가장 파괴적입니다. 전체 클러스터의 50,000개 파드를 동시에 가져옵니다.
/api/v1/pods
이는 현장에서 매우 일반적으로 발생하며 로그에서 확인할 수 있습니다.
API Server에 대한 잘못된 동작 방지
이러한 잘못된 동작으로부터 클러스터를 어떻게 보호할 수 있을까요? Kubernetes 1.20 이전에는 API 서버가 초당 처리되는 inflight 요청 수를 제한하여 자체를 보호했습니다. etcd는 한 번에 성능 좋게 처리할 수 있는 요청 수가 제한되어 있으므로, etcd 읽기 및 쓰기를 합리적인 지연 대역 내에 유지하는 초당 값으로 요청 수를 제한해야 합니다. 불행히도, 이 글을 쓰는 시점에서 이를 동적으로 수행할 방법은 없습니다.
아래 차트에서는 읽기 요청의 분석을 볼 수 있으며, API 서버당 기본 최대 400개의 inflight 요청과 기본 최대 200개의 동시 쓰기 요청�이 있습니다. 기본 EKS 클러스터에서는 두 개의 API 서버가 있어 총 800개의 읽기와 400개의 쓰기가 됩니다. 하지만 업그레이드 직후 등 서로 다른 시점에 이러한 서버에 비대칭 부하가 걸릴 수 있으므로 주의가 필요합니다.
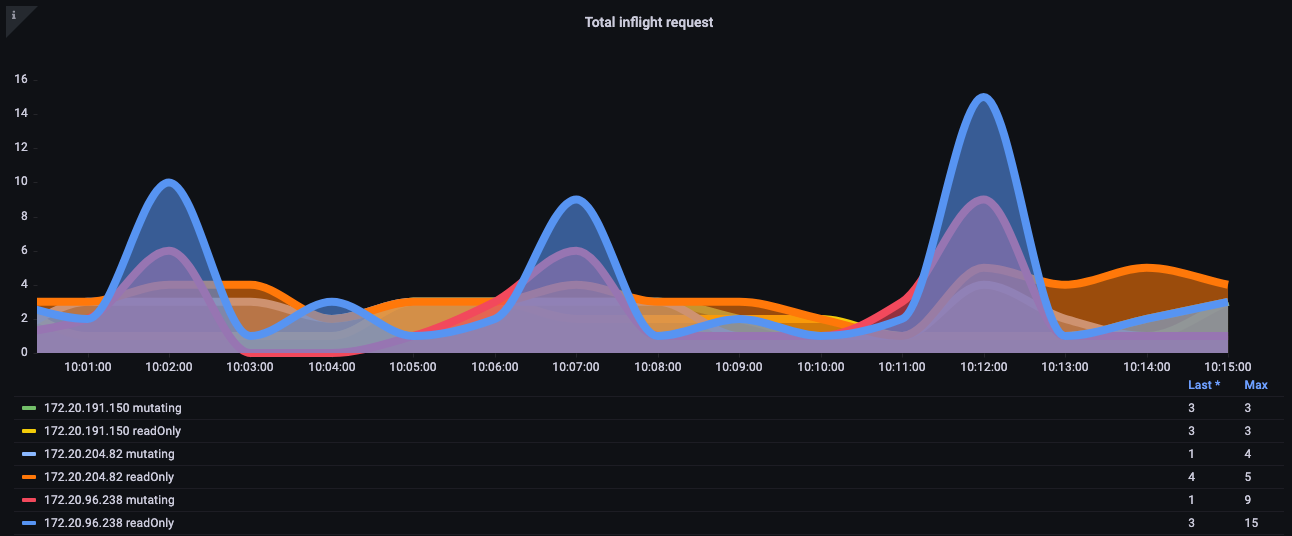
그림: 읽기 요청 분석이 포함된 Grafana 차트.
위의 방법이 완벽한 방식은 아니었습니다. 예를 들어, 방금 설치한 잘못 동작하는 새 오퍼레이터가 API 서버의 모든 inflight 쓰기 요청을 차지하여 노드 keepalive 메시지와 같은 중요한 요청을 잠재적으로 지연시키는 것을 어떻게 방지할 수 있을까요?
API Priority and Fairness
초당 열린 읽기/쓰기 요청 수를 걱정하는 대신, 용량을 하나의 총 수로 취급하고 클러스터의 각 애플리케이션이 그 최대 총 수의 공정한 비율이나 공유를 받는다면 어떨까요?
이를 효과적으로 수행하려면 API 서버에 요청을 보낸 사람을 식별한 다음 해당 요청에 일종의 이름표를 부여해야 합니다. 이 새로운 이름표로 이러한 모든 요청이 "Chatty"라고 부르는 새 에이전트에서 오는 것을 확인할 수 있습니다. 이제 Chatty의 모든 요청을 동일한 DaemonSet에서 오는 요청임을 식별하는 flow라는 것으로 그룹화할 수 있습니다. 이 개념을 통해 이 잘못된 에이전트를 제한하고 전체 클러스터를 소비하지 않도록 할 수 있습니다.
�하지만 모든 요청이 동등하게 생성되는 것은 아닙니다. 클러스터를 운영 상태로 유지하는 데 필요한 컨트롤 플레인 트래픽은 새 오퍼레이터보다 높은 우선순위여야 합니다. 여기서 우선순위 수준의 개념이 등장합니다. 기본적으로 중요, 높음, 낮음 우선순위 트래픽을 위한 여러 "버킷" 또는 큐가 있다면 어떨까요? chatty 에이전트 flow가 중요 트래픽 큐에서 공정한 트래픽 점유율을 얻는 것을 원하지 않습니다. 하지만 해당 트래픽을 낮은 우선순위 큐에 넣으면 해당 flow가 다른 chatty 에이전트와 경쟁하게 됩니다. 그런 다음 각 우선순위 수준이 요청이 너무 지연되지 않도록 API 서버가 처리할 수 있는 전체 최대값의 적절한 수의 공유 또는 비율을 갖도록 해야 합니다.
Priority and Fairness 실행
이것은 비교적 새로운 기능이므로 많은 기존 대시보드는 최대 inflight 읽기 및 최대 inflight 쓰기의 이전 모델을 사용합니다. 이것이 왜 문제가 될 수 있을까요?
kube-system 네임스페이스의 모든 것에 높은 우선순위 이름표를 부여하고 있었지만, 그 잘못된 에이전트를 해당 중요한 네임스페이스에 설치하거나, 단순히 해당 네임스페이스에 너무 많은 애플리케이션을 배포했다면 어떨까요? 피하려고 했던 것과 같은 문제가 발생할 수 있습니다! 따라서 이러한 상황을 면밀히 주시하는 것이 좋습니다.
이러한 종류의 문제를 추적하는 데 가장 흥미로운 메트릭 몇 가지를 분류해 보았습니다.
- 우선순위 그룹의 공유 중 몇 퍼�센트가 사용되고 있는가?
- 요청이 큐에서 가장 오래 대기한 시간은?
- 어떤 flow가 가장 많은 공유를 사용하고 있는가?
- 시스템에 예상치 못한 지연이 있는가?
사용률 백분율
여기서는 클러스터의 서로 다른 기본 우선순위 그룹과 최대값의 몇 퍼센트가 사용되고 있는지 확인할 수 있습니다.
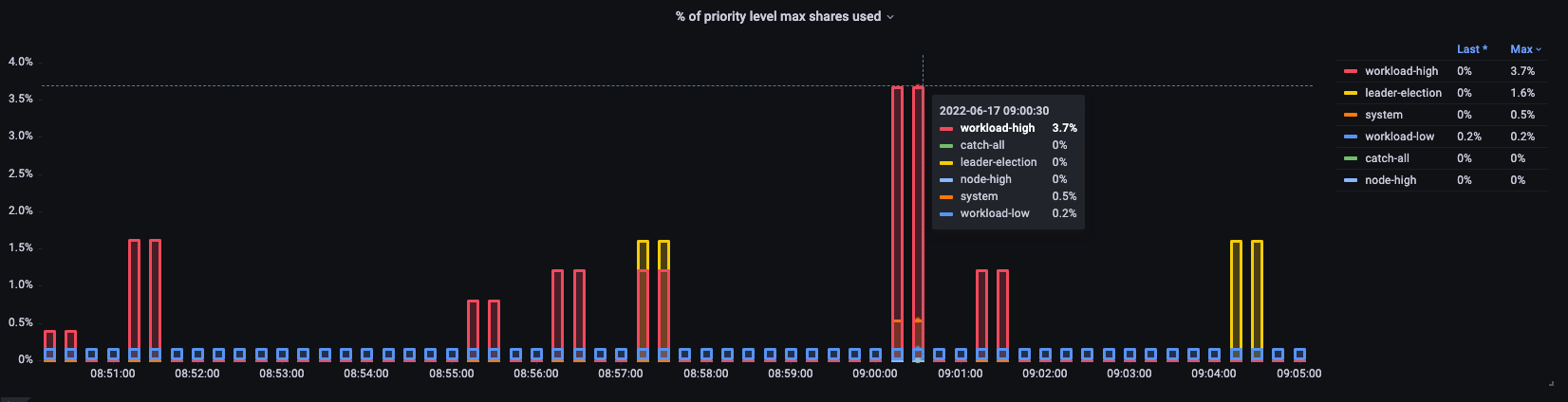
그림: 클러스터의 우선순위 그룹.
요청이 큐에 있던 시간
요청이 처리되기 전에 우선순위 큐에서 대기한 시간(초)입니다.
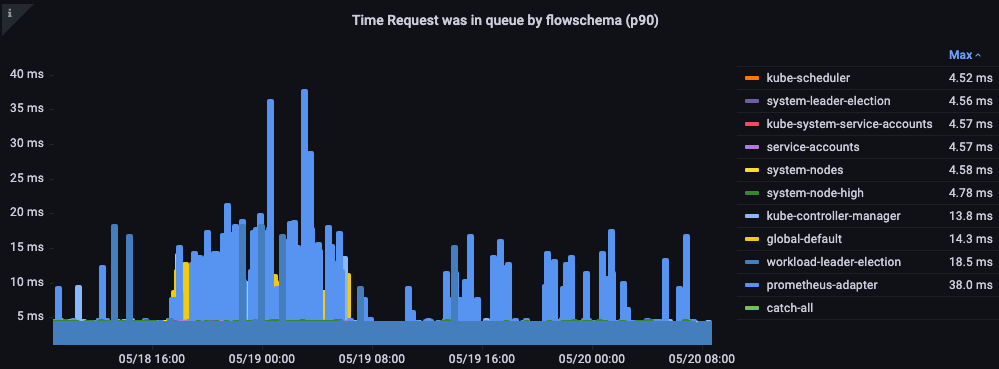
그림: 요청이 우선순위 큐에 있던 시간.
Flow별 상위 실행 요청
어떤 flow가 가장 많은 공유를 차지하고 있는가?
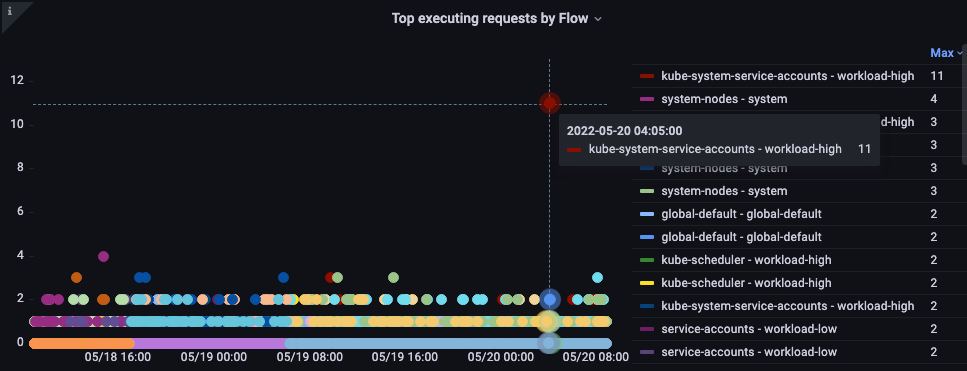
그림: Flow별 상위 실행 요청.
요청 실행 시간
처리에 예상치 못한 지연이 있는가?
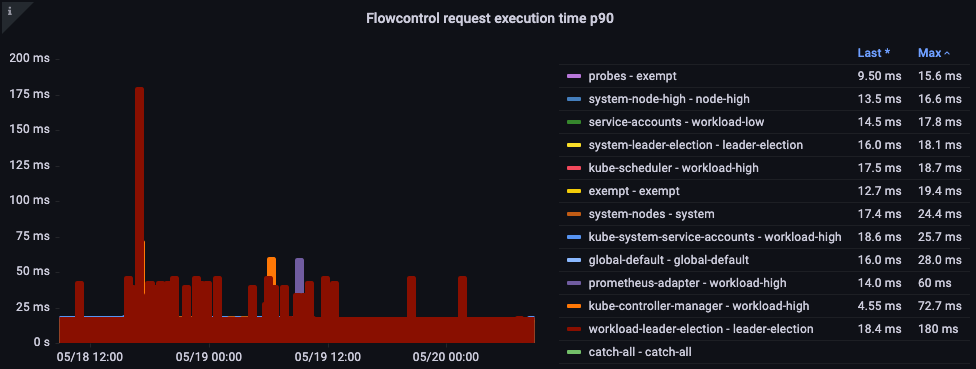
그림: Flow control 요청 실행 시간.
가장 느린 API 호출 식별 및 API Server 지연 문제
이제 API 지연을 유발하는 것들의 본질을 이해했으므로, 한 발 물러서서 큰 그림을 볼 수 있습니다. 대시보드 설계는 단순히 조사해야 할 문제가 있는지 빠르게 스냅샷을 얻으려는 것임을 기억하는 것이 중요합니다. 상세한 분석을 위해서는 PromQL로 임시 쿼리를 사용하거나, 더 나아가 로깅 쿼리를 사용합니다.
확인하고 싶은 높은 수준의 메트릭에 대한 아이디어는 무엇일까요?
- 완료하는 데 가장 오래 걸리는 API 호출은?
- 호출이 무엇을 하고 있는가? (오브젝트 나열, 삭제 등)
- 어떤 오브젝트에 대해 해당 작업을 시도하고 있는가? (Pods, Secrets, ConfigMaps 등)
- API 서버 자체에 지연 문제가 있는가?
- 우선순위 큐 중 하나에 요청 백업을 유발하는 지연이 있는가?
- etcd 서버에 지연이 발생하고 있어서 API 서버가 느려 보이는 것인가?
가장 느린 API 호출
아래 차트에서는 해당 기간 동안 완료하는 데 가장 오래 걸린 API 호출을 찾고 있습니다. 이 경우 05:40 시간대에 커스텀 리소스 정의(CRD)가 가장 지연이 큰 LIST 함수를 호출하고 있음을 볼 수 있습니다. 이 데이터를 바탕으로 CloudWatch Insights를 사용하여 해당 시간대의 감사 로그에서 LIST 요청을 끌어와 어떤 애플리케이션인지 확인할 수 있습니다.
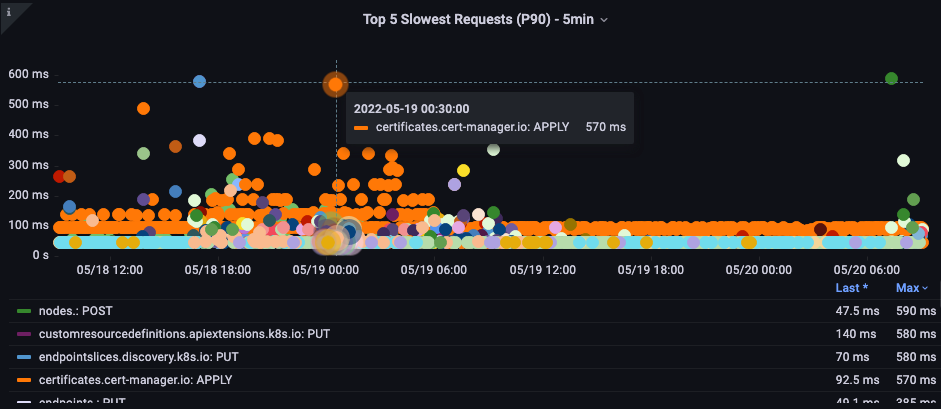
그림: 가장 느린 API 호출 상위 5개.
API 요청 기간
이 API 지연 차트는 요청이 1분의 타임아웃 값에 접근하고 있는지 이해하는 데 도움이 됩니다. 아래의 시간별 히스토그램 형식은 라인 그래프가 숨길 수 있는 데이터의 이상치를 볼 수 있어 선호합니다.
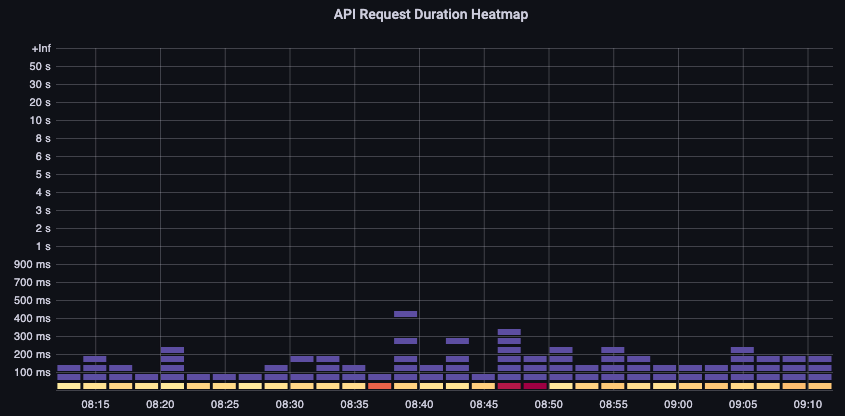
그림: API 요청 기간 히트맵.
버킷 위에 마우스를 올리면 약 25밀리초가 걸린 정확한 호출 수를 보여줍니다. [Image: Image.jpg]그림: 25밀리초 이상의 호출.
이 개념은 요청을 캐시하는 다른 시스템과 함께 작업할 때 중요합니다. 캐시 요청은 빠릅니다; 이러한 요청 지연을 더 느린 요청과 병합하고 싶지 않습니다. 여기서 캐시된 요청과 캐시되지 않은 요청의 두 가지 뚜렷한 지연 대역을 볼 수 있습니다.
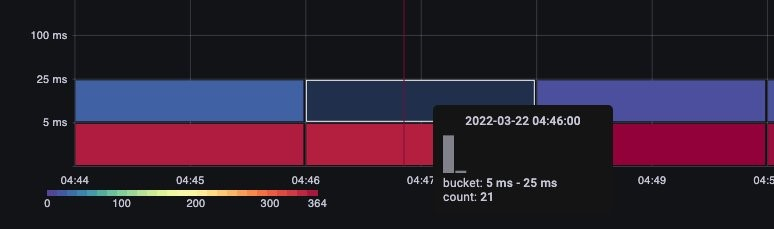
그림: 지연, 캐시된 요청.
ETCD 요청 기간
ETCD 지연은 Kubernetes 성능에서 가장 중요한 요소 중 하나입니다. Amazon EKS를 통해 request_duration_seconds_bucket 메트릭을 살펴보면 API 서버의 관점에서 이 성능을 확인할 수 있습니다.
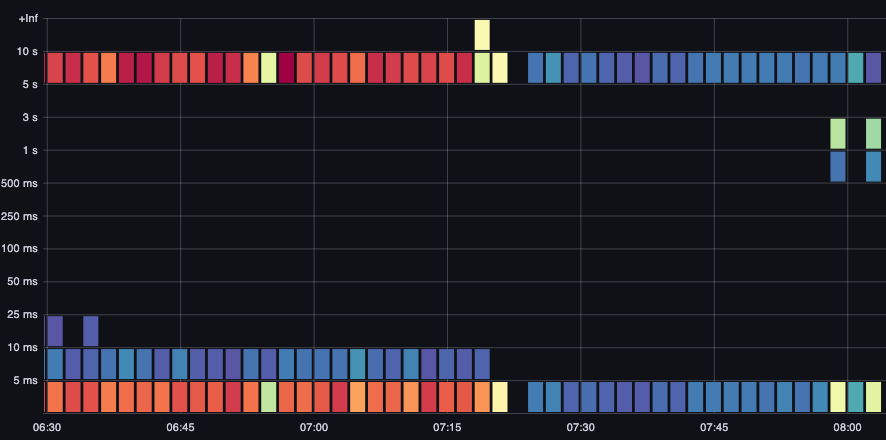
그림: request_duration_seconds_bucket 메트릭.
이제 배운 것들을 종합하여 특정 이벤트가 상관관계가 있는지 확인할 수 있습니다. 아래 차트에서 API 서버 지연을 볼 수 있지만, 이 지연의 상당 부분이 etcd 서버에서 오는 것도 확인할 수 있습니다. 한 눈에 올바른 문제 영역으로 빠르게 이동할 수 있는 것이 대시보드를 강력하게 만드는 것입니다.
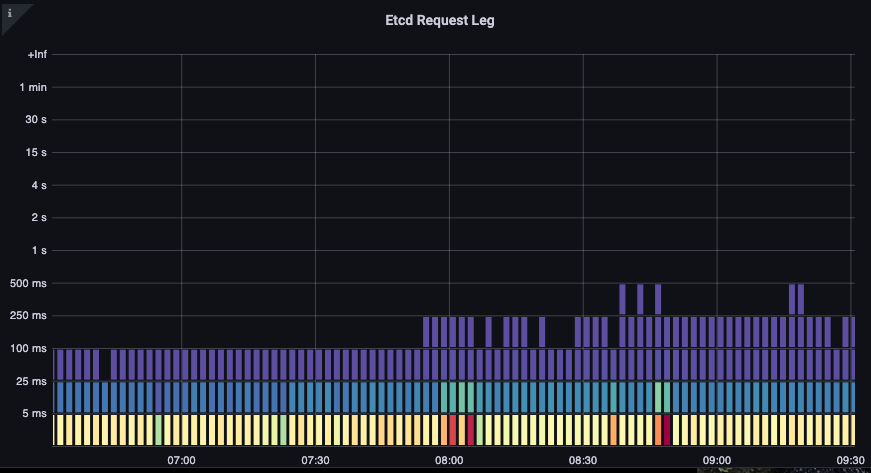
그림: Etcd 요청
결론
Observability 모범 사례 가이드의 이 섹션에서는 Amazon Managed Service for Prometheus와 Amazon Managed Grafana를 사용한 스타터 대시보드를 사용하여 Amazon Elastic Kubernetes Service(Amazon EKS) API Server를 문제 해결하는 방법을 다루었습니다. 또한 EKS API Server 문제 해결 시 문제 이해, API priority and fairness, 잘못된 동작 방지에 대해 심층적으로 다루었습니다. 마지막으로 가장 느린 API 호출 식별과 API 서버 지연 문제에 대해 심층적으로 살펴보았으며, 이를 통해 Amazon EKS 클러스터의 상태를 건강하게 유지하기 위한 조치를 취할 수 있습니다. 추가적인 심층 학습을 위해 AWS One Observability Workshop의 AWS native Observability 카테고리에 있는 Application Monitoring 모듈을 실습하시는 것을 적극 권장합니다.