Amazon EKS API Server のモニタリング
このオブザーバビリティのベストプラクティスガイドのセクションでは、API Server モニタリングに関連する以下のトピックについて詳しく説明します。
- Amazon EKS API Server モニタリングの概要
- API Server トラブルシューター ダッシュボードのセットアップ
- API トラブルシューター ダッシュボードを使用した API Server の問題の理解
- API Server への無制限リスト呼び出しの理解
- API Server への不適切な動作の停止
- API の優先度と公平性
- 最も遅い API 呼び出しと API Server レイテンシーの問題の特定
はじめに
Amazon EKS マネージド型コントロールプレーンの監視は、EKS クラスターの健全性に関する問題を事前に特定するための非常に重要な Day 2 運用アクティビティです。Amazon EKS コントロールプレーンの監視は、収集されたメトリ��クスに基づいて事前対策を講じるのに役立ちます。これらのメトリクスは、API サーバーのトラブルシューティングを行い、内部の問題を特定するのに役立ちます。
このセクションでは、Amazon EKS API サーバーの監視に Amazon Managed Service for Prometheus (AMP) を使用し、メトリクスの可視化に Amazon Managed Grafana (AMG) を使用したデモンストレーションを行います。Prometheus は、強力なクエリ機能を提供し、さまざまなワークロードに幅広く対応している人気のオープンソース監視ツールです。Amazon Managed Service for Prometheus は、フルマネージド型の Prometheus 互換サービスであり、Amazon EKS、Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Compute Cloud (Amazon EC2) などの環境を安全かつ確実に監視することを容易にします。Amazon Managed Grafana は、オープンソース Grafana 向けのフルマネージド型でセキュアなデータ可視化サービスであり、お客様が複数のデータソースからアプリケーションの運用メトリクス、ログ、トレースを即座にクエリ、関連付け、可視化できるようにします
まず、Amazon Managed Service for Prometheus と Amazon Managed Grafana を使用してスターターダッシュボードをセットアップし、Prometheus を使用した Amazon Elastic Kubernetes Service (Amazon EKS) API サーバーのトラブルシューティングを支援します。今後のセクションでは、EKS API サーバーのトラブルシューティング時の問題の理解��、API の優先順位と公平性、不適切な動作の停止について詳しく説明します。最後に、最も遅い API 呼び出しと API サーバーのレイテンシーの問題を特定することで、Amazon EKS クラスターの状態を健全に保つためのアクションを実行できるようにします。
API Server トラブルシューティングダッシュボードのセットアップ
AMP を使用して Amazon Elastic Kubernetes Service (Amazon EKS) API サーバーのトラブルシューティングに役立つスターターダッシュボードをセットアップします。これを使用して、本番環境の EKS クラスターのトラブルシューティング中にメトリクスを理解できるようにします。さらに、収集されたメトリクスを詳しく調べて、Amazon EKS クラスターのトラブルシューティング時におけるその重要性を理解します。
まず、Amazon EKS クラスターから Amazon Manager Service for Prometheus にメトリクスを収集するための ADOT コレクターをセットアップします。このセットアップでは、EKS ADOT Addon を使用します。これにより、EKS クラスターが起動して実行された後、いつでも ADOT をアドオンとして有効にできます。ADOT アドオンには最新のセキュリティパッチとバグ修正が含まれており、Amazon EKS で動作することが AWS によって検証されています。このセットアップでは、EKS クラスターに ADOT アドオンをインストールし、それを使用してクラスターからメトリクスを収集する方法を説明します。
次に、最初のステップでセットアップした AMP をデータソースとして使用し、Amazon Managed Grafana ワークスペースをセットアップしてメトリクスを可視化します。最後に API troubleshooter dashboard をダウンロードし、Amazon Managed Grafana に移動して API troubleshooter dashboard の json をアップロードし、さらなるトラブルシューティングのためにメトリクスを可視化します。
API Troubleshooter ダッシュボードを使用した問題の理解
クラスターにインストールしたい興味深いオープンソースプロジェクトを見つけたとします。そのオペレーターは、不正な形式のリクエストを使用している可能性がある DaemonSet、不必要に大量の LIST 呼び出し、または 1,000 �個すべてのノードにわたる各 DaemonSet が毎分クラスター上の 50,000 個すべてのポッドのステータスをリクエストしている可能性があります。 これは本当によく起こることでしょうか?はい、起こります!どのようにしてそれが起こるのか、簡単に見ていきましょう。
LIST と WATCH の理解
クラスター内のオブジェクトの状態を理解する必要があるアプリケーションがあります。たとえば、機械学習 (ML) アプリケーションが、Completed ステータスではない Pod の数を把握することでジョブステータスを知りたい場合などです。Kubernetes では、WATCH と呼ばれるものを使用して適切に実行する方法と、クラスター上のすべてのオブジェクトをリストしてそれらの Pod の最新ステータスを見つけるという、あまり適切ではない方法があります。
適切に動作する WATCH
WATCH または単一の長時間接続を使用してプッシュモデル経由で更新を受信することは、Kubernetes で更新を行う最もスケーラブルな方法です。簡単に言えば、システムの完全な状態を要求し、そのオブジェクトの変更が受信されたときにのみキャッシュ内のオブジェクトを更新し、定期的に再同期を実行して更新が見逃されていないことを確認します。
以下の�画像では、 apiserver_longrunning_gauge 両方の API サーバー全体でこれらの長時間接続の数を把握できます。
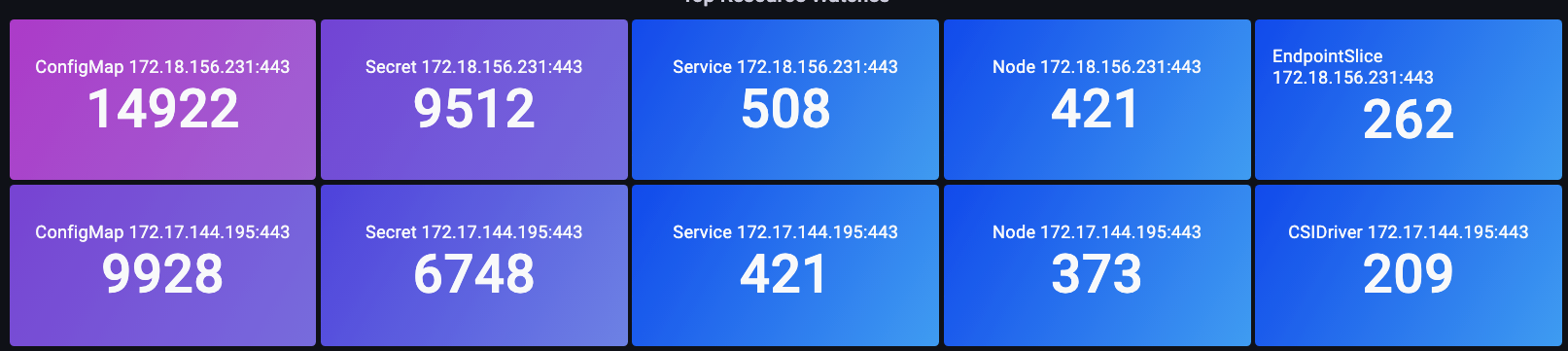
図: apiserver_longrunning_gauge metric
この効率的なシステムを使用しても、良いものを使いすぎる可能性があります。たとえば、API サーバーと通信する必要がある 2 つ以上の DaemonSet を使用する非常に小さなノードを多数使用すると、システム上の WATCH 呼び出しの数を不必要に劇的に増加させることが非常に簡単になります。たとえば、8 つの xlarge ノードと 1 つの 8xlarge の違いを見てみましょう。ここでは、システム上の WATCH 呼び出しが 8 倍に増加していることがわかります。
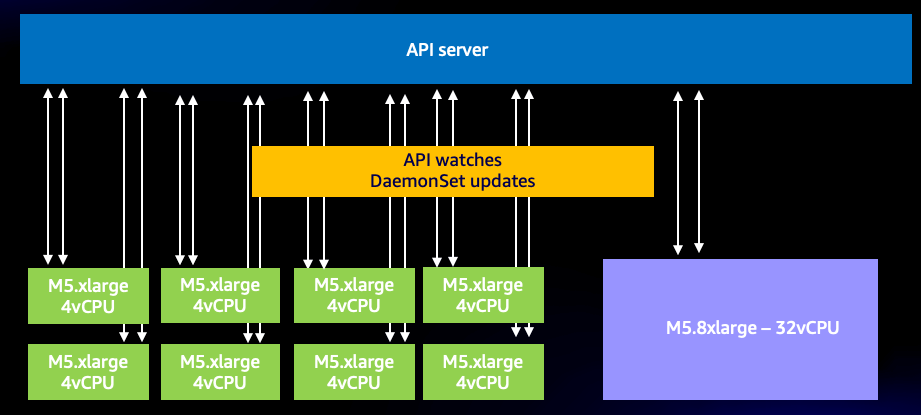
図: 8 台の xlarge ノード間の WATCH 呼び出し。
これらは効率的な呼び出しですが、先ほど言及した不適切な呼び出しだった場合はどうでしょうか?1,000 個の各ノード上の上記 DaemonSet のいずれかが、クラスター内の合計 50,000 個のポッド全体の更新をリクエストしていると想像してください。この無制限のリスト呼び出しのアイデアについては、次のセクションで説明します。
続行する前に簡単に注意しておきますが、上記の例のような統合は細心の注意を払って行う必要があり、考慮すべき他の多くの要因があります。システム上の限られた数の CPU を競合するスレッド数の遅延、Pod の�チャーンレート、ノードが安全に処理できるボリュームアタッチメントの最大数まで、すべてが関係します。ただし、ここでは、問題の発生を防ぐための実用的な手順につながるメトリクス、そしておそらく設計に関する新しい洞察を与えてくれるメトリクスに焦点を当てます。
WATCH メトリクスはシンプルなものですが、これが問題になっている場合、ウォッチの数を追跡して削減するために使用できます。この数を削減するために検討できるいくつかのオプションを以下に示します。
- Helm が履歴を追跡するために作成する ConfigMap の数を制限する
- WATCH を使用しない Immutable ConfigMap と Secret を使用する
- 適切なノードサイジングと統合
API Server への無制限のリスト呼び出しについて理解する
これまで説明してきた LIST 呼び出しについて見ていきます。list 呼び出しは、オブジェクトの状態を理解する必要があるたびに、Kubernetes オブジェクトの完全な履歴を取得するもので、今回はキャッシュに何も保存されません。
これらすべてがどの程度影響を与えるのでしょうか?それは、データをリクエストしているエージェントの数、リクエストの頻度、リクエストするデータ量によって異なります。クラスター全体のすべてを要求しているのか、それとも単一の namespace だけなのか?それはすべてのノードで毎分発生するのか?ノードから送信されるすべてのログに Kubernetes メタデータを追加するロギングエージェントの例を使用してみましょう。これは、大規模なクラスターでは圧倒的な量のデータになる可能性があります。エージェントが list 呼び出しを介してそのデータを取得する方法は多数あるため、いくつか見てみましょう。
以下のリクエストは、特定の namespace から Pod を要求しています。
/api/v1/namespaces/my-namespace/pods
次に、クラスター上のすべての 50,000 個の Pod をリクエストしますが、一度に 500 個の Pod ずつチャンクで取得します。
/api/v1/pods?limit=500
次の呼び出しが最も破壊的です。クラスター全体の 50,000 個すべての Pod を同時に取得します。
/api/v1/pods
これはフィールドで非常によく発生し、ログで確認できます。
API Server への不適切な動作の停止
このような悪い動作からクラスターを保護するにはどうすればよいでしょうか。Kubernetes 1.20 以前では、API サーバーは 1 秒あたりに処理されるインフライトリクエストの数を制限することで自身を保護していました。etcd はパフォーマンスの高い方法で一度に処理できるリクエスト数に限りがあるため、etcd の読み取りと書き込みを妥当なレイテンシー帯域内に保つた�めに、1 秒あたりのリクエスト数を適切な値に制限する必要があります。残念ながら、この記事の執筆時点では、これを動的に行う方法はありません。
以下のグラフでは、読み取りリクエストの内訳を確認できます。API サーバーあたりのデフォルトの最大同時実行リクエスト数は 400 で、書き込みリクエストのデフォルトの最大同時実行数は 200 です。デフォルトの EKS クラスターでは、2 つの API サーバーが表示されるため、合計で 800 の読み取りと 400 の書き込みが可能です。ただし、アップグレード直後など、異なるタイミングでこれらのサーバーに非対称な負荷がかかる可能性があるため、注意が必要です。
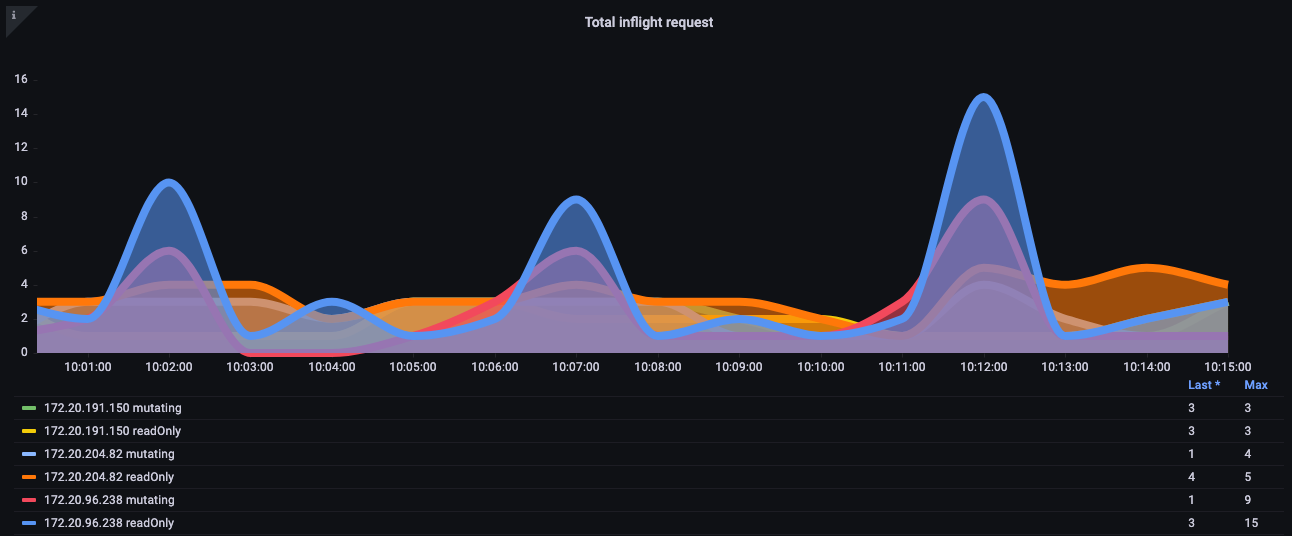
図: 読み取りリクエストの内訳を示す Grafana チャート。
上記は完璧なスキームではないことが判明しました。たとえば、インストールしたばかりのこの不適切な動作をする新しいオペレーターが、API サーバー上のすべての実行中の書き込みリクエストを占有し、ノードのキープアライブメッセージなどの重要なリクエストを遅延させる可能性があるのを、どのように防ぐことができるでしょうか?
API Priority and Fairness
1 秒あたりに開いている読み取り/書き込みリクエストの数を気にする代わりに、容量を 1 つの合計数として扱い、クラスター上の各アプリケーションがその合計最大数の公平な割合またはシェアを取得するようにしたらどうでしょうか。
これを効果的に行うには、API サーバーにリクエストを送信したのが誰かを特定し、そのリクエストに名札のようなものを付ける必要があります。この新しい名札により、これらすべてのリクエストが「Chatty」と呼ばれる新しいエージェントから来ていることがわかります。これで、Chatty のすべてのリクエストを flow と呼ばれるものにグループ化し、それらのリクエストが同じ DaemonSet から来ていることを識別できます。この概念により、この不正なエージェントを制限し、クラスター全体を消費しないようにすることができます。
しかし、すべてのリクエストが同じように作成されるわけではありません。クラスターの運用を維持するために必要なコントロールプレーントラフィックは、新しいオペレーターよりも優先度が高くなければなりません。ここで優先度レベルの概念が登場します。デフォルトで、クリティカル、高、低優先度トラフィック用のいくつかの「バケット」またはキューがあったらどうでしょうか。頻繁に通信するエージェントフローがクリティカルトラフィックキューで公平なシェアを獲得することは望ましくありません。しかし、そのトラフィックを低優先度キューに配置することで、そのフローはおそらく他の頻繁に通信するエージェントと競合することになります。次に、各優先度レベルが、API サーバーが処理できる全体の最大値の適切なシェア数またはパーセンテージを持つようにして、リクエストが過度に遅延しないようにする必要がありま��す。
優先度と公平性の動作
これは比較的新しい機能であるため、既存の多くのダッシュボードでは、古いモデルの最大インフライト読み取りと最大インフライト書き込みが使用されています。なぜこれが問題になる可能性があるのでしょうか?
kube-system 名前空間内のすべてに高優先度の名前タグを付与していたとして、その重要な名前空間に問題のあるエージェントをインストールしたり、単にその名前空間に多数のアプリケーションをデプロイしたりした場合はどうなるでしょうか。回避しようとしていたのと同じ問題が発生する可能性があります。そのため、このような状況には細心の注意を払うことが最善です。
このような問題を追跡するために最も興味深いと思われるメトリクスをいくつか抜粋しました。
- 優先度グループの共有のうち、何パーセントが使用されていますか?
- リクエストがキューで待機した最長時間はどれくらいですか?
- 最も多くの共有を使用しているフローはどれですか?
- システムに予期しない遅延はありますか?
使用率
ここでは、クラスター上のさまざまなデフォルト優先度グループと、最大値の何パーセントが使用されているかを確認できます。
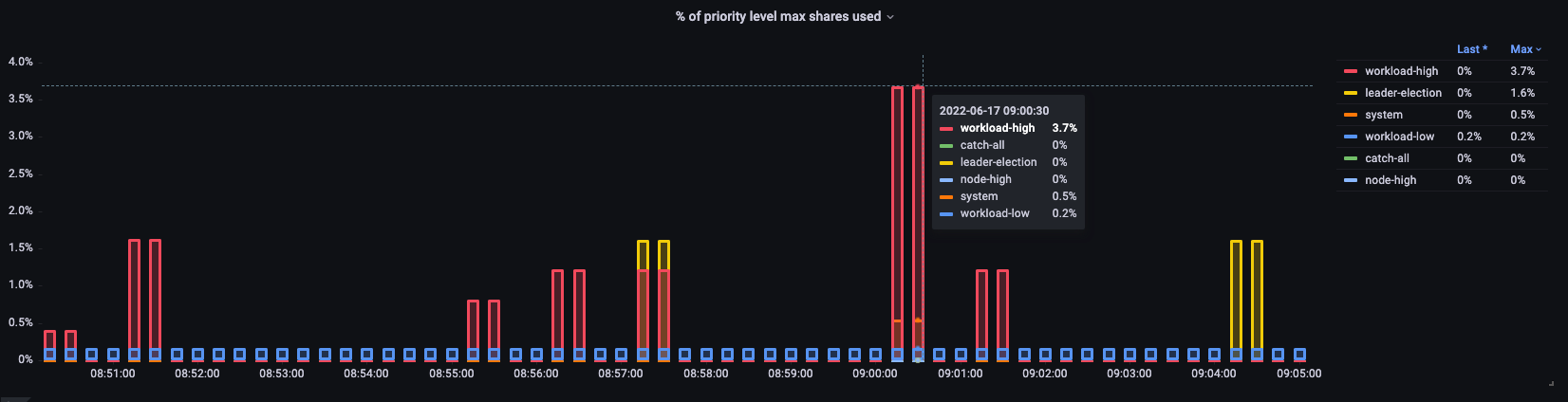
図: クラスター上の優先度グループ。
リクエストがキューに入っていた時間
リクエストが処理される前に優先度キューで待機していた時間(秒単位)。
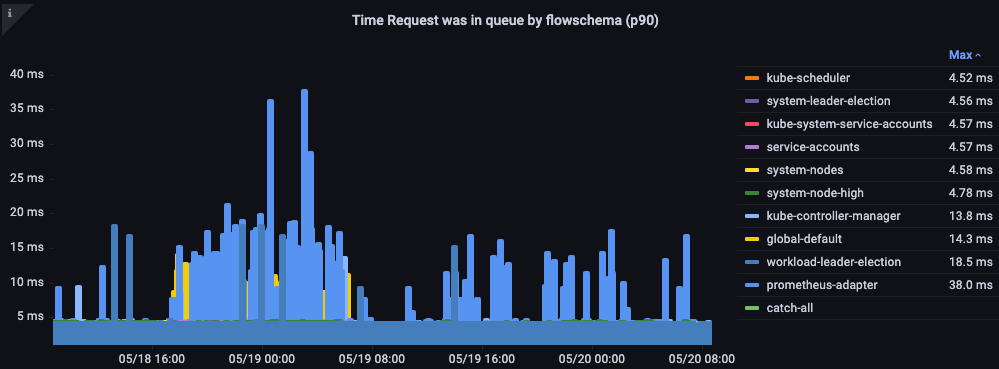
図: リクエストが優先度キューに入っていた時間。
フロー別の上位実行リクエスト
どのフローが最も多くのシェアを占めていますか?
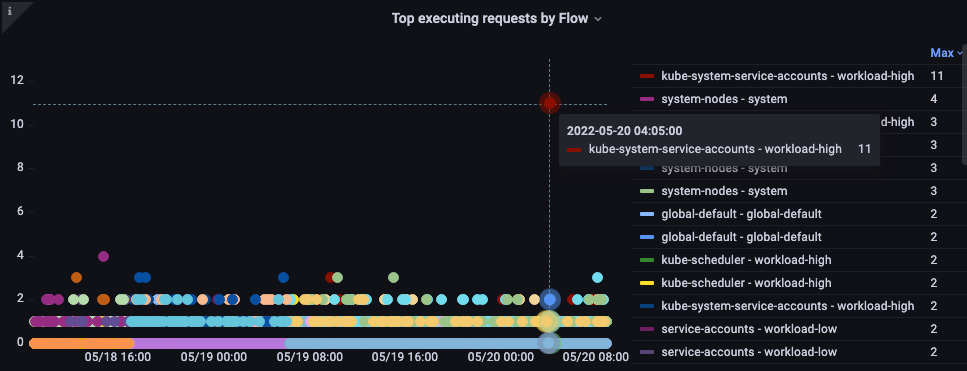
図: フローごとの上位実行リクエスト。
リクエスト実行時間
処理に予期しない遅延はありませんか?
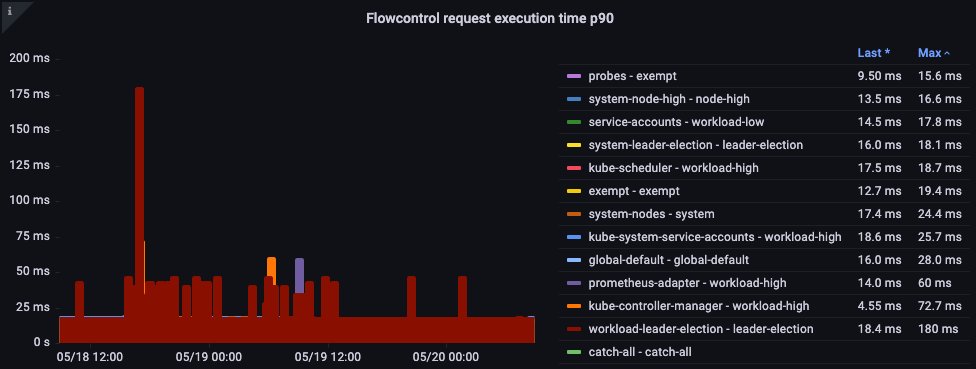
図: フロー制御リクエストの実行時間。
最も遅い API 呼び出しと API Server レイテンシーの問題の特定
API レイテンシーを引き起こす要因の性質を理解したので、一歩下がって全体像を見ることができます。ダッシュボードの設計は、調査すべき問題があるかどうかを素早く把握しようとしているだけであることを覚えておくことが重要です。詳細な分析には、PromQL によるアドホッククエリ、またはさらに良いのはログクエリを使用します。
確認したいハイレベルメトリクスのアイデアにはどのようなものがありますか?
- 完了までに最も時間がかかっている API 呼び出しは何ですか?
- その呼び出しは何をしていますか?(オブジェクトのリスト表示、削除など)
- どのオブジェクトに対してその操作を実行しようとしていますか?(Pod、Secret、ConfigMap など)
- API サーバー自体にレイテンシーの問題がありますか?
- 優先度キューの 1 つに遅延があり、リクエストのバックアッ��プが発生していますか?
- etcd サーバーでレイテンシーが発生しているために、API サーバーが遅いように見えるだけですか?
最も遅い API コール
以下のチャートでは、その期間中に完了するまでに最も時間がかかった API 呼び出しを探しています。この場合、カスタムリソース定義 (CRD) が LIST 関数を呼び出しており、05:40 の時間枠で最もレイテンシーの高い呼び出しであることがわかります。このデータを使用して、CloudWatch Insights を使ってその時間枠の監査ログから LIST リクエストを取得し、どのアプリケーションである可能性があるかを確認できます。
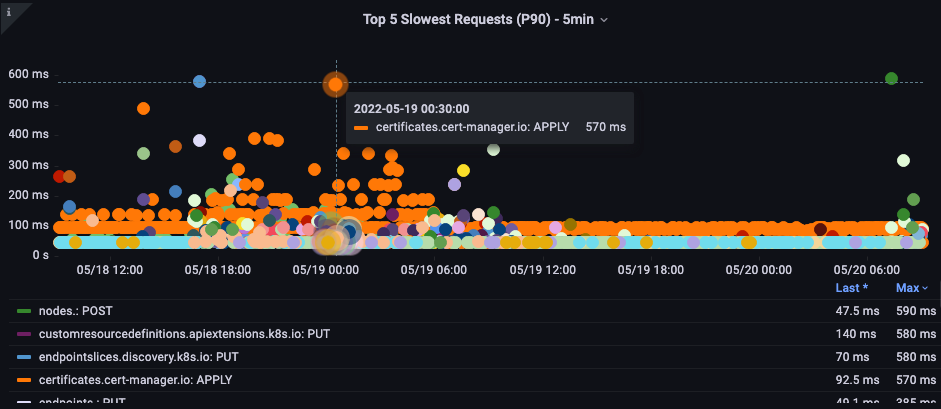
図: 最も遅い上位 5 つの API 呼び出し。
API リクエスト期間
この API レイテンシーチャートは、1 分のタイムアウト値に近づいているリクエストがあるかどうかを理解するのに役立ちます。以下の時系列ヒストグラム形式は、折れ線グラフでは隠れてしまうデータの外れ値を確認できるため、私は気に入っています。
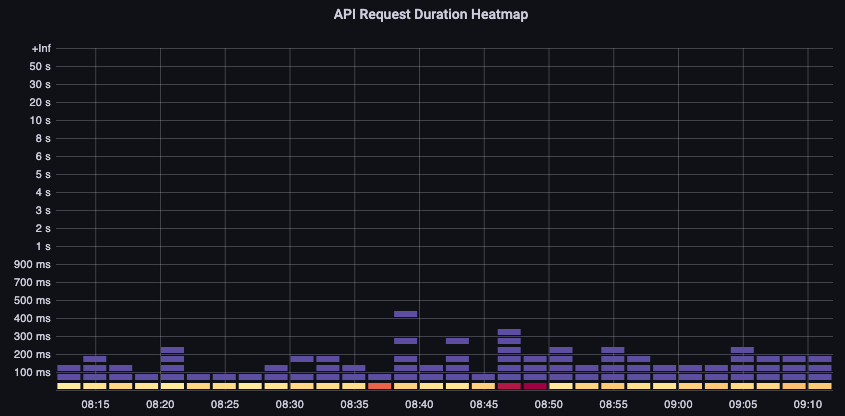
図: API リクエスト期間のヒートマップ。
バケットにカーソルを合わせるだけで、約 25 ミリ秒かかった呼び出しの正確な数が表示されます。 [Image: Image.jpg]図: 25 ミリ秒を超える呼び出し。
この概念は、リクエストをキャッシュする他のシステムと連携する際に重要です。キャッシュされたリクエストは高速です。これらのリクエストのレイテンシーを、より遅いリクエストとマージしたくありません。ここでは、キャッシュされたリクエストとキャッシュされていないリクエストという、2 つの明確なレイテンシーの帯域を確認できます。
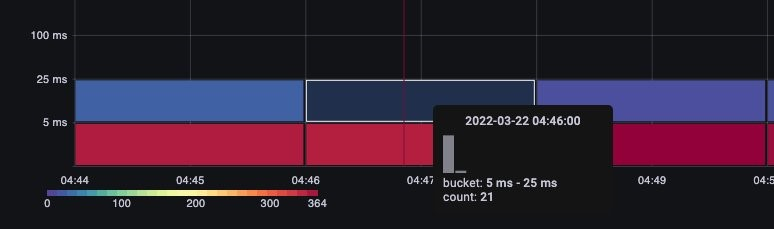
図: レイテンシー、キャッシュされたリクエスト。
ETCD リクエスト期間
ETCD レイテンシーは、Kubernetes のパフォーマンスにおいて最も重要な要素の 1 つです。Amazon EKS では、API サーバーの観点からこのパフォーマンスを確認できます。 request_duration_seconds_bucket メトリクス。
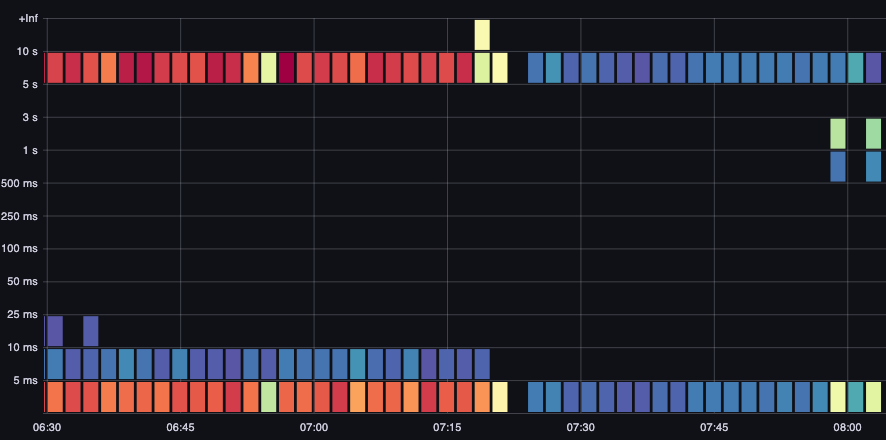
図: request_duration_seconds_bucket metric.
学習した内容を組み合わせて、特定のイベントが相関しているかどうかを確認できるようになりました。以下のチャートでは、API サーバーのレイテンシーが表示されていますが、このレイテンシーの多くが etcd サーバーから発生していることもわかります。一目で適切な問題領域にすばやく移動できることが、ダッシュボードを強力にする要素です。
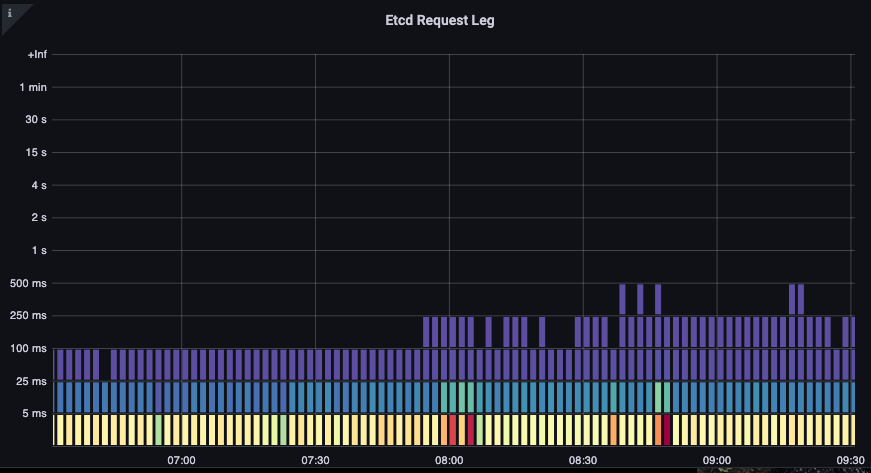
図: Etcd リクエスト
まとめ
このオブザーバビリティのベストプラクティスガイドのセクションでは、Amazon Managed Service for Prometheus と Amazon Managed Grafana を使用したスターターダッシュボードを使用して、Amazon Elastic Kubernetes Service (Amazon EKS) API サーバーのトラブルシューティングを支援しました。さらに、EKS API サーバーのトラブルシューティング中の問題の理解、API の優先度と公平性、不適切な動作の停止について深く掘り下げました。最後に、最も遅い API 呼び出しと API サーバーのレイテンシーの問題を特定することについて深く掘り下げ、Amazon EKS クラスターの状態を健全に保つためのアクションを実行できるようにしました。さらに深く掘り下げるには、AWS One Observability Workshop の AWS ネイティブオブザーバビリティカテゴリにあるアプリケーションモニタリングモジュールを実践することを強くお勧めします。