key-performance-indicators
1.0 KPI("골든 시그널") 이해하기
조직은 비즈니스와 운영의 건전성 또는 리스크에 대한 통찰력을 제공하는 핵심 성과 지표(KPI), 즉 '골든 시그널'을 활용합니다. 조직 내 각 부서는 해당 부서의 성과를 측정하기 위한 고유한 KPI를 보유합니다. 예를 들어, 이커머스 애플리케이션의 제품 팀은 장바구니 주문을 성공적으로 처리하는 능력을 KPI로 추적합니다. 온콜 운영 팀은 인시던트를 감지하기까지의 평균 시간(MTTD)을 KPI로 측정합니다. 재무 팀에게는 리소스 비용이 예산 내에 있는지 여부가 중요한 KPI입니다.
Service Level Indicator(SLI), Service Level Objective(SLO), Service Level Agreement(SLA)는 서비스 신뢰성 관리의 핵심 구성 요소입니다. 이 가이드에서는 Amazon CloudWatch와 그 기능을 활용하여 SLI, SLO, SLA를 계산하고 모니터링하기 위한 모범 사례를 명확하고 간결한 예제와 함께 설명합니다.
- SLI (Service Level Indicator): 서비스 성능에 대한 정량적 측정 지표입니다.
- SLO (Service Level Objective): SLI의 목표 값으로, 원하는 성능 수준을 나타냅니다.
- SLA (Service Level Agreement): 서비스 제공자와 사용자 간에 기대되는 서비스 수준을 명시한 계약입니다.
일반적인 SLI 예시:
- 가용성: 서비스가 정상 운영되는 시간의 비율
- 지연 시간: 요청을 처리하는 데 걸리는 시간
- 오류율: 실패한 요청의 비율
2.0 고객 및 이해관계자 요구사항 파악 (아래 제안된 템플릿 활용)
- 최상위 질문에서 시작합니다: "해당 워크로드(예: 결제 포털, 이커머스 주문 처리, 사용자 등록, 데이터 보고서, 지원 포털 등)의 범위 내에서 비즈니스 가치 또는 비즈니스 문제는 무엇인가?"
- 비즈니스 가치를 다음과 같은 카테고리로 분류합니다: 사용자 경험(UX), 비즈니스 경험(BX), 운영 경험(OpsX), 보안 경험(SecX), 개발자 경험(DevX)
- 각 카테고리에 대한 핵심 시그널, 즉 "골든 시그널"을 도출합니다. UX와 BX에 대한 상위 시그널이 일반적으로 비즈니스 메트릭을 구성합니다.
| ID | 이니셜 | 고객 | 비즈니스 요구 | 측정 항목 | 정보 소스 | 정상 상태 기준 | 알람 | 대시보드 | 보고서 |
|---|---|---|---|---|---|---|---|---|---|
| M1 | 예시 | 외부 최종 사용자 | 사용자 경험 | 응답 시간 (페이지 지연 시간) | 로그 / 트레이스 | 99.9%에 대해 5초 미만 | 아니오 | 예 | 아니오 |
| M2 | 예시 | 비즈니스 | 가용성 | 성공 RPS (초당 요청 수) | Health Check | 5분 윈도우에서 85% 초과 | 예 | 예 | 예 |
| M3 | 예시 | 보안 | 규정 준수 | 심각한 비준수 리소스 | Config 데이터 | 15일 이내 10개 미만 | 아니오 | 예 | 예 |
| M4 | 예시 | 개발자 | 민첩성 | 배포 시간 | 배포 로그 | 항상 10분 미만 | 예 | 아니오 | 예 |
| M5 | 예시 | 운영자 | 용량 | Queue Depth | 앱 로그/메트릭 | 항상 10 미만 | 예 | 예 | 예 |
2.1 골든 시그널
| 카테고리 | 시그널 | 참고 | 참조 자료 |
|---|---|---|---|
| UX | 성능 (지연 시간) | 템플릿의 M1 참조 | 백서: Availability and Beyond (Measuring latency) |
| BX | 가용성 | 템플릿의 M2 참조 | 백서: Avaiability and Beyond (Measuring availability) |
| BX | 비즈니스 연속성 계획 (BCP) | Amazon Resilience Hub (ARH)의 정의된 RTO/RPO에 대한 복원력 점수 | 문서: ARH user guide (Understanding resilience scores) |
| SecX | (비)준수 | 템플릿의 M3 참조 | 문서: AWS Control Tower user guide (Compliance status in the console) |
| DevX | 민첩성 | 템플릿의 M4 참조 | 문서: DevOps Monitoring Dashboard on AWS (DevOps metrics list) |
| OpsX | 용량 (할당량) | 템플릿의 M5 참조 | 문서: Amazon CloudWatch user guide (Visualizing your service quotas and setting alarms) |
| OpsX | 예산 이상 탐지 | 문서: 1. AWS Billing and Cost Management (AWS Cost Anomaly Detection) 2. AWS Budgets |
3.0 최상위 가이드라인 'TLG'
3.1 TLG 일반 사항
-
비즈니스, 아키텍처, 보안 팀과 협력하여 비즈니스, 규정 준수, 거버넌스 요구사항을 정제하고 이것이 비즈니스 요구를 정확히 반영하는지 확인합니다. 여기에는 복구 시간 및 복구 시점 목표 설정(RTO, RPO)이 포함됩니다. 가용성 측정 및 지연 시간과 같은 요구사항을 측정하는 방법을 수립합니다(예: 가동 시간은 5분 윈도우 내에서 소량의 장애를 허용할 수 있음).
-
다양한 비즈니스 기능적 결과에 부합하는 목적 기반 스키마를 갖춘 효과적인 태깅 전략을 구축합니다. 특히 운영 Observability와 인시던트 관리를 포괄해야 합니다.
-
가능하면 알람에 동적 임계값을 활용합니다(특히 기준 KPI가 없는 메트릭의 경우). 머신러닝 알고리즘을 통해 기준선을 설정하는 CloudWatch 이상 탐지를 사용합니다. CloudWatch 메트릭을 게시하는 AWS 서비스(또는 Prometheus 메트릭 등 다른 소스)를 활용하여 알람을 구성할 때는 알람 노이즈를 줄이기 위해 복합 알람을 생성하는 것을 고려합니다. 예를 들어, 가용성을 나타내는 비즈니스 메트릭(성공 요청으로 추적)과 지연 시간으로 구성된 복합 알람이 배포 중 두 값 모두 임계값 아래로 떨어질 때 알람을 발생시키도록 구성하면, 배포 버그를 결정적으로 파악하는 지표가 될 수 있습니다.
-
(참고: AWS Business 지원 이상 필요) AWS는 Personal Health Dashboard에서 귀하의 리소스와 관련된 관심 이벤트를 AWS Health 서비스를 통해 게시합니다. AWS Health를 활용하는 AWS Health Aware (AHA) 프레임워크를 활용하여 중앙 계정(예: 관리 계정)에서 AWS Organization 전체에 걸쳐 집계된 사전 예방적 및 실시간 알림을 수집합니다. 이러한 알림은 Slack과 같은 선호하는 커뮤니케이션 플랫폼으로 전송할 수 있으며, ServiceNow 및 Jira와 같은 ITSM 도구와 통합됩니다.
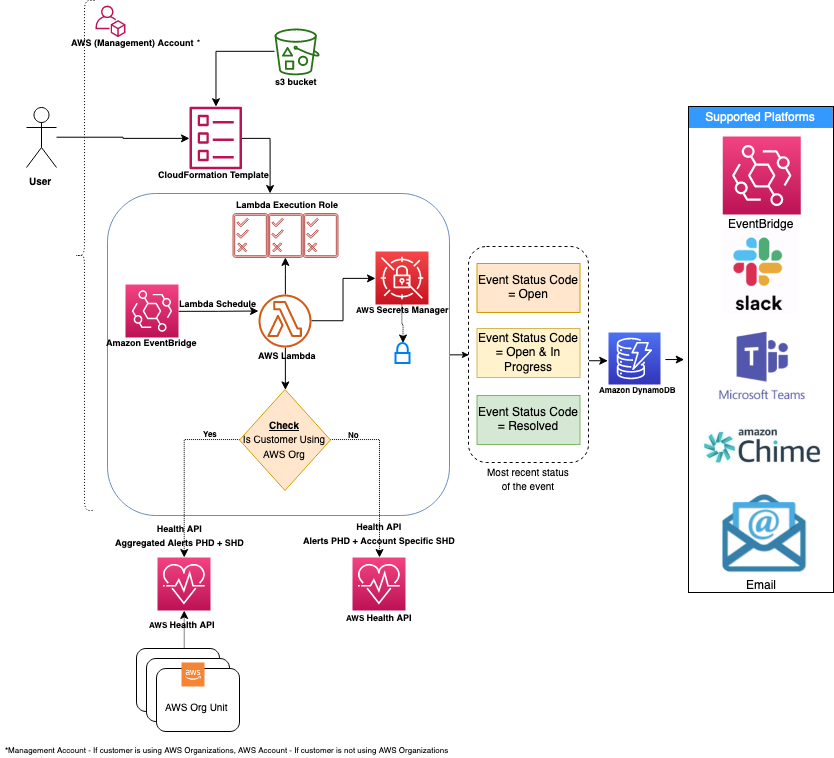
-
Amazon CloudWatch Application Insights를 활용하여 리소스에 대한 최적의 모니터를 설정하고, 애플리케이션의 문제 징후를 지속적으로 분석합니다. 또한 모니터링 대상 애플리케이션의 잠재적 문제를 보여주는 자동화된 대시보드를 제공하여 애플리케이션/인프라 문제를 신속하게 격리하고 해결할 수 있습니다. Container Insights를 활용하여 컨테이너의 메트릭과 로그를 집계하고, CloudWatch Application Insights와 원활하게 통합할 수 있습니다.
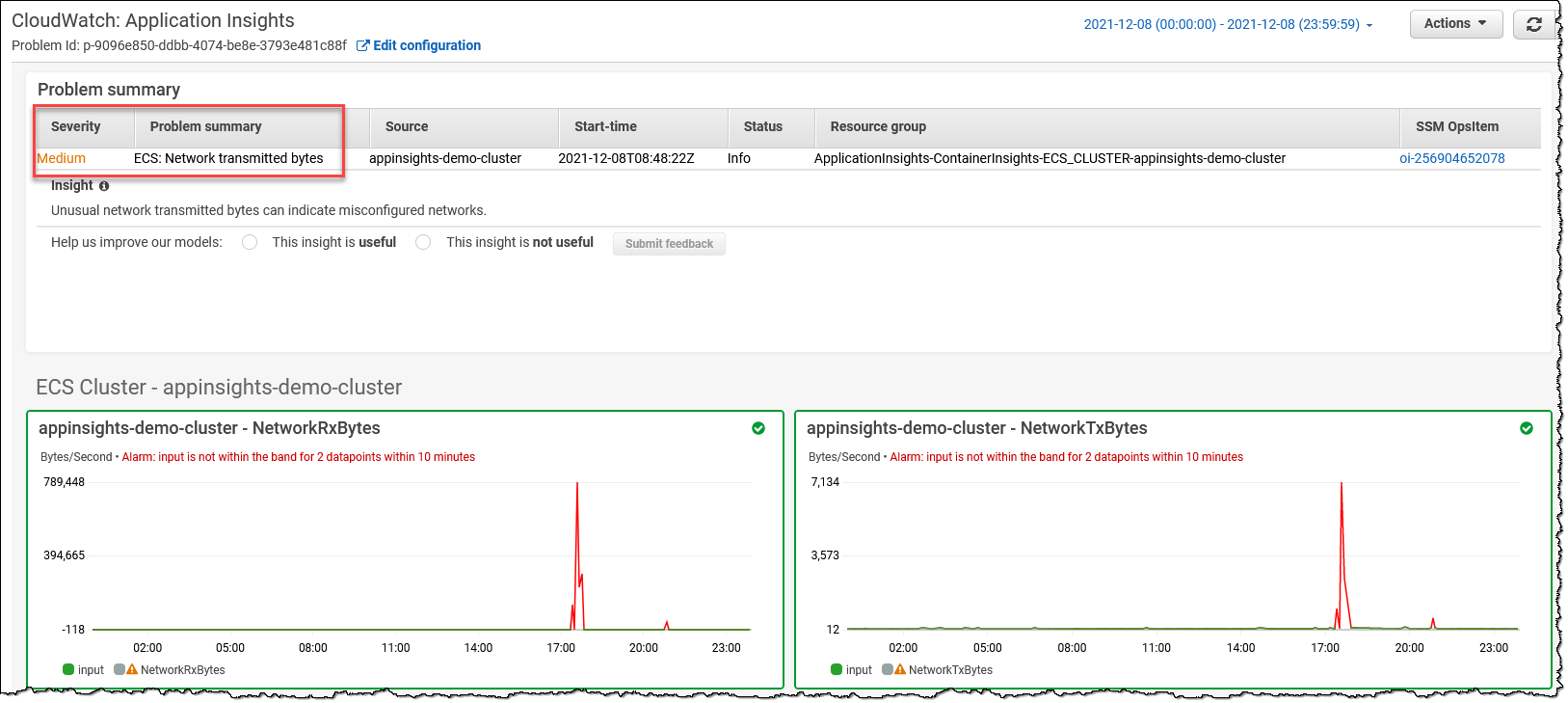
-
AWS Resilience Hub를 활용하여 정의된 RTO 및 RPO에 대해 애플리케이션을 분석합니다. AWS Fault Injection Simulator와 같은 도구를 사용한 통제된 실험을 통해 가용성, 지연 시간, 비즈니스 연속성 요구사항이 충족되는지 검증합니다. 추가적인 Well-Architected 검토 및 서비스별 심층 분석을 수행하여 워크로드가 AWS 모범 사례에 따라 비즈니스 요구사항을 충족하도록 설계되었는지 확인합니다.
-
자세한 ��내용은 AWS Observability Best Practices 가이드의 다른 섹션, AWS Cloud Adoption Framework: Operations Perspective 백서, 그리고 AWS Well-Architected Framework Operational Excellence 필러 백서의 'Understading workload health' 콘텐츠를 참조하세요.
3.2 도메인별 TLG (비즈니스 메트릭, 즉 UX, BX 중심)
아래에 CloudWatch(CW) 등의 서비스를 활용한 적절한 예시가 제공됩니다 (참조: CloudWatch 메트릭을 게시하는 AWS 서비스 문서)
3.2.1 Canary (합성 트랜잭션) 및 Real-User Monitoring (RUM)
- TLG: 고객 경험을 이해하는 가장 쉽고 효과적인 방법 중 하나는 Canary(합성 트랜잭션)를 사용하여 고객 트래픽을 시뮬레이션하는 것으로, 정기적으로 서비스를 프로빙하고 메트릭을 기록합니다.
| AWS 서비스 | 기능 | 측정 항목 | 메트릭 | 예시 | 참고 |
|---|---|---|---|---|---|
| CW | Synthetics | 가용성 | SuccessPercent | (예: SuccessPercent > 90 또는 1분 주기 CW 이상 탐지) **[Metric Math에서 m1이 SuccessPercent이고 Canary가 평일 오전 7시-8시에 실행되는 경우 (CloudWatchSynthetics): ** IF(((DAY(m1)<6) AND (HOUR(m1)>7 AND HOUR(m1)<8)),m1)] | |
| CW | Synthetics | 가용성 | VisualMonitoringSuccessPercent | (예: UI 스크린샷 비교를 위한 5분 주기 VisualMonitoringSuccessPercent > 90) **[Metric Math에서 m1이 SuccessPercent이고 Canary가 평일 오전 7시-8시에 실행되는 경우 (CloudWatchSynthetics): ** IF(((DAY(m1)<6) AND (HOUR(m1)>7 AND HOUR(m1)<8)),m1) | 고객이 Canary가 사전 정의된 UI 스크린샷과 일치하기를 기대하는 경우 |
| CW | RUM | 응답 시간 | Apdex Score | (예: Apdex 점수: NavigationFrustratedCount < 'N' 기대값) | |
3.2.2 API 프론트엔드
| AWS 서비스 | 기능 | 측정 항목 | 메트릭 | 예시 | 참고 |
|---|---|---|---|---|---|
| CloudFront | 가용성 | Total error rate | (예: [Total error rate] < 10 또는 1분 주기 CW 이상 탐지) | 오류율로 측정한 가용성 | |
| CloudFront | (추가 메트릭 활성화 필요) | 성능 | Cache hit rate | (예: Cache hit rate < 10, 1분 주기 CW 이상 탐지) | |
| Route53 | Health checks | (교차 리전) 가용성 | HealthCheckPercentageHealthy | (예: [HealthCheckPercentageHealthy의 최솟값] > 90 또는 1분 주기 CW 이상 탐지) | |
| Route53 | Health checks | 지연 시간 | TimeToFirstByte | (예: [p99 TimeToFirstByte] < 100 ms 또는 1분 주기 CW 이상 탐지) | |
| API Gateway | 가용성 | Count | (예: [(4XXError + 5XXError) / Count) * 100] < 10 또는 1분 주기 CW 이상 탐지) | "버려진" 요청으로 측정한 가용성 | |
| API Gateway | 지연 시간 | Latency (또는 IntegrationLatency, 즉 백엔드 지연 시간) | (예: p99 Latency < 1초 또는 1분 주기 CW 이상 탐지) | p99는 p90과 같은 낮은 백분위수보다 허용 범위가 넓습니다. (p50은 평균과 동일) | |
| API Gateway | 성능 | CacheHitCount (및 Misses) | (예: [CacheMissCount / (CacheHitCount + CacheMissCount) * 100] < 10 또는 1분 주기 CW 이상 탐지) | 캐시(미스)로 측정한 성능 | |
| Application Load Balancer (ALB) | 가용성 | RejectedConnectionCount | (예: [RejectedConnectionCount/(RejectedConnectionCount + RequestCount) * 100] < 10, 1분 주기 CW 이상 탐지) | 최대 연결 수 초과로 거부된 요청으로 측정한 가용성 | |
| Application Load Balancer (ALB) | 지연 시간 | TargetResponseTime | (예: p99 TargetResponseTime < 1초 또는 1분 주기 CW 이상 탐지) | p99는 p90과 같은 낮은 백분위수보다 허용 범위가 넓습니다. (p50은 평균과 동일) | |
3.2.3 서버리스
| AWS 서비스 | 기능 | 측정 항목 | 메트릭 | 예시 | 참고 |
|---|---|---|---|---|---|
| S3 | Request metrics | 가용성 | AllRequests | (예: [(4XXErrors + 5XXErrors) / AllRequests) * 100] < 10 또는 1분 주기 CW 이상 탐지) | "버려진" 요청으로 측정한 가용성 |
| S3 | Request metrics | (전체) 지연 시간 | TotalRequestLatency | (예: [p99 TotalRequestLatency] < 100 ms 또는 1분 주기 CW 이상 탐지) | |
| DynamoDB (DDB) | 가용성 | ThrottledRequests | (예: [ThrottledRequests] < 100 또는 1분 주기 CW 이상 탐지) | "스로틀된" 요청으로 측정한 가용성 | |
| DynamoDB (DDB) | 지연 시간 | SuccessfulRequestLatency | (예: [p99 SuccessfulRequestLatency] < 100 ms 또는 1분 주기 CW 이상 탐지) | ||
| Step Functions | 가용성 | ExecutionsFailed | (예: ExecutionsFailed = 0) **[예: Metric Math에서 m1이 ExecutionsFailed(Step Function 실행) UTC 시간인 경우: IF(((DAY(m1)<6 OR ** ** DAY(m1)==7) AND (HOUR(m1)>21 AND HOUR(m1)<7)),m1)] | 평일 오후 9시-오전 7시에 Step Functions 완료를 요구하는 비즈니스 흐름을 가정 (업무 시작 시점 운영) | |
3.2.4 컴퓨팅 및 컨테이너
| AWS 서비스 | 기능 | 측정 항목 | 메트릭 | 예시 | 참고 |
|---|---|---|---|---|---|
| EKS | Prometheus metrics | 가용성 | APIServer Request Success Ratio | (예: APIServer Request Success Ratio과 같은 Prometheus 메트릭) | EKS 컨트롤 플레인 메트릭 모니터링 모범 사례 및 EKS Observability에서 자세한 내용을 확인하세요. |
| EKS | Prometheus metrics | 성능 | apiserver_request_duration_seconds, etcd_request_duration_seconds | apiserver_request_duration_seconds, etcd_request_duration_seconds | |
| ECS | 가용성 | Service RUNNING task count | Service RUNNING task count | ECS CW 메트릭 문서 참조 | |
| ECS | 성능 | TargetResponseTime | (예: [p99 TargetResponseTime] < 100 ms 또는 1분 주기 CW 이상 탐지) | ECS CW 메트릭 문서 참조 | |
| EC2 (.NET Core) | CW Agent Performance Counters | 가용성 | (예: ASP.NET Application Errors Total/Sec < 'N') | (예: ASP.NET Application Errors Total/Sec < 'N') | EC2 CW Application Insights 문서 참조 |
3.2.5 데이터베이스 (RDS)
| AWS 서비스 | 기능 | 측정 항목 | 메트릭 | 예시 | 참고 |
|---|---|---|---|---|---|
| RDS Aurora | Performance Insights (PI) | 가용성 | Average active sessions | (예: 1분 주기 CW 이상 탐지를 활용한 Average active sessions) | RDS Aurora CW PI 문서 참조 |
| RDS Aurora | 재해 복구 (DR) | AuroraGlobalDBRPOLag | (예: AuroraGlobalDBRPOLag < 30000 ms, 1분 주기) | RDS Aurora CW 문서 참조 | |
| RDS Aurora | 성능 | Commit Latency, Buffer Cache Hit Ratio, DDL Latency, DML Latency | (예: 1분 주기 CW 이상 탐지를 활용한 Commit Latency) | RDS Aurora CW PI 문서 참조 | |
| RDS (MSSQL) | PI | 성능 | SQL Compilations | (예: SQL Compilations > 'M', 5분 주기) | RDS CW PI 문서 참조 |
4.0 Amazon CloudWatch와 Metric Math를 활용한 SLI, SLO, SLA 계산
4.1 Amazon CloudWatch와 Metric Math
Amazon CloudWatch는 AWS 리소스에 대한 모니터링 및 Observability 서비스를 제공합니다. Metric Math를 사용하면 CloudWatch 메트릭 데이터를 활용한 계산이 가능하여, SLI, SLO, SLA를 계산하는 데 이상적인 도구입니다.
4.1.1 상세 모니터링 활성화
AWS 리소스에 대해 Detailed Monitoring을 활성화하면 1분 단위의 데이터 세분성을 확보하여 더 정확한 SLI 계산이 가능합니다.
4.1.2 네임스페이스와 차원으로 메트릭 정리
분석을 용이하게 하기 위해 Namespace와 Dimension을 사용하여 메트릭을 분류하고 필터링합니다. 예를 들어, Namespace를 사용하여 특정 서비스 관련 메트릭을 그룹화하고, Dimension을 사용하여 해당 서비스의 다양한 인스턴스를 구분할 수 있습니다.
4.2 Metric Math를 활용한 SLI 계산
4.2.1 가용성
가용성을 계산하려면 성공한 요청 수를 전체 요청 수로 나눕니다:
availability = 100 * (successful_requests / total_requests)
예시:
다음 메트릭을 가진 API Gateway가 있다고 가정합니다:
4XXError: 4xx 클라이언트 오류 수5XXError: 5xx 서버 오류 수Count: 전체 요청 수
Metric Math를 사용하여 가용성을 계산합니다:
availability = 100 * ((Count - 4XXError - 5XXError) / Count)
4.2.2 지연 시간
평균 지연 시간을 계산하려면 CloudWatch에서 제공하는 SampleCount와 Sum 통계를 사용합니다:
average_latency = Sum / SampleCount
예시:
다음 메트릭을 가진 Lambda 함수가 있다고 가정합니다:
Duration: 함수 실행에 걸린 시간
Metric Math를 사용하여 평균 지연 시간을 계산합니다:
average_latency = Duration.Sum / Duration.SampleCount
4.2.3 오류율
오류율을 계산하려면 실패한 요청 수를 전체 요청 수로 나눕니다:
error_rate = 100 * (failed_requests / total_requests)
예시:
앞서의 API Gateway 예시를 활용합니다:
error_rate = 100 * ((4XXError + 5XXError) / Count)
4.4 SLO 정의 및 모니터링
4.4.1 현실적인 목표 설정
사용자 기대치와 과거 성능 데이터를 기반으로 SLO 목표를 정의합니다. 서비스 신뢰성과 리소스 활용 간의 균형을 보장하기 위해 달성 가능한 목표를 설정합니다.
4.4.2 CloudWatch를 활용한 SLO 모니터링
CloudWatch Alarm을 생성하여 SLI를 모니터링하고, SLO 목표에 근접하거나 이를 위반할 때 알림을 받습니다. 이를 통해 문제를 사전에 해결하고 서비스 신뢰성을 유지할 수 있습니다.
4.4.3 SLO 검토 및 조정
서비스가 발전함에 따라 SLO가 여전히 적절한지 주기적으로 검토합니다. 필요한 경우 목표를 조정하고, 변경 사항을 이해관계자에게 전달합니다.
4.5 SLA 정의 및 측정
4.5.1 현실적인 목표 설정
과거 성능 데이터와 사용자 기대치를 기반으로 SLA 목표를 정의합니다. 서비스 신뢰성과 리소스 활용 간의 균형을 보장하기 위해 달성 가능한 목표를 설정합니다.
4.5.2 모니터링 및 알림
CloudWatch Alarm을 설정하여 SLI를 모니터링하고, SLA 목표에 근접하거나 이를 위반할 때 알림을 받습니다. 이를 통해 문제를 사전에 해결하고 서비스 신뢰성을 유지할 수 있습니다.
4.5.3 정기적인 SLA 검토
서비스가 발전함에 따라 SLA가 여전히 적절한지 주기적으로 검토합니다. 필요한 경우 목표를 조정하고, 변경 사항을 이해관계자에게 전달합니다.
4.6 설정 기간 동안의 SLA 또는 SLO 성과 측정
달력 월과 같은 설정 기간 동안의 SLA 또는 SLO 성과를 측정하려면 사용자 정의 시간 범위를 적용한 CloudWatch 메트릭 데이터를 사용합니다.
예시:
SLO 목표가 99.9% 가용성인 API Gateway가 있다고 가정합니다. 4월의 가용성을 측정하려면 다음 Metric Math 수식을 사용합니다:
availability = 100 * ((Count - 4XXError - 5XXError) / Count)
그런 다음 사용자 정의 시간 범위로 CloudWatch 메트릭 데이터 쿼리를 구성합니다:
- Start Time:
2023-04-01T00:00:00Z - End Time:
2023-04-30T23:59:59Z - Period:
2592000(30일을 초 단위로 환산)
마지막으로 AVG 통계를 사용하여 해당 월의 평균 가용성을 계산합니다. 평균 가용성이 SLO 목표와 같거나 그 이상이면 목표를 달성한 것입니다.
5.0 요약
핵심 성과 지표(KPI), 즉 '골든 시그널'은 비즈니스 및 이해관계자의 요구사항에 부합해야 합니다. Amazon CloudWatch와 Metric Math를 활용하여 SLI, SLO, SLA를 계산하는 것은 서비스 신뢰성 관리에 필수적입니다. 이 가이드에 설명된 모범 사례를 따라 AWS 리소스의 성능을 효과적으로 모니터링하고 유지하세요. Detailed Monitoring 활성화, Namespace와 Dimension을 통한 메트릭 정리, SLI 계산을 위한 Metric Math 활용, 현실적인 SLO 및 SLA 목표 설정, CloudWatch Alarm을 통한 모니터링 및 알림 시스템 구축을 기억하세요. 이러한 모범 사례를 적용하면 최적의 서비스 신뢰성, 더 나은 리소스 활용, 그리고 향상된 고객 만족도를 보장할 수 있습니다.