Amazon Managed Service for Prometheus Alert Manager
소개
Amazon Managed Service for Prometheus(AMP)는 'Recording rules'와 'Alerting rules' 두 가지 유형의 규칙을 지원하며, 기존 Prometheus 서버에서 가져올 수 있고 정기적인 간격으로 평가됩니다.
Alerting rules를 사용하면 PromQL과 임계값을 기반으로 알림 조건을 정의할 수 있습니다. 알림 규칙의 값이 임계값을 초과하면 Amazon Managed Service for Prometheus의 Alert Manager로 알림이 전송되며, 이는 독립형 Prometheus의 Alert Manager와 유사한 기능을 제공합니다. 알림은 Prometheus에서 알림 규칙이 활성 상태일 때 발생하는 결과입니다.
알림 규칙 파일
Amazon Managed Service for Prometheus의 알림 규칙은 YAML 형식의 규칙 파일로 정의되며, 독립형 Prometheus의 규칙 파일과 동일한 형식을 따릅니다. 하나의 Amazon Managed Service for Prometheus 워크스페이스에 여러 규칙 파일을 보유할 수 있습니다. 워크스페이스는 Prometheus 메트릭의 저장 및 쿼리를 위한 논리적 공간입니다.
규칙 파일은 일반적으로 다음과 같은 필드를 포함합니다:
groups:
- name:
rules:
- alert:
expr:
for:
labels:
annotations:
Groups: 일정한 간격으로 순차적으로 실행되는 규칙의 모음
Name: 그룹의 이름
Rules: 그룹 내의 규칙들
Alert: 알림의 이름
Expr: 알림을 트리거하기 위한 표현식
For: 알림의 표현식이 임계값을 초과한 후 발생(firing) 상태로 전환되기까지의 최소 지속 시간
Labels: 알림에 첨부되는 추가 레이블
Annotations: 설명이나 링크 등의 상황별 세부 정보
다음은 규칙 파일의 예시입니다.
groups:
- name: test
rules:
- record: metric:recording_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m]))
- name: alert-test
rules:
- alert: metric:alerting_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m])) > 0
for: 2m
Alert Manager 구성 파일
Amazon Managed Service for Prometheus Alert Manager는 YAML 형식의 구성 파일을 사용하여 수신 서비스에 대한 알림을 설정하며, 이는 독립형 Prometheus의 Alert Manager 구성 파일과 동일한 구조를 가집니다. 구성 파일은 Alert Manager와 템플릿 작성을 위한 두 가지 핵심 섹션으로 구성됩니다.
-
template_files는 알림의 annotations와 labels 템플릿을 포함하며, 편의를 위해
$value,$labels,$externalLabels,$externalURL변수로 노출됩니다.$labels변수는 알림 인스턴스의 레이블 키/값 쌍을 담고 있습니다. 전역으로 구성된 외부 레이블은$externalLabels변수를 통해 접근할 수 있습니다.$value변수는 알림 인스턴스의 평가된 값을 담고 있습니다..Value,.Labels,.ExternalLabels,.ExternalURL은 각각 알림 값, 알림 레이블, 전역으로 구성된 외부 레이블, 외부 URL(--web.external-url로 구성)을 포함합니다. -
alertmanager_config는 독립형 Prometheus의 Alert Manager 구성 파일과 동일한 구조를 사용하는 Alert Manager 구성을 포함합니다.
다음은 template_files와 alertmanager_config를 모두 포함하는 Alert Manager 구성 파일의 예시입니다.
template_files:
default_template: |
{{ define "sns.default.subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]{{ end }}
{{ define "__alertmanager" }}AlertManager{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver | urlquery }}{{ end }}
alertmanager_config: |
global:
templates:
- 'default_template'
route:
receiver: default
receivers:
- name: 'default'
sns_configs:
- topic_arn: arn:aws:sns:us-east-2:accountid:My-Topic
sigv4:
region: us-east-2
attributes:
key: severity
value: SEV2
알림의 핵심 요소
Amazon Managed Service for Prometheus Alert Manager 구성 파일을 생성할 때 알아야 할 세 가지 중요한 측면이 있습니다.
- Grouping: 유사한 알림을 하나의 알림으로 묶어주는 기능으로, 장애나 서비스 중단의 영향 범위가 넓어 여러 시스템에 영향을 미치고 다수의 알림이 동시에 발생할 때 유용합니다. 또한 카테고리별로 그룹화하는 데에도 사용할 수 있습니다(예: 노드 알림, 파드 알림). Alert Manager 구성 파일의 route 블록을 사용하여 이 그룹화를 구성할 수 있습니다.
- Inhibition: 이미 활성화되어 발생 중인 유사한 알림의 스팸을 방지하기 위해 특정 알림을 억제하는 방법입니다. inhibit_rules 블록을 사용하여 억제 규칙을 작성할 수 있습니다.
- Silencing: 유지보수 기간이나 계획된 서비스 중단 등 특정 기간 동안 알림을 음소거할 수 있습니다. 수신되는 알림은 음소거하기 전에 모든 일치 조건이나 정규 표현식과 대조하여 검증됩니다. PutAlertManagerSilences API를 사용하여 음소거를 생성할 수 있습니다.
Amazon Simple Notification Service (SNS)를 통한 알림 라우팅
현재 Amazon Managed Service for Prometheus Alert Manager는 Amazon SNS만을 수신자로 지원합니다. alertmanager_config 블록의 핵심 섹션은 receivers이며, 이를 통해 Amazon SNS가 알림을 수신하도록 구성할 수 있습니다. 다음 섹션을 receivers 블록의 템플릿으로 사용할 수 있습니다.
- name: name_of_receiver
sns_configs:
- sigv4:
region: <AWS_Region>
topic_arn: <ARN_of_SNS_topic>
subject: somesubject
attributes:
key: <somekey>
value: <somevalue>
Amazon SNS 구성은 명시적으로 재정의하지 않는 한 다음 템플릿을 기본값으로 사용합니다.
{{ define "sns.default.message" }}{{ .CommonAnnotations.SortedPairs.Values | join " " }}
{{ if gt (len .Alerts.Firing) 0 -}}
Alerts Firing:
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
Alerts Resolved:
{{ template "__text_alert_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
추가 참고 자료: Notification Template Examples
Amazon SNS 이외의 다른 대상으로 알림 라우팅
Amazon Managed Service for Prometheus Alert Manager는 Amazon SNS를 통해 다른 대상인 이메일, 웹훅(HTTP), Slack, PagerDuty, OpsGenie 등에 연결할 수 있습니다.
- Email 알림이 성공적으로 전송되면 Amazon SNS 토픽의 대상 중 하나로서 Amazon Managed Service for Prometheus Alert Manager를 통해 알림 세부 정보가 포함된 이메일을 수신하게 됩니다.
- Amazon Managed Service for Prometheus Alert Manager는 JSON 형식으로 알림을 전송할 수 있어, Amazon SNS 이후 AWS Lambda 또는 웹훅 수신 엔드포인트에서 후속 처리를 할 수 있습니다.
- Webhook 기존 Amazon SNS 토픽을 웹훅 엔드포인트로 메시지를 출력하도록 구성할 수 있습니다. 웹훅은 이벤트 기반 트리거에 의해 애플리케이션 간에 HTTP를 통해 교환되는 직렬화된 폼 인코딩 JSON 또는 XML 형식의 메시지입니다. 이를 통해 기존의 SIEM 또는 협업 도구를 연결하여 알림, 티켓팅 또는 인시던트 관리 시스템으로 활용할 수 있습니다.
- Slack Slack의 이메일-채널 통합 기능을 사용하여 Slack이 이메일을 수신하고 이를 Slack 채널로 전달하도록 하거나, Lambda 함수를 사용하여 SNS 알림을 Slack 형식으로 변환할 수 있습니다.
- PagerDuty
alertmanager_config정의의template_files블록에서 사용하는 템플릿을 커스터마이즈하여 Amazon SNS의 대상인 PagerDuty로 페이로드를 전송할 수 있습니다.
추가 참고 자료: Custom Alert manager Templates
알림 상태
알림 규칙은 표현식을 기반으로 알림 조건을 정의하며, 설정된 임계값이 초과될 때마다 알림 서비스로 알림을 전송합니다. 다음은 규칙과 표현식의 예시입니다.
rules:
- alert: metric:alerting_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m])) > 0
for: 2m
알림 표현식의 결과로 특정 시점에 하나 이상의 벡터 요소가 반환되면 해당 알림은 활성 상태로 간주됩니다. 알림은 활성(pending | firing) 또는 해결됨(resolved) 상태를 가집니다.
- Pending: 임계값 위반 이후 경과된 시간이 기록 간격보다 짧은 상태
- Firing: 임계값 위반 이후 경과된 시간이 기록 간격보다 길어 Alert Manager가 알림을 라우팅하고 있는 상태
- Resolved: 임계값이 더 이상 위반되지 않아 알림이 더 이상 발생하지 않는 상태
이는 awscurl 명령어를 사용하여 ListAlerts API로 Amazon Managed Service for Prometheus Alert Manager 엔드포인트를 쿼리하여 수동으로 확인할 수 있습니다. 다음은 요청 예시입니다.
awscurl https://aps-workspaces.us-east-1.amazonaws.com/workspaces/$WORKSPACE_ID/alertmanager/api/v2/alerts --service="aps" -H "Content-Type: application/json"
Amazon Managed Grafana에서의 Amazon Managed Service for Prometheus Alert Manager 규칙
Amazon Managed Grafana(AMG)의 알림 �기능을 통해 Amazon Managed Grafana 워크스페이스에서 Amazon Managed Service for Prometheus Alert Manager 알림을 시각화할 수 있습니다. Amazon Managed Service for Prometheus 워크스페이스를 사용하여 Prometheus 메트릭을 수집하는 고객은 서비스의 완전 관리형 Alert Manager 및 Ruler 기능을 활용하여 알림 및 기록 규칙을 구성합니다. 이 기능을 통해 Amazon Managed Service for Prometheus 워크스페이스에 구성된 모든 알림 및 기록 규칙을 시각화할 수 있습니다. Prometheus 알림 보기는 Amazon Managed Grafana(AMG) 콘솔의 Workspace 구성 옵션 탭에서 Grafana alerting 체크박스를 선택하여 활성화할 수 있습니다. 활성화하면 이전에 Grafana 대시보드에서 생성한 네이티브 Grafana 알림도 Grafana 워크스페이스의 새로운 Alerting 페이지로 마이그레이션됩니다.
참고 자료: Announcing Prometheus Alert manager rules in Amazon Managed Grafana
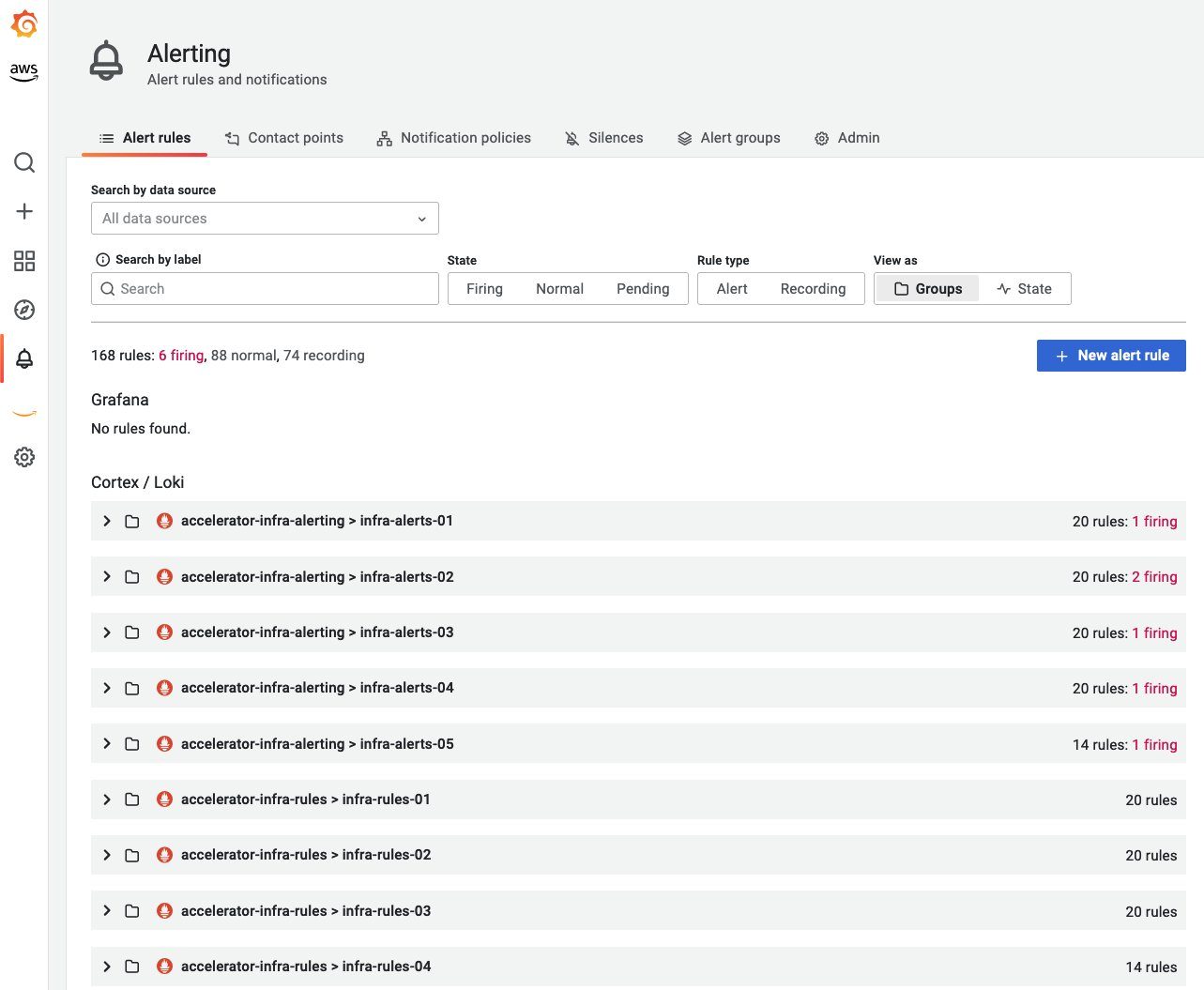
기본 모니터링을 위한 권장 알림
알림은 견고한 모니터링 및 Observability 모범 사례의 핵심 요소입니다. 알림 메커니즘은 알림 피로도와 중요한 알림 누락 사이에서 적절한 균형을 이루어야 합니다. 다음은 워크로드의 전반적인 안��정성을 개선하기 위해 권장되는 알림입니다. 조직 내 다양한 팀은 인프라와 워크로드를 각기 다른 관점에서 모니터링하므로, 요구사항과 시나리오에 따라 확장하거나 변경할 수 있으며 이는 포괄적인 목록이 아닙니다.
- 컨테이너 노드가 할당된 메모리 한도의 특정 비율(예: 80%) 이상을 사용하고 있는 경우
- 컨테이너 노드가 할당된 CPU 한도의 특정 비율(예: 80%) 이상을 사용하고 있는 경우
- 컨테이너 노드가 할당된 디스크 공간의 특정 비율(예: 90%) 이상을 사용하고 있는 경우
- 네임스페이스 내 파드의 컨테이너가 할당된 CPU 한도의 특정 비율(예: 80%) 이상을 사용하고 있는 경우
- 네임스페이스 내 파드의 컨테이너가 메모리 한도의 특정 비율(예: 80%) 이상을 사용하고 있는 경우
- 네임스페이스 내 파드의 컨테이너가 너무 많이 재시작된 경우
- 네임스페이스의 Persistent Volume이 특정 비율(최대 75%) 이상의 디스크 공간을 사용하고 있는 경우
- Deployment에 현재 실행 중인 활성 파드가 없는 경우
- 네임스페이스의 Horizontal Pod Autoscaler(HPA)가 최대 용량에서 실행되고 있는 경우
위의 시나리오 또는 유사한 시나리오에 대한 알림을 설정할 때 핵심은 필요에 따라 표현식을 변경하는 것입니다. 예를 들면 다음과 같습니다.
expr: |
((sum(irate(container_cpu_usage_seconds_total{image!="",container!="POD", namespace!="kube-sys"}[30s])) by (namespace,container,pod) /
sum(container_spec_cpu_quota{image!="",container!="POD", namespace!="kube-sys"} /
container_spec_cpu_period{image!="",container!="POD", namespace!="kube-sys"}) by (namespace,container,pod) ) * 100) > 80
for: 5m
Amazon Managed Service for Prometheus용 ACK Controller
Amazon Managed Service for Prometheus AWS Controller for Kubernetes(ACK) 컨트롤러는 Workspace, Alert Manager, Ruler 리소스에 대해 사용할 수 있으며, 커스텀 리소스 정의(CRD)와 네이티브 객체 또는 서비스를 사용하여 Kubernetes 클러스터 외부에 리소스를 정의할 필요 없이 Prometheus를 활용할 수 있게 합니다. Amazon Managed Service for Prometheus용 ACK 컨트롤러를 사용하면 모니터링 중인 Kubernetes 클러스터에서 직접 모든 리소스를 관리할 수 있어, Kubernetes가 워크로드의 원하는 상태에 대한 '단일 진실 공급원(source of truth)'으로 기능합니다. ACK는 Kubernetes API를 확장하고 AWS 리소스를 관리하기 위해 함께 작동하는 Kubernetes CRD와 커스텀 컨트롤러의 모음입니다.
다음은 ACK를 사용하여 구성된 알림 규칙의 예시입니다:
apiVersion: prometheusservice.services.k8s.aws/v1alpha1
kind: RuleGroupsNamespace
metadata:
name: default-rule
spec:
workspaceID: WORKSPACE-ID
name: default-rule
configuration: |
groups:
- name: example
rules:
- alert: HostHighCpuLoad
expr: 100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 60
for: 5m
labels:
severity: warning
event_type: scale_up
annotations:
summary: Host high CPU load (instance {{ $labels.instance }})
description: "CPU load is > 60%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostLowCpuLoad
expr: 100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) < 30
for: 5m
labels:
severity: warning
event_type: scale_down
annotations:
summary: Host low CPU load (instance {{ $labels.instance }})
description: "CPU load is < 30%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
IAM 정책을 사용한 규칙 접근 제한
조직에서는 다양한 팀이 각자의 기록 및 알림 요구사항에 맞는 자체 규칙을 생성하고 관리해야 합니다. Amazon Managed Service for Prometheus의 규칙 관리에서는 AWS Identity and Access Management(IAM) 정책을 사용하여 규칙에 대한 접근을 제어할 수 있으므로, 각 팀이 rulegroupnamespace별로 그룹화된 자체 규칙과 알림 세트를 관리할 수 있습니다.
아래 이미지는 Amazon Managed Service for Prometheus의 규칙 관리에 추가된 devops와 engg라는 두 개의 rulegroupnamespace 예시를 보여줍니다.
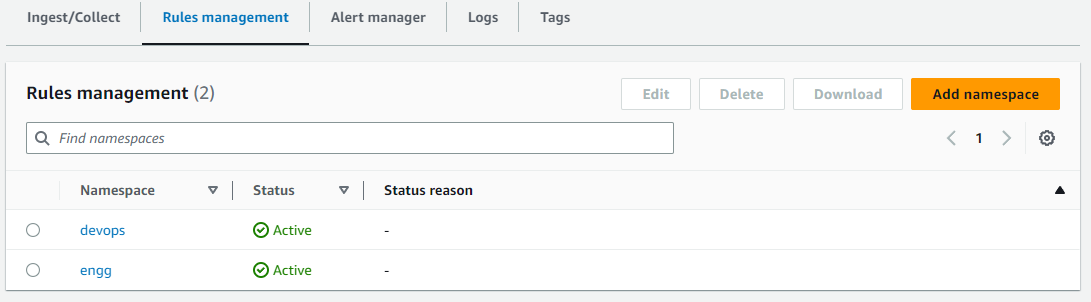
아래 JSON은 Resource ARN을 지정하여 devops rulegroupnamespace(위에 표시됨)에 대한 접근을 제한하는 IAM 정책 예시입니다. 이 IAM 정책에서 주목할 액션은 PutRuleGroupsNamespace와 DeleteRuleGroupsNamespace이며, AMP 워크스페이스의 지정된 rulegroupsnamespace Resource ARN으로 제한됩니다. 정책이 생성되면 원하는 접근 제어 요구사항에 따라 사용자, 그룹 또는 역할에 할당할 수 있습니다. IAM 정책의 Action은 필요한 허용 액션에 대한 IAM 권한에 따라 수정/제한할 수 있습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"aps:RemoteWrite",
"aps:DescribeRuleGroupsNamespace",
"aps:PutRuleGroupsNamespace",
"aps:DeleteRuleGroupsNamespace"
],
"Resource": [
"arn:aws:aps:us-west-2:XXXXXXXXXXXX:workspace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx",
"arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops"
]
}
]
}
아래 awscli 상호작용은 IAM 정책에서 Resource ARN(즉, devops rulegroupnamespace)을 통해 특정 rulegroupnamespace에 대한 제한된 접근 권한을 가진 IAM 사용자의 예시를 보여주며, 동일한 사용자가 접근 권한이 없는 다른 리소스(즉, engg rulegroupnamespace)에 대해 어떻게 접근이 거부되는지를 보여줍니다.
$ aws amp describe-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name devops
{
"ruleGroupsNamespace": {
"arn": "arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops",
"createdAt": "2023-04-28T01:50:15.408000+00:00",
"data": "Z3JvdXBzOgogIC0gbmFtZTogZGV2b3BzX3VwZGF0ZWQKICAgIHJ1bGVzOgogICAgLSByZWNvcmQ6IG1ldHJpYzpob3N0X2NwdV91dGlsCiAgICAgIGV4cHI6IGF2ZyhyYXRlKGNvbnRhaW5lcl9jcHVfdXNhZ2Vfc2Vjb25kc190b3RhbFsybV0pKQogICAgLSBhbGVydDogaGlnaF9ob3N0X2NwdV91c2FnZQogICAgICBleHByOiBhdmcocmF0ZShjb250YWluZXJfY3B1X3VzYWdlX3NlY29uZHNfdG90YWxbNW1dKSkKICAgICAgZm9yOiA1bQogICAgICBsYWJlbHM6CiAgICAgICAgICAgIHNldmVyaXR5OiBjcml0aWNhbAogIC0gbmFtZTogZGV2b3BzCiAgICBydWxlczoKICAgIC0gcmVjb3JkOiBjb250YWluZXJfbWVtX3V0aWwKICAgICAgZXhwcjogYXZnKHJhdGUoY29udGFpbmVyX21lbV91c2FnZV9ieXRlc190b3RhbFs1bV0pKQogICAgLSBhbGVydDogY29udGFpbmVyX2hvc3RfbWVtX3VzYWdlCiAgICAgIGV4cHI6IGF2ZyhyYXRlKGNvbnRhaW5lcl9tZW1fdXNhZ2VfYnl0ZXNfdG90YWxbNW1dKSkKICAgICAgZm9yOiA1bQogICAgICBsYWJlbHM6CiAgICAgICAgc2V2ZXJpdHk6IGNyaXRpY2FsCg==",
"modifiedAt": "2023-05-01T17:47:06.409000+00:00",
"name": "devops",
"status": {
"statusCode": "ACTIVE",
"statusReason": ""
},
"tags": {}
}
}
$ cat > devops.yaml <<EOF
> groups:
> - name: devops_new
> rules:
> - record: metric:host_cpu_util
> expr: avg(rate(container_cpu_usage_seconds_total[2m]))
> - alert: high_host_cpu_usage
> expr: avg(rate(container_cpu_usage_seconds_total[5m]))
> for: 5m
> labels:
> severity: critical
> - name: devops
> rules:
> - record: container_mem_util
> expr: avg(rate(container_mem_usage_bytes_total[5m]))
> - alert: container_host_mem_usage
> expr: avg(rate(container_mem_usage_bytes_total[5m]))
> for: 5m
> labels:
> severity: critical
> EOF
$ base64 devops.yaml > devops_b64.yaml
$ aws amp put-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name devops --data file://devops_b64.yaml
{
"arn": "arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops",
"name": "devops",
"status": {
"statusCode": "UPDATING"
},
"tags": {}
}
$ aws amp describe-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg An error occurred (AccessDeniedException) when calling the DescribeRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:DescribeRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
$ aws amp put-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg --data file://devops_b64.yaml An error occurred (AccessDeniedException) when calling the PutRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:PutRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
$ aws amp delete-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg An error occurred (AccessDeniedException) when calling the DeleteRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:DeleteRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
규칙 사용에 대한 사용자 권한은 IAM 정책(문서 예시)을 사용하여 제한할 수도 있습니다.
자세한 정보는 AWS 문서를 참조하거나, Amazon Managed Service for Prometheus Alert Manager에 대한 AWS Observability Workshop을 확인하시기 바랍니다.
추가 참고 자료: Amazon Managed Service for Prometheus Is Now Generally Available with Alert Manager and Ruler