Amazon Managed Service for Prometheus Alert Manager
はじめに
Amazon Managed Service for Prometheus (AMP) は、「Recording rules」と「Alerting rules」の 2 種類のルールをサポートしており、既存の Prometheus サーバーからインポートして定期的に評価できます。
アラートルールを使用すると、PromQL としきい値に基づいてアラート条件を定義できます。アラートルールの値がしきい値を超えると、Amazon Managed Service for Prometheus の Alert manager に通知が送信されます。これは、スタンドアロン Prometheus の Alert manager と同様の機能を提供します。アラートは、Prometheus のアラートルールがアクティブになったときの結果です。
アラートルールファイル
Amazon Managed Service for Prometheus のアラートルールは、YAML 形式のルールファイルで定義されます。これは、スタンドアロン Prometheus のルールファイルと同じ形式に従います。お客様は、Amazon Managed Service for Prometheus ワークスペースに複数のルールファイルを持つことができます。ワークスペースは、Prometheus メトリクスの保存とクエリに専用の論理的なスペースです。
ルールファイルには通常、次のフィールドがあります。
groups:
- name:
rules:
- alert:
expr:
for:
labels:
annotations:
Groups: A collection of rules that are run sequentially at a regular interval
Name: Name of the group
Rules: The rules in a group
Alert: Name of the alert
Expr: The expression for the alert to trigger
For: Minimum duration for an alert’s expression to be exceeding threshold before updating to a firing status
Labels: Any additional labels attached to the alert
Annotations: Contextual details such as a description or link
サンプルのルールファイルは以下のようになります。
groups:
- name: test
rules:
- record: metric:recording_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m]))
- name: alert-test
rules:
- alert: metric:alerting_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m])) > 0
for: 2m
Alert Manager 設定ファイル
Amazon Managed Service for Prometheus Alert Manager は、YAML 形式の設定ファイルを使用して、スタンドアロン Prometheus のアラートマネージャー設定ファイルと同じ構造で、(受信サービスの) アラートを設定します。設定ファイルは、アラートマネージャーとテンプレート化の 2 つの主要なセクションで構成されています
-
template_files には、アラートで公開される注釈とラベルのテンプレートが含まれています
$value,$labels,$externalLabels、および$externalURL便利な変数です。$labels変数は、アラートインスタンスのラベルキー/値ペアを保持します。設定された外部ラベルには、次の方法でアクセスできます。$externalLabels変数。この$value変数には、アラートインスタンスの評価された値が保持されます。.Value,.Labels,.ExternalLabels、および.ExternalURLアラート値、アラートラベル、グローバルに設定された外部ラベル、および外部 URL(設定されたもの--web.external-url) をそれぞれ使用します。 -
alertmanager_config には、スタンドアロン Prometheus のアラートマネージャー設定ファイルと同じ構造を使用するアラートマネージャー設定が含まれています。
template_files と alertmanager_config の両方を含むサン��プルのアラートマネージャー設定ファイルは次のようになります。
template_files:
default_template: |
{{ define "sns.default.subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]{{ end }}
{{ define "__alertmanager" }}AlertManager{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver | urlquery }}{{ end }}
alertmanager_config: |
global:
templates:
- 'default_template'
route:
receiver: default
receivers:
- name: 'default'
sns_configs:
- topic_arn: arn:aws:sns:us-east-2:accountid:My-Topic
sigv4:
region: us-east-2
attributes:
key: severity
value: SEV2
アラートの重要な側面
Amazon Managed Service for Prometheus の Alert Manager 設定ファ�イルを作成する際に注意すべき 3 つの重要な点があります。
- グループ化: これは、類似したアラートを単一の通知に集約するのに役立ちます。障害や停止の影響範囲が大きく、多くのシステムに影響を与え、複数のアラートが同時に発火する場合に便利です。また、カテゴリ別にグループ化する場合にも使用できます (例: ノードアラート、Pod アラート)。アラートマネージャー設定ファイルの route ブロックを使用して、このグループ化を設定できます。
- 抑制: これは、すでにアクティブで発火している類似のアラートのスパムを回避するために、特定の通知を抑制する方法です。inhibit_rules ブロックを使用して、抑制ルールを記述できます。
- サイレンシング: アラートは、メンテナンスウィンドウや計画的な停止中など、指定された期間ミュートできます。受信したアラートは、アラートをサイレンシングする前に、すべての等価性または正規表現の一致が検証されます。PutAlertManagerSilences API を使用して、サイレンシングを作成できます。
Amazon Simple Notification Service (SNS) を通じてアラートをルーティングする
現在、Amazon Managed Service for Prometheus Alert Manager は Amazon SNS をサポートしています。これは唯一のレシーバーです。alertmanager_config ブロックの重要なセクションは receivers であり、これにより顧客はアラートを受信するように Amazon SNS を設定できます。次のセクションは、receivers ブロックのテンプレートとして使用できます。
- name: name_of_receiver
sns_configs:
- sigv4:
region: <AWS_Region>
topic_arn: <ARN_of_SNS_topic>
subject: somesubject
attributes:
key: <somekey>
value: <somevalue>
Amazon SNS 設定は、明示的にオーバーライドされない限り、デフォルトとして次のテンプレートを使用します。
{{ define "sns.default.message" }}{{ .CommonAnnotations.SortedPairs.Values | join " " }}
{{ if gt (len .Alerts.Firing) 0 -}}
Alerts Firing:
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
Alerts Resolved:
{{ template "__text_alert_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
追加リファレンス: 通知テンプレートの例
Amazon SNS 以外の宛先へのアラートのルーティング
Amazon Managed Service for Prometheus Alert Manager は、Amazon SNS を使用して他の送信先に接続できます。送信先には、メール、webhook (HTTP)、Slack、PageDuty、OpsGenie などがあります。
- Email 通知が成功すると、Amazon SNS トピックを通じて Amazon Managed Service for Prometheus Alert Manager からアラートの詳細を含むメールがターゲットの 1 つとして受信されます。
- Amazon Managed Service for Prometheus Alert Manager は JSON 形式でアラートを送信できるため、Amazon SNS から AWS Lambda または Webhook 受信エンドポイントでダウンストリーム処理できます。
- Webhook 既存の Amazon SNS トピックを設定して、Webhook エンドポイントにメッセージを出力できます。Webhook は、イベント駆動型トリガーに基づいてアプリケーション間で HTTP 経由で交換される、シリアル化されたフォームエンコード JSON または XML 形式のメッセージです。これを使用して、アラート、チケット発行、またはインシデント管理システム用の既存の SIEM またはコラボレーションツールと連携できます。
- Slack お客様は、Slack がメールを受け入れて Slack チャンネルに転送できる Slack のメールからチャンネルへの統合と連携するか、Lambda 関数を使用して SNS 通知を Slack に書き換えることができます。
- PagerDuty 使用されるテンプレート
template_filesブロック内のalertmanager_config定義をカスタマイズして、ペイロードを Amazon SNS の送信先として PagerDuty に送信できます。
追加リファレンス: カスタム Alert manager テンプレート
アラートステータス
アラートルールは、式に基づいてアラート条件を定義し、設定されたしきい値を超えた場合に任意の通知サービスにアラートを送信します。ルールとその式の例を以下に示します。
rules:
- alert: metric:alerting_rule
expr: avg(rate(container_cpu_usage_seconds_total[5m])) > 0
for: 2m
アラート式が特定の時点で 1 つ以上のベクトル要素を生成すると、アラートはアクティブとしてカウントされます。アラートは、アクティブ (pending | firing) または resolved ステータスになります。
- Pending: しきい値違反からの経過時間が記録間隔未満です
- Firing: しきい値違反からの経過時間が記録間隔を超えており、Alert Manager がアラートをルーティングしています。
- Resolved: しきい値が違反されなくなったため、アラートは発火していません。
これは、awscurl コマンドを使用して ListAlerts API で Amazon Managed Service for Prometheus Alert Manager エンドポイントをクエリすることで手動で確認できます。サ�ンプルリクエストを以下に示します。
awscurl https://aps-workspaces.us-east-1.amazonaws.com/workspaces/$WORKSPACE_ID/alertmanager/api/v2/alerts --service="aps" -H "Content-Type: application/json"
Amazon Managed Grafana における Amazon Managed Service for Prometheus Alert Manager ルール
Amazon Managed Grafana (AMG) のアラート機能により、お客様は Amazon Managed Grafana ワークスペースから Amazon Managed Service for Prometheus Alert Manager のアラートを可視化できます。Amazon Managed Service for Prometheus ワークスペースを使用して Prometheus メトリクスを収集しているお客様は、サービス内のフルマネージド Alert Manager および Ruler 機能を利用して、アラートルールとレコーディングルールを設定します。この機能により、Amazon Managed Service for Prometheus ワークスペースで設定されたすべてのアラートルールとレコーディングルールを可視化できます。Prometheus アラートビューは、ワークスペース設定オプションタブで Grafana アラートのチェックボックスをオンにすることで、Amazon Managed Grafana (AMG) コンソールで表示できます。有効にすると、Grafana ダッシュボードで以前に作成されたネイティブ Grafana アラートも、Grafana ワークスペースの新しいアラートページに移行されます。
参考: Amazon Managed Grafana における Prometheus Alert manager ルールの発表
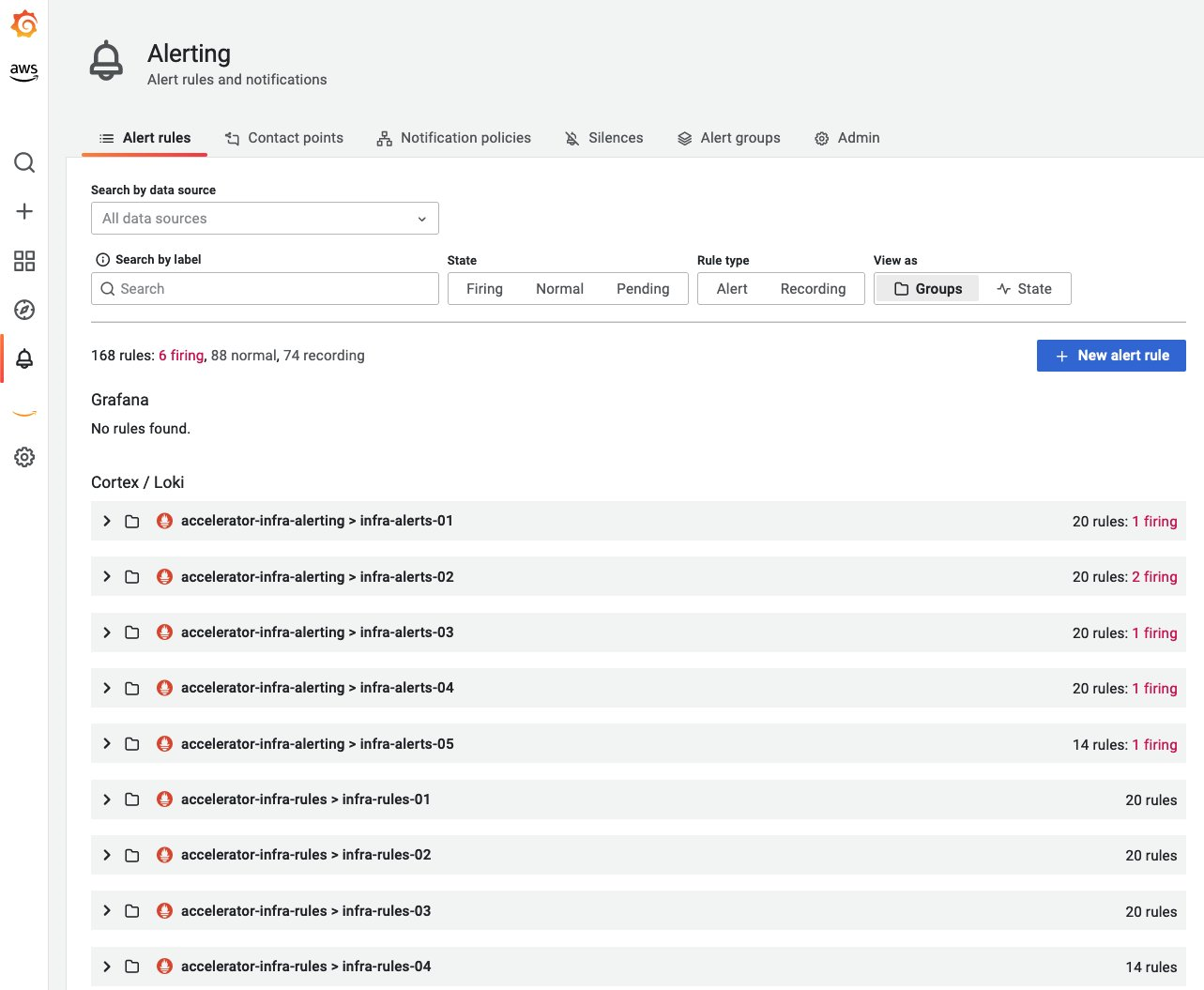
ベースライン監視に推奨されるアラート
アラートは、堅牢なモニタリングとオブザーバビリティのベストプラク�ティスの重要な側面です。アラートメカニズムは、アラート疲労と重要なアラートの見逃しのバランスを取る必要があります。ここでは、ワークロードの全体的な信頼性を向上させるために推奨されるアラートをいくつか紹介します。組織内のさまざまなチームは、異なる視点からインフラストラクチャとワークロードのモニタリングを検討するため、要件やシナリオに基づいて拡張または変更できます。これは包括的なリストではありません。
- コンテナノードが割り当てられたメモリ制限の一定値(例:80%)を超えて使用しています。
- コンテナノードが割り当てられた CPU 制限の一定値(例:80%)を超えて使用しています。
- コンテナノードが割り当てられたディスク容量の一定値(例:90%)を超えて使用しています。
- 名前空間内のポッド内のコンテナが割り当てられた CPU 制限の一定値(例:80%)を超えて使用しています。
- 名前空間内のポッド内のコンテナがメモリ制限の一定値(例:80%)を超えて使用しています。
- 名前空間内のポッド内のコンテナの再起動回数が多すぎます。
- 名前空間内の Persistent Volume がディスク容量の一定値(最大 75%)を超えて使用しています。
- Deployment で現在アクティブなポッドが実行されていません
- 名前空間内の Horizontal Pod Autoscaler (HPA) が最大容量で実行されています
上記または類似のシナリオでアラートを設定する際に重要なのは、必要に応じて式を変更することです。例えば、
expr: |
((sum(irate(container_cpu_usage_seconds_total{image!="",container!="POD", namespace!="kube-sys"}[30s])) by (namespace,container,pod) /
sum(container_spec_cpu_quota{image!="",container!="POD", namespace!="kube-sys"} /
container_spec_cpu_period{image!="",container!="POD", namespace!="kube-sys"}) by (namespace,container,pod) ) * 100) > 80
for: 5m
Amazon Managed Service for Prometheus 用 ACK Controller
Amazon Managed Service for Prometheus の AWS Controller for Kubernetes (ACK) コントローラーは、Workspace、Alert Manager、Ruler リソースに対して利用可能であり、Kubernetes クラスター外でリソースを定義することなく、カスタムリソース定義 (CRD) とネイティブオブジェクトまたはサポート機能を提供するサービスを使用して、Prometheus を活用できます。Amazon Managed Service for Prometheus の ACK コントローラーを使用すると、監視している Kubernetes クラスターからすべてのリソースを直接管理でき、Kubernetes をワークロードの望ましい状態の「信頼できる情報源」として機能させることができます。ACK は、Kubernetes API を拡張し AWS リソースを管理するために連携して動作する Kubernetes CRD とカスタムコントローラーのコレクションです。
ACK を使用して設定されたアラートルールのスニペットを以下に示します。
apiVersion: prometheusservice.services.k8s.aws/v1alpha1
kind: RuleGroupsNamespace
metadata:
name: default-rule
spec:
workspaceID: WORKSPACE-ID
name: default-rule
configuration: |
groups:
- name: example
rules:
- alert: HostHighCpuLoad
expr: 100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 60
for: 5m
labels:
severity: warning
event_type: scale_up
annotations:
summary: Host high CPU load (instance {{ $labels.instance }})
description: "CPU load is > 60%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostLowCpuLoad
expr: 100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) < 30
for: 5m
labels:
severity: warning
event_type: scale_down
annotations:
summary: Host low CPU load (instance {{ $labels.instance }})
description: "CPU load is < 30%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
IAM ポリシーを使用したルールへのアクセスの制限
組織では、さまざまなチームが記録とアラートの要件に応じて独自のルールを作成および管理する必要があります。Amazon Managed Service for Prometheus のルール管理では、AWS Identity and Access Management (IAM) ポリシーを使用してルールへのアクセスを制御できるため、各チームは rulegroupnamespaces でグループ化された独自のルールとアラートのセットを制御できます。
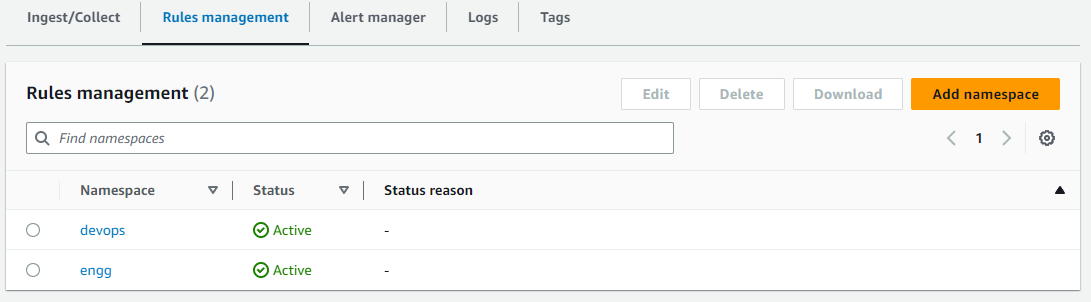
以下の画像は、Amazon Managed Service for Prometheus の Rules management に追加された devops と engg という 2 つのルールグループ名前空間の例を示しています。
以下の JSON は、上記の devops rulegroupnamespace へのアクセスを制限するサンプル IAM ポリシーで、Resource ARN が指定されています。以下の IAM ポリシーで注目すべきアクションは、PutRuleGroupsNamespace と DeleteRuleGroupsNamespace で、AMP ワークスペースの rulegroupsnamespace の指定された Resource ARN に制限されています。ポリシーが作成されると、必要なアクセス制御要件に応じて、任意のユーザー、グループ、またはロールに割り当てることができます。IAM ポリシーの Action は、必要かつ許可されるアクションに基づいて、IAM アクセス許可に従って必要に応じて変更/制限できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"aps:RemoteWrite",
"aps:DescribeRuleGroupsNamespace",
"aps:PutRuleGroupsNamespace",
"aps:DeleteRuleGroupsNamespace"
],
"Resource": [
"arn:aws:aps:us-west-2:XXXXXXXXXXXX:workspace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx",
"arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops"
]
}
]
}
以下の awscli のやり取りは、IAM ポリシーで Resource ARN を通じて指定された rulegroupsnamespace (つまり devops rulegroupnamespace) への制限付きアクセスを持つ IAM ユーザーの例と、アクセス権を持たない他のリソース (つまり engg rulegroupnamespace) へのアクセスが同じユーザーに対して拒否される様子を示しています。
$ aws amp describe-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name devops
{
"ruleGroupsNamespace": {
"arn": "arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops",
"createdAt": "2023-04-28T01:50:15.408000+00:00",
"data": "Z3JvdXBzOgogIC0gbmFtZTogZGV2b3BzX3VwZGF0ZWQKICAgIHJ1bGVzOgogICAgLSByZWNvcmQ6IG1ldHJpYzpob3N0X2NwdV91dGlsCiAgICAgIGV4cHI6IGF2ZyhyYXRlKGNvbnRhaW5lcl9jcHVfdXNhZ2Vfc2Vjb25kc190b3RhbFsybV0pKQogICAgLSBhbGVydDogaGlnaF9ob3N0X2NwdV91c2FnZQogICAgICBleHByOiBhdmcocmF0ZShjb250YWluZXJfY3B1X3VzYWdlX3NlY29uZHNfdG90YWxbNW1dKSkKICAgICAgZm9yOiA1bQogICAgICBsYWJlbHM6CiAgICAgICAgICAgIHNldmVyaXR5OiBjcml0aWNhbAogIC0gbmFtZTogZGV2b3BzCiAgICBydWxlczoKICAgIC0gcmVjb3JkOiBjb250YWluZXJfbWVtX3V0aWwKICAgICAgZXhwcjogYXZnKHJhdGUoY29udGFpbmVyX21lbV91c2FnZV9ieXRlc190b3RhbFs1bV0pKQogICAgLSBhbGVydDogY29udGFpbmVyX2hvc3RfbWVtX3VzYWdlCiAgICAgIGV4cHI6IGF2ZyhyYXRlKGNvbnRhaW5lcl9tZW1fdXNhZ2VfYnl0ZXNfdG90YWxbNW1dKSkKICAgICAgZm9yOiA1bQogICAgICBsYWJlbHM6CiAgICAgICAgc2V2ZXJpdHk6IGNyaXRpY2FsCg==",
"modifiedAt": "2023-05-01T17:47:06.409000+00:00",
"name": "devops",
"status": {
"statusCode": "ACTIVE",
"statusReason": ""
},
"tags": {}
}
}
$ cat > devops.yaml <<EOF
> groups:
> - name: devops_new
> rules:
> - record: metric:host_cpu_util
> expr: avg(rate(container_cpu_usage_seconds_total[2m]))
> - alert: high_host_cpu_usage
> expr: avg(rate(container_cpu_usage_seconds_total[5m]))
> for: 5m
> labels:
> severity: critical
> - name: devops
> rules:
> - record: container_mem_util
> expr: avg(rate(container_mem_usage_bytes_total[5m]))
> - alert: container_host_mem_usage
> expr: avg(rate(container_mem_usage_bytes_total[5m]))
> for: 5m
> labels:
> severity: critical
> EOF
$ base64 devops.yaml > devops_b64.yaml
$ aws amp put-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name devops --data file://devops_b64.yaml
{
"arn": "arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/devops",
"name": "devops",
"status": {
"statusCode": "UPDATING"
},
"tags": {}
}
$ aws amp describe-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg An error occurred (AccessDeniedException) when calling the DescribeRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:DescribeRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
$ aws amp put-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg --data file://devops_b64.yaml An error occurred (AccessDeniedException) when calling the PutRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:PutRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
$ aws amp delete-rule-groups-namespace --workspace-id ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx --name engg An error occurred (AccessDeniedException) when calling the DeleteRuleGroupsNamespace operation: User: arn:aws:iam::XXXXXXXXXXXX:user/amp_ws_user is not authorized to perform: aps:DeleteRuleGroupsNamespace on resource: arn:aws:aps:us-west-2:XXXXXXXXXXXX:rulegroupsnamespace/ws-8da31ad6-f09d-44ff-93a3-xxxxxxxxxx/engg
ルールを使用するためのユーザー権限は、IAM ポリシーを使用して制限することもできます(ドキュメントのサンプル)。
お客様は、AWS ドキュメントを参照したり、Amazon Managed Service for Prometheus Alert Manager に関する AWS Observability Workshop を実施したりすることで、詳細情報を確認できます。
追加リファレンス: Amazon Managed Service for Prometheus が Alert Manager と Ruler を備えて一般提供開始